









开启服务
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "go语言中文文档www.topgoer.com",
})
})
r.Run(":8080") // listen and serve on 0.0.0.0:8080
}
type Engine struct
// Engine is the framework's instance, it contains the muxer, middleware and configuration settings.
// Create an instance of Engine, by using New() or Default()
type Engine struct {
// 路由组
RouterGroup
// 如果true,当前路由匹配失败但将路径最后的 / 去掉时匹配成功时自动匹配后者
// 比如:请求是 /foo/ 但没有命中,而存在 /foo,
// 对get method请求,客户端会被301重定向到 /foo
// 对于其他method请求,客户端会被307重定向到 /foo
RedirectTrailingSlash bool
// 如果true,在没有处理者被注册来处理当前请求时router将尝试修复当前请求路径
// 逻辑为:
// - 移除前面的 ../ 或者 //
// - 对新的路径进行大小写不敏感的查询
// 如果找到了处理者,请求会被301或307重定向
// 比如: /FOO 和 /..//FOO 会被重定向到 /foo
// RedirectTrailingSlash 参数和这个参数独立
RedirectFixedPath bool
// 如果true,当路由没有被命中时,去检查是否有其他method命中
// 如果命中,响应405 (Method Not Allowed)
// 如果没有命中,请求将由 NotFound handler 来处理
HandleMethodNotAllowed bool
//如果启用了ForwardedByClientIP,客户端IP将从与存储在' (*gin.Engine). remoteipheaders '匹配的请求头中解析。如果没有获取IP,则返回从' (*gin.Context). request . remoteaddr '获取的IP。
ForwardedByClientIP bool
// AppEngine was deprecated.
// Deprecated: USE `TrustedPlatform` WITH VALUE `gin.PlatformGoogleAppEngine` INSTEAD
// #726 #755 If enabled, it will trust some headers starting with
// 'X-AppEngine...' for better integration with that PaaS.
AppEngine bool
// 如果true, url.RawPath 会被用来查找参数
UseRawPath bool
// 如果true, path value 会被保留
// 如果 UseRawPath是false(默认),UnescapePathValues为true
// url.Path会被保留并使用
UnescapePathValues bool
// 即使使用额外的斜杠,参数也可以从URL中解析。
RemoveExtraSlash bool
// RemoteIPHeaders list of headers used to obtain the client IP when
// `(*gin.Engine).ForwardedByClientIP` is `true` and
// `(*gin.Context).Request.RemoteAddr` is matched by at least one of the
// network origins of list defined by `(*gin.Engine).SetTrustedProxies()`.
RemoteIPHeaders []string
// TrustedPlatform if set to a constant of value gin.Platform*, trusts the headers set by
// that platform, for example to determine the client IP
TrustedPlatform string
// MaxMultipartMemory value of 'maxMemory' param that is given to http.Request's ParseMultipartForm
// method call.
MaxMultipartMemory int64
// UseH2C enable h2c support.
UseH2C bool
// ContextWithFallback enable fallback Context.Deadline(), Context.Done(), Context.Err() and Context.Value() when Context.Request.Context() is not nil.
ContextWithFallback bool
delims render.Delims
secureJSONPrefix string
HTMLRender render.HTMLRender
FuncMap template.FuncMap
allNoRoute HandlersChain
allNoMethod HandlersChain
noRoute HandlersChain
noMethod HandlersChain
//这里定义了一个可以临时存取对象的集合(sync.Pool是线程安全的,主要用来缓存为使用的item以减少GC压力,使得创建高效且线程安全的空闲队列)
//HTTP 框架 Gin 用 sync.Pool 来复用每个请 求都会创建的 gin.Context 对象
pool sync.Pool
trees methodTrees
maxParams uint16
maxSections uint16
trustedProxies []string
trustedCIDRs []*net.IPNet
}
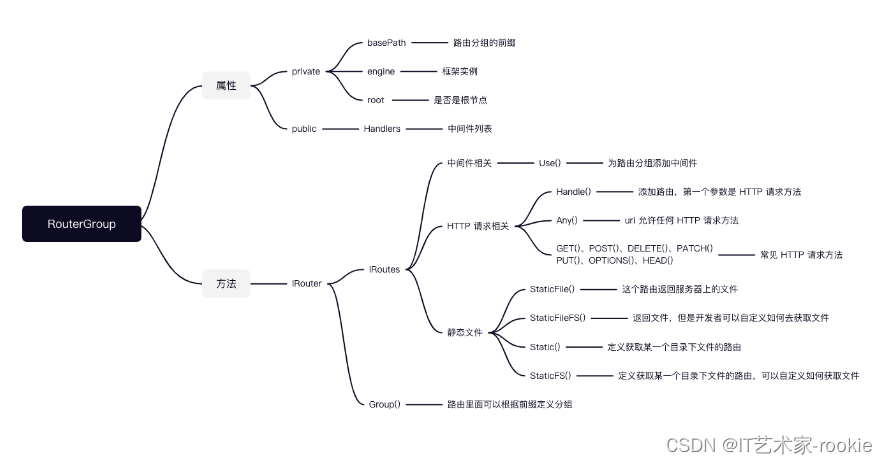
type IRouter interface
// IRouter defines all router handle interface includes single and group router.
type IRouter interface {
IRoutes
Group(string, ...HandlerFunc) *RouterGroup
}
// IRoutes defines all router handle interface.
type IRoutes interface {
Use(...HandlerFunc) IRoutes
Handle(string, string, ...HandlerFunc) IRoutes
Any(string, ...HandlerFunc) IRoutes
GET(string, ...HandlerFunc) IRoutes
POST(string, ...HandlerFunc) IRoutes
DELETE(string, ...HandlerFunc) IRoutes
PATCH(string, ...HandlerFunc) IRoutes
PUT(string, ...HandlerFunc) IRoutes
OPTIONS(string, ...HandlerFunc) IRoutes
HEAD(string, ...HandlerFunc) IRoutes
StaticFile(string, string) IRoutes
StaticFileFS(string, string, http.FileSystem) IRoutes
Static(string, string) IRoutes
StaticFS(string, http.FileSystem) IRoutes
}
RouterGroup
// RouterGroup is used internally to configure router, a RouterGroup is associated with
// a prefix and an array of handlers (middleware).
type RouterGroup struct {
Handlers HandlersChain
basePath string //路由分组前缀
engine *Engine
root bool //是否是根节点
}
// HandlerFunc defines the handler used by gin middleware as return value.
type HandlerFunc func(*Context)
// HandlersChain defines a HandlerFunc slice.
type HandlersChain []HandlerFunc
//这行代码的作用是检查RouterGroup 结构体是否完全实现IRouter接口,IRouter这个interface里面包含的方法太多了,为了防止Engine在实现这些方法的时候出现意外,比如少一个,或者写错,有时候很难发现。。如果没有实现所有接口,RouterGroup 类型的实例就不能赋值给IRouter类型的变量,这行代码会直接编译错误
var _ IRouter = &RouterGroup{}
路由注册
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "go语言中文文档www.topgoer.com",
})
})
func (group *RouterGroup) GET(relativePath string, handlers …HandlerFunc) IRoutes
func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {
return group.handle(http.MethodGet, relativePath, handlers)
}
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers)
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain
就是在group对象的handle数组中加入了当前新注册的handle,但是是通过创建新的数组替换旧的数组来做的。为什么通过这样的方式来更新这个属性话需要研究
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
finalSize := len(group.Handlers) + len(handlers)
assert1(finalSize < int(abortIndex), "too many handlers") //最多注册63个路由
mergedHandlers := make(HandlersChain, finalSize) //新定义的handle数组
copy(mergedHandlers, group.Handlers)
copy(mergedHandlers[len(group.Handlers):], handlers)
return mergedHandlers
}
func (engine *Engine) addRoute(method, path string, handlers HandlersChain)
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
assert1(path[0] == '/', "path must begin with '/'")
assert1(method != "", "HTTP method can not be empty")
assert1(len(handlers) > 0, "there must be at least one handler")
debugPrintRoute(method, path, handlers)
//根据http方法,获取节点的信息,如果返回为空,那么就创建新节点
root := engine.trees.get(method)
if root == nil {
root = new(node) //根节点被创建
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)//向根节点添加子节点
// Update maxParams
if paramsCount := countParams(path); paramsCount > engine.maxParams {
engine.maxParams = paramsCount
}
if sectionsCount := countSections(path); sectionsCount > engine.maxSections {
engine.maxSections = sectionsCount
}
}
func (group *RouterGroup) returnObj() IRoutes
func (group *RouterGroup) returnObj() IRoutes {
if group.root {
return group.engine
}
return group
}
func (n *node) addRoute(path string, handlers HandlersChain)
线程不安全的
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++
// Empty tree
if len(n.path) == 0 && len(n.children) == 0 { //说明路由地址可以为空,但是前提是必须有子节点
n.insertChild(path, fullPath, handlers)//节点数据赋值
n.nType = root
return
}
parentFullPathIndex := 0
walk:
for {
// Find the longest common prefix.
// This also implies that the common prefix contains no ':' or '*'
//返回当前节点,和上一节点的路由不同的起始字符位置
// 当前节点:'/api/ping'与上一节点:'/api/ping2'就会返回'2'的索引9
i := longestCommonPrefix(path, n.path)
// Split edge
if i < len(n.path) {
child := node{
path: n.path[i:],
wildChild: n.wildChild,
nType: static,
indices: n.indices,
children: n.children,
handlers: n.handlers,
priority: n.priority - 1,
fullPath: n.fullPath,
}
n.children = []*node{&child}
// []byte for proper unicode char conversion, see #65
n.indices = bytesconv.BytesToString([]byte{n.path[i]})
n.path = path[:i]
n.handlers = nil
n.wildChild = false
n.fullPath = fullPath[:parentFullPathIndex+i]
}
// Make new node a child of this node
if i < len(path) {
path = path[i:]//返回不同的所有部分字符串
c := path[0]//获取第一个字符
// '/' after param
if n.nType == param && c == '/' && len(n.children) == 1 {
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
continue walk
}
// Check if a child with the next path byte exists
for i, max := 0, len(n.indices); i < max; i++ {
if c == n.indices[i] {
parentFullPathIndex += len(n.path)
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// Otherwise insert it
if c != ':' && c != '*' && n.nType != catchAll {
// 还不清除indices字段干什么的?
n.indices += bytesconv.BytesToString([]byte{c})
child := &node{
fullPath: fullPath,
}
n.addChild(child)//当前节点就被作为上一节点的子节点了
n.incrementChildPrio(len(n.indices) - 1)
n = child
} else if n.wildChild {
// inserting a wildcard node, need to check if it conflicts with the existing wildcard
n = n.children[len(n.children)-1]
n.priority++
// Check if the wildcard matches
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
// Adding a child to a catchAll is not possible
n.nType != catchAll &&
// Check for longer wildcard, e.g. :name and :names
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
continue walk
}
// Wildcard conflict
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(pathSeg, "/", 2)[0]
}
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
n.insertChild(path, fullPath, handlers)
return
}
// Otherwise add handle to current node
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
}
n.handlers = handlers
n.fullPath = fullPath
return
}
}
func (n *node) incrementChildPrio(pos int) int
func (n *node) incrementChildPrio(pos int) int {
cs := n.children
cs[pos].priority++
prio := cs[pos].priority
// Adjust position (move to front)
//priority小的放到前面
newPos := pos
for ; newPos > 0 && cs[newPos-1].priority < prio; newPos-- {
// Swap node positions
cs[newPos-1], cs[newPos] = cs[newPos], cs[newPos-1]
}
// Build new index char string
if newPos != pos {
n.indices = n.indices[:newPos] + // Unchanged prefix, might be empty
n.indices[pos:pos+1] + // The index char we move
n.indices[newPos:pos] + n.indices[pos+1:] // Rest without char at 'pos'
}
return newPos
}
func (n *node) insertChild(path string, fullPath string, handlers HandlersChain)
func (n *node) insertChild(path string, fullPath string, handlers HandlersChain) {
for {
// Find prefix until first wildcard
wildcard, i, valid := findWildcard(path)
if i < 0 { // No wildcard found
break
}
// The wildcard name must only contain one ':' or '*' character
if !valid {
panic("only one wildcard per path segment is allowed, has: '" +
wildcard + "' in path '" + fullPath + "'")
}
// check if the wildcard has a name
if len(wildcard) < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
if wildcard[0] == ':' { // param
if i > 0 {
// Insert prefix before the current wildcard
n.path = path[:i]
path = path[i:]
}
child := &node{
nType: param,
path: wildcard,
fullPath: fullPath,
}
n.addChild(child)
n.wildChild = true
n = child
n.priority++
// if the path doesn't end with the wildcard, then there
// will be another subpath starting with '/'
if len(wildcard) < len(path) {
path = path[len(wildcard):]
child := &node{
priority: 1,
fullPath: fullPath,
}
n.addChild(child)
n = child
continue
}
// Otherwise we're done. Insert the handle in the new leaf
n.handlers = handlers
return
}
// catchAll
if i+len(wildcard) != len(path) {
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
pathSeg := strings.SplitN(n.children[0].path, "/", 2)[0]
panic("catch-all wildcard '" + path +
"' in new path '" + fullPath +
"' conflicts with existing path segment '" + pathSeg +
"' in existing prefix '" + n.path + pathSeg +
"'")
}
// currently fixed width 1 for '/'
i--
if path[i] != '/' {
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[:i]
// First node: catchAll node with empty path
child := &node{
wildChild: true,
nType: catchAll,
fullPath: fullPath,
}
n.addChild(child)
n.indices = string('/')
n = child
n.priority++
// second node: node holding the variable
child = &node{
path: path[i:],
nType: catchAll,
handlers: handlers,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
return
}
// If no wildcard was found, simply insert the path and handle
n.path = path
n.handlers = handlers
n.fullPath = fullPath
}
type methodTree struct
type methodTree struct {
method string
root *node
}
type node struct
代表了一个二叉树结点
type node struct {
path string
indices string//这个字段从表现看,存放了当前节点直接子节点的路由(去掉前缀)首字母(有顺序---路由注册顺序)
wildChild bool
nType nodeType
priority uint32
children []*node // child nodes, at most 1 :param style node at the end of the array
handlers HandlersChain
fullPath string
}
type Pool struct
sync.Pool的主要功能是在需要时提供可重用的对象,并在使用后将其返回到池中。每个sync.Pool实例都包含两个指针,local和victim,用于管理存储在池中的对象。local指向一个大小为[P]poolLocal的数组,其中P是系统中的处理器数。poolLocal结构体用于存储每个处理器专有的池。当一个goroutine需要从池中获取对象时,它首先会检查local指向的poolLocal实例是否有可用的对象。如果有,则该goroutine会从local中获取一个对象。否则,该goroutine会将local指向的poolLocal实例中的所有对象移动到victim中,并将local指向victim。然后,该goroutine会检查victim指向的poolLocal实例是否有可用的对象。如果有,则该goroutine会从victim中获取一个对象。如果没有,则该goroutine会使用New函数创建一个新的对象。
当一个goroutine使用完一个对象时,它会将该对象返回给池。如果当前池中已经有足够多的对象,则该对象会被添加到local指向的poolLocal实例中。否则,该对象会被添加到victim指向的poolLocal实例中。
需要注意的是,sync.Pool并不保证在任何时刻都有可用的对象。当需要从池中获取对象时,如果池中没有可用的对象,则会调用New函数创建一个新的对象。因此,New函数应该返回一个合适的默认值,以避免在每次获取对象时都需要执行昂贵的初始化操作。
Regenerate response
//池是一组临时对象,可以单独保存和检索。
//存储在池中的任何item都可以在不通知的情况下随时自动删除。池持有唯一的引用,如果发生这种情况时,则item可能会被释放。
//一个Pool可以被多个goroutine同时使用。
// Pool的目的是缓存已分配但未使用的item,以供以后重用,减轻垃圾回收器的压力。也就是说,它使构建高效、线程安全的自由列表变得容易。然而,它并不适用于所有的自由列表。
// Pool的适当使用是管理一组临时项,这些临时项在包的并发独立客户端之间静默共享,并可能被重用。Pool提供了一种跨多个客户机分摊分配开销的方法。
//一个很好的使用Pool的例子是在fmt包中,它维护一个动态大小的临时输出缓冲区的存储。存储在负载下(当许多goroutine正在主动打印时)扩展,在静止时收缩。
//另一方面,作为存在时间较短的对象的一部分维护的空闲列表不适合用于Pool,因为在这种情况下开销不能很好地分摊。让这样的对象实现它们自己的空闲列表会更有效。
// A Pool第一次使用后不能复制。
//在Go内存模型的术语中,调用Put(x)“在调用Get返回相同值x之前同步”。类似地,调用New返回x“在调用Get返回相同值x之前同步”。
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
当池中没有可用对象时,可以用于生成新对象的函数
New func() any
}
服务运行
func (engine *Engine) Run(addr …string) (err error)
在原生的golang代码中err = http.ListenAndServe(address, engine.Handler())中我们是一般让 第二个参数直接填nil的。所以原生的在后面就会使用默认的DefaultServeMux。gin使用了自己封装的对象。
// Run attaches the router to a http.Server and starts listening and serving HTTP requests.
// It is a shortcut for http.ListenAndServe(addr, router)
// Note: this method will block the calling goroutine indefinitely unless an error happens.
func (engine *Engine) Run(addr ...string) (err error) {
defer func() { debugPrintError(err) }()
if engine.isUnsafeTrustedProxies() {
debugPrint("[WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.\n" +
"Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.")
}
address := resolveAddress(addr) //端口选择
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine.Handler())
return
}
func resolveAddress(addr []string) string
func resolveAddress(addr []string) string {
switch len(addr) {
case 0:
if port := os.Getenv("PORT"); port != "" {
debugPrint("Environment variable PORT=\"%s\"", port)
return ":" + port
}
debugPrint("Environment variable PORT is undefined. Using port :8080 by default")
return ":8080"
case 1:
return addr[0]
default:
panic("too many parameters")
}
}
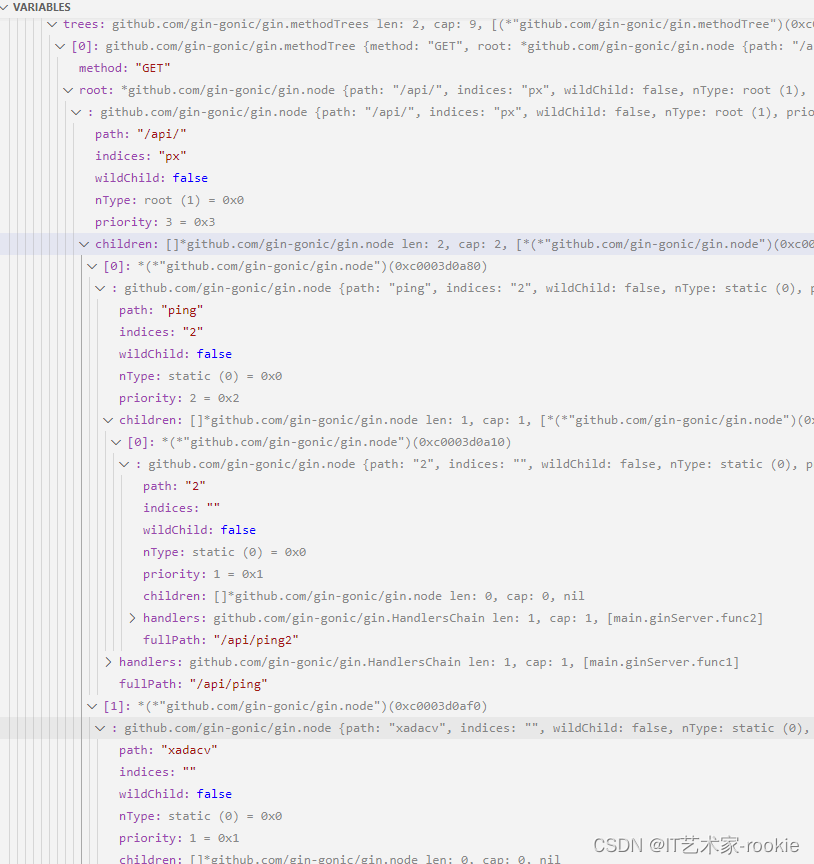
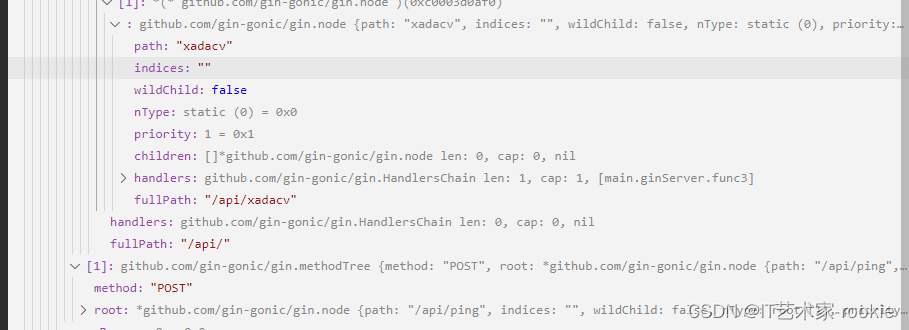
router的二叉树
看样子router的二叉树是以请求方法来区分根节点的。然后同一个请求方法下,路由字符串有重叠的会形成子节
p.engine.trees的内容
请求处理
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context)//从对象池中获取context对象
//这里的c,也就是context上下文对象内容是旧的,所以用当前的更新一下
c.writermem.reset(w)//修改这个context的ResponseWriter
c.Request = req//修改这个context的Request
c.reset()
engine.handleHTTPRequest(c)//处理请求的地方
engine.pool.Put(c)//context对象用完又放回去
}
func (engine *Engine) handleHTTPRequest(c *Context)
func (engine *Engine) handleHTTPRequest(c *Context) {
httpMethod := c.Request.Method
rPath := c.Request.URL.Path
unescape := false
if engine.UseRawPath && len(c.Request.URL.RawPath) > 0 {
rPath = c.Request.URL.RawPath
unescape = engine.UnescapePathValues
}
if engine.RemoveExtraSlash {
rPath = cleanPath(rPath)
}
// Find root of the tree for the given HTTP method
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {//找根节点
continue
}
root := t[i].root//这里就是所有当前请求路由的http方法对应形成的树
// Find route in tree
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
if value.params != nil {
c.Params = *value.params
}
if value.handlers != nil {
c.handlers = value.handlers//将找出的节点信息赋值给当前上下文
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
if httpMethod != http.MethodConnect && rPath != "/" {
if value.tsr && engine.RedirectTrailingSlash {
redirectTrailingSlash(c)
return
}
if engine.RedirectFixedPath && redirectFixedPath(c, root, engine.RedirectFixedPath) {
return
}
}
break
}
if engine.HandleMethodNotAllowed {
for _, tree := range engine.trees {
if tree.method == httpMethod {
continue
}
if value := tree.root.getValue(rPath, nil, c.skippedNodes, unescape); value.handlers != nil {
c.handlers = engine.allNoMethod
serveError(c, http.StatusMethodNotAllowed, default405Body)
return
}
}
}
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}
func (n *node) getValue(path string, params *Params, skippedNodes *[]skippedNode, unescape bool) (value nodeValue)
// 返回用给定路径(键)注册的handle。通配符的值保存到map中。如果找不到handle,如果有handle对给定路径有额外的(不带)尾斜杠,就会提出TSR(尾斜杠重定向)建议。
func (n *node) getValue(path string, params *Params, skippedNodes *[]skippedNode, unescape bool) (value nodeValue) {
var globalParamsCount int16
walk: // Outer loop for walking the tree
for {
prefix := n.path//根节点的路由
//1.判断当前请求是否在该节点下。如果在,前提一定是请求的路由比根节点长
if len(path) > len(prefix) {
//1.1取出当前请求的前缀,看是否真正匹配
if path[:len(prefix)] == prefix {
path = path[len(prefix):]
// 首先通过匹配索引来尝试所有非通配符子元素
idxc := path[0]
for i, c := range []byte(n.indices) {
if c == idxc {
// strings.HasPrefix(n.children[len(n.children)-1].path, ":") == n.wildChild
if n.wildChild {
index := len(*skippedNodes)
*skippedNodes = (*skippedNodes)[:index+1]
(*skippedNodes)[index] = skippedNode{
path: prefix + path,
node: &node{
path: n.path,
wildChild: n.wildChild,
nType: n.nType,
priority: n.priority,
children: n.children,
handlers: n.handlers,
fullPath: n.fullPath,
},
paramsCount: globalParamsCount,
}
}
n = n.children[i]
continue walk
}
}
if !n.wildChild {
// If the path at the end of the loop is not equal to '/' and the current node has no child nodes
// the current node needs to roll back to last valid skippedNode
if path != "/" {
for length := len(*skippedNodes); length > 0; length-- {
skippedNode := (*skippedNodes)[length-1]
*skippedNodes = (*skippedNodes)[:length-1]
if strings.HasSuffix(skippedNode.path, path) {
path = skippedNode.path
n = skippedNode.node
if value.params != nil {
*value.params = (*value.params)[:skippedNode.paramsCount]
}
globalParamsCount = skippedNode.paramsCount
continue walk
}
}
}
// Nothing found.
// We can recommend to redirect to the same URL without a
// trailing slash if a leaf exists for that path.
value.tsr = path == "/" && n.handlers != nil
return
}
// Handle wildcard child, which is always at the end of the array
n = n.children[len(n.children)-1]
globalParamsCount++
switch n.nType {
case param:
// fix truncate the parameter
// tree_test.go line: 204
// Find param end (either '/' or path end)
end := 0
for end < len(path) && path[end] != '/' {
end++
}
// Save param value
if params != nil && cap(*params) > 0 {
if value.params == nil {
value.params = params
}
// Expand slice within preallocated capacity
i := len(*value.params)
*value.params = (*value.params)[:i+1]
val := path[:end]
if unescape {
if v, err := url.QueryUnescape(val); err == nil {
val = v
}
}
(*value.params)[i] = Param{
Key: n.path[1:],
Value: val,
}
}
// we need to go deeper!
if end < len(path) {
if len(n.children) > 0 {
path = path[end:]
n = n.children[0]
continue walk
}
// ... but we can't
value.tsr = len(path) == end+1
return
}
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
if len(n.children) == 1 {
// No handle found. Check if a handle for this path + a
// trailing slash exists for TSR recommendation
n = n.children[0]
value.tsr = (n.path == "/" && n.handlers != nil) || (n.path == "" && n.indices == "/")
}
return
case catchAll:
// Save param value
if params != nil {
if value.params == nil {
value.params = params
}
// Expand slice within preallocated capacity
i := len(*value.params)
*value.params = (*value.params)[:i+1]
val := path
if unescape {
if v, err := url.QueryUnescape(path); err == nil {
val = v
}
}
(*value.params)[i] = Param{
Key: n.path[2:],
Value: val,
}
}
value.handlers = n.handlers
value.fullPath = n.fullPath
return
default:
panic("invalid node type")
}
}
}
if path == prefix {
// 如果当前路径不等于'/',且节点没有注册句柄,且最近匹配的节点有子节点,则当前节点需要回滚到最后一个有效的skippedNode
if n.handlers == nil && path != "/" {
for length := len(*skippedNodes); length > 0; length-- {
skippedNode := (*skippedNodes)[length-1]
*skippedNodes = (*skippedNodes)[:length-1]
if strings.HasSuffix(skippedNode.path, path) {
path = skippedNode.path
n = skippedNode.node
if value.params != nil {
*value.params = (*value.params)[:skippedNode.paramsCount]
}
globalParamsCount = skippedNode.paramsCount
continue walk
}
}
// n = latestNode.children[len(latestNode.children)-1]
}
// 我们应该已经到达包含handle的节点。
//检查该节点是否注册了handle。
//这里可以找出该请求的节点信息
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
// If there is no handle for this route, but this route has a
// wildcard child, there must be a handle for this path with an
// additional trailing slash
if path == "/" && n.wildChild && n.nType != root {
value.tsr = true
return
}
if path == "/" && n.nType == static {
value.tsr = true
return
}
// No handle found. Check if a handle for this path + a
// trailing slash exists for trailing slash recommendation
for i, c := range []byte(n.indices) {
if c == '/' {
n = n.children[i]
value.tsr = (len(n.path) == 1 && n.handlers != nil) ||
(n.nType == catchAll && n.children[0].handlers != nil)
return
}
}
return
}
// Nothing found. We can recommend to redirect to the same URL with an
// extra trailing slash if a leaf exists for that path
value.tsr = path == "/" ||
(len(prefix) == len(path)+1 && prefix[len(path)] == '/' &&
path == prefix[:len(prefix)-1] && n.handlers != nil)
// roll back to last valid skippedNode
if !value.tsr && path != "/" {
for length := len(*skippedNodes); length > 0; length-- {
skippedNode := (*skippedNodes)[length-1]
*skippedNodes = (*skippedNodes)[:length-1]
if strings.HasSuffix(skippedNode.path, path) {
path = skippedNode.path
n = skippedNode.node
if value.params != nil {
*value.params = (*value.params)[:skippedNode.paramsCount]
}
globalParamsCount = skippedNode.paramsCount
continue walk
}
}
}
return
}
}
func (c *Context) Next()
Next应该只在中间件中使用。它在调用处理程序内部执行链中的挂起处理程序。如果有中间件,那么每个节点的handles都是中间件由自己拥有的中间件加上一个自己的请求处理函数
func (c *Context) Next() {
c.index++
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)//这里将上下文传递给节点的中间件和处理函数handle,并且开始执行中间件和处理函数
c.index++
}
}
还有不少细节和其他场景没有进一步分析,持续更新















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









