







前言
本文是 《Redis 数据结构》合集的第三篇文章,建议大家从第一篇文章开始阅读这样效果更好:
-
揭秘Redis哈希底层实现
-
揭秘Redis集合底层实现
-
机密Redis有序列表底层实现
列表对象
列表对象的编码可以是 ziplist 或者 linkedlist 。
ziplist 编码
ziplist 编码的列表对象使用压缩列表作为底层实现, 每个压缩列表节点(entry)保存了一个列表元素。
redis> RPUSH blah "hello" "world" "again"
(integer) 3
redis> OBJECT ENCODING blah
"ziplist"
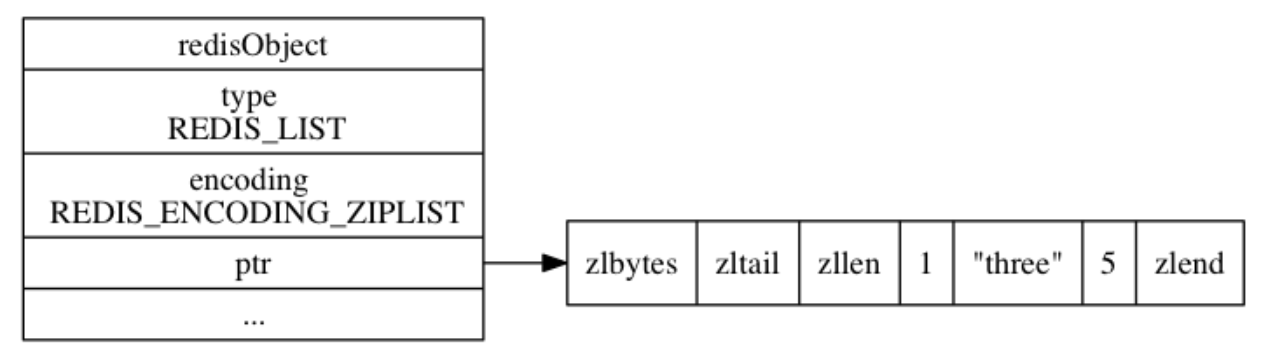
linkedlist 编码
linkedlist 编码的列表对象使用双端链表作为底层实现, 每个双端链表节点(node)都保存了一个字符串对象, 而每个字符串对象都保存了一个列表元素。
# 将一个 65 字节长的元素推入列表对象中
redis> RPUSH blah "wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww"
(integer) 4
# 编码已改变
redis> OBJECT ENCODING blah
"linkedlist"
编码转换
当列表对象可以同时满足以下两个条件时, 列表对象使用 ziplist 编码:
- 列表对象保存的所有字符串元素的长度都小于 64 字节;
- 列表对象保存的元素数量小于 512 个;
不能满足这两个条件的列表对象需要使用 linkedlist 编码。
对于使用 ziplist 编码的列表对象来说, 当使用 ziplist 编码所需的两个条件的任意一个不能被满足时, 对象的编码转换操作就会被执行: 原本保存在压缩列表里的所有列表元素都会被转移并保存到双端链表里面, 对象的编码也会从 ziplist 变为 linkedlist 。
因为保存了长度太大的元素而进行编码转换的情况:
# 所有元素的长度都小于 64 字节
redis> RPUSH blah "hello" "world" "again"
(integer) 3
redis> OBJECT ENCODING blah
"ziplist"
# 将一个 65 字节长的元素推入列表对象中
redis> RPUSH blah "wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww"
(integer) 4
# 编码已改变
redis> OBJECT ENCODING blah
"linkedlist"
列表对象因为保存的元素数量过多而进行编码转换的情况:
# 列表对象包含 512 个元素
redis> EVAL "for i=1,512 do redis.call('RPUSH', KEYS[1], i) end" 1 "integers"
(nil)
redis> LLEN integers
(integer) 512
redis> OBJECT ENCODING integers
"ziplist"
# 再向列表对象推入一个新元素,使得对象保存的元素数量达到 513 个
redis> RPUSH integers 513
(integer) 513
# 编码已改变
redis> OBJECT ENCODING integers
"linkedlist"
ziplist 实现
ziplist结构
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
一个压缩列表可以包含任意多个节点(entry), 每个节点可以保存一个字节数组或者一个整数值。

压缩列表各个组成部分的详细说明:
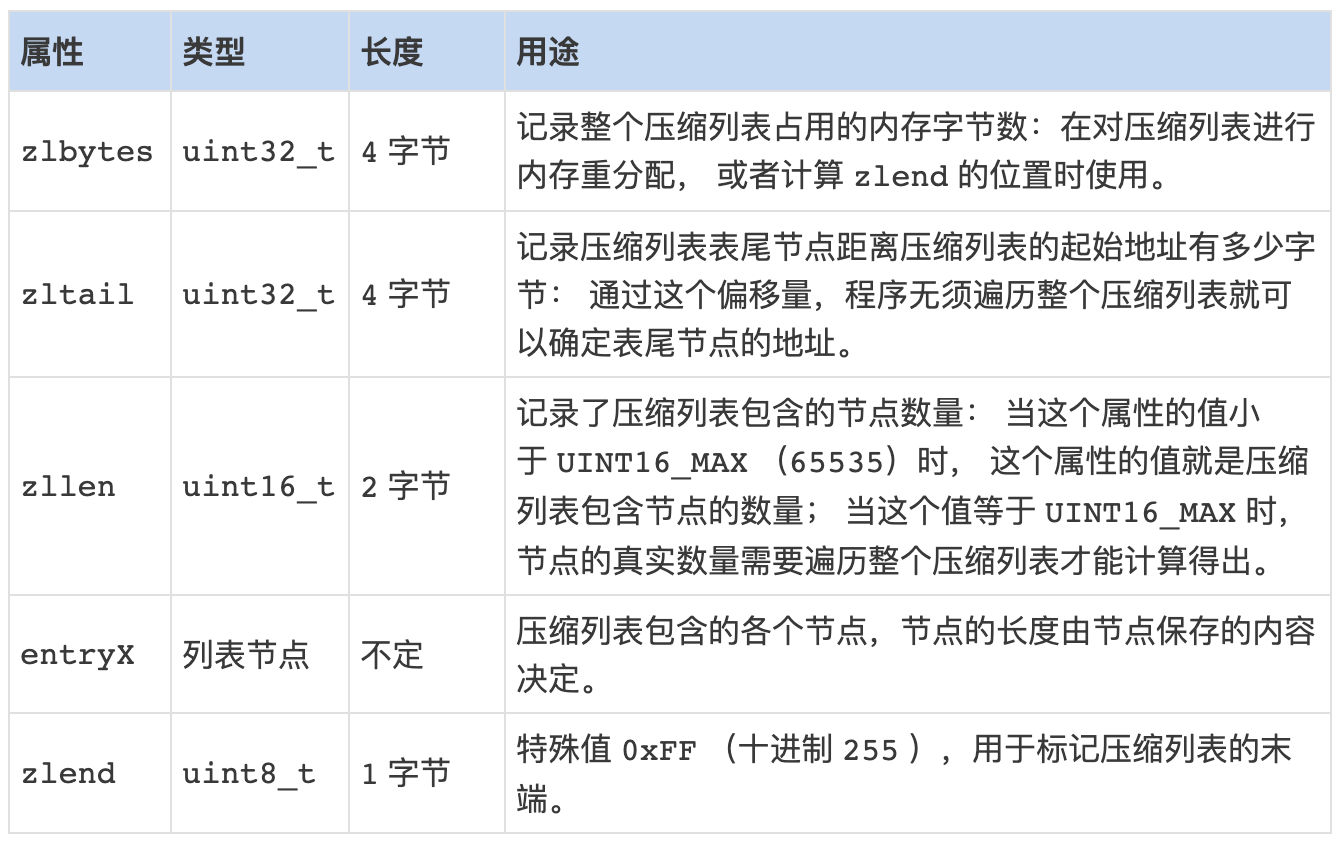
在Redis中并没有定义ziplist的数据结构,ziplist只不过是一段连续的内存块。
// 定位到 ziplist 的 bytes 属性,该属性记录了整个 ziplist 所占用的内存字节数
// 用于取出 bytes 属性的现有值,或者为 bytes 属性赋予新值
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 定位到 ziplist 的 offset 属性,该属性记录了到达表尾节点的偏移量
// 用于取出 offset 属性的现有值,或者为 offset 属性赋予新值
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 定位到 ziplist 的 length 属性,该属性记录了 ziplist 包含的节点数量
// 用于取出 length 属性的现有值,或者为 length 属性赋予新值
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// 返回 ziplist 表头的大小
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// ziplist 末端标识符
#define ZIP_END 255
/* Create a new empty ziplist.
*
* 创建并返回一个新的 ziplist
*
* T = O(1)
*/
unsigned char *ziplistNew(void) {
// ZIPLIST_HEADER_SIZE 是 ziplist 表头的大小
// 1 字节是表末端 ZIP_END 的大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
// 为表头和表末端分配空间
unsigned char *zl = zmalloc(bytes);
// 初始化表属性
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
// 设置表末端
zl[bytes-1] = ZIP_END;
return zl;
}
压缩列表节点
每个压缩列表节点都由 previous_entry_length 、 encoding 、 content 三个部分组成。

previous_entry_length 属性
节点的 previous_entry_length 属性以字节为单位, 记录了压缩列表中前一个节点的长度。
previous_entry_length 属性的长度可以是 1 字节或者 5 字节:
-
如果前一节点的长度小于 254 字节, 那么 previous_entry_length 属性的长度为 1 字节: 前一节点的长度就保存在这一个字节里面。
-
如果前一节点的长度大于等于 254 字节, 那么 previous_entry_length 属性的长度为 5 字节: 其中属性的第一字节会被设置为 0xFE (十进制值 254), 而之后的四个字节则用于保存前一节点的长度。


/* Encode the length of the previous entry and write it to "p". Return the
* number of bytes needed to encode this length if "p" is NULL.
*
* 对前置节点的长度 len 进行编码,并将它写入到 p 中,
* 然后返回编码 len 所需的字节数量。
*
* 如果 p 为 NULL ,那么不进行写入,仅返回编码 len 所需的字节数量。
*
* T = O(1)
*/
static unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len) {
// 仅返回编码 len 所需的字节数量
if (p == NULL) {
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1;
// 写入并返回编码 len 所需的字节数量
} else {
// 1 字节
if (len < ZIP_BIGLEN) {
p[0] = len;
return 1;
// 5 字节
} else {
// 添加 5 字节长度标识
p[0] = ZIP_BIGLEN;
// 写入编码
memcpy(p+1,&len,sizeof(len));
// 如果有必要的话,进行大小端转换
memrev32ifbe(p+1);
// 返回编码长度
return 1+sizeof(len);
}
}
}
因为节点的 previous_entry_length 属性记录了前一个节点的长度, 所以程序可以通过指针运算, 根据当前节点的起始地址来计算出前一个节点的起始地址。
从表尾节点向表头节点进行遍历的完整过程:
-
首先,我们拥有指向压缩列表表尾节点 entry4 起始地址的指针 p1 (指向表尾节点的指针可以通过指向压缩列表起始地址的指针加上 zltail 属性的值得出);

-
通过用 p1 减去 entry4 节点 previous_entry_length 属性的值, 我们得到一个指向 entry4 前一节点 entry3 起始地址的指针 p2 ;

-
通过用 p2 减去 entry3 节点 previous_entry_length 属性的值, 我们得到一个指向 entry3 前一节点 entry2 起始地址的指针 p3 ;
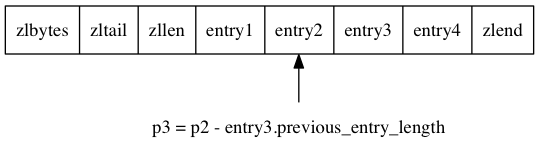
-
通过用 p3 减去 entry2 节点 previous_entry_length 属性的值, 我们得到一个指向 entry2 前一节点 entry1 起始地址的指针 p4 , entry1 为压缩列表的表头节点;
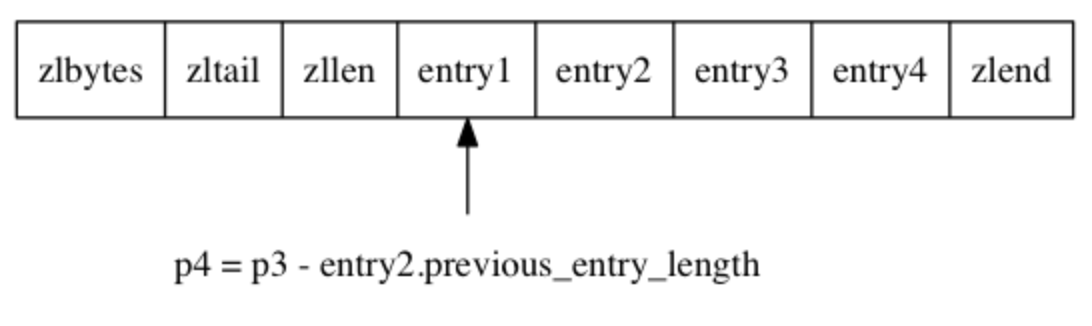
最终, 我们从表尾节点向表头节点遍历了整个列表。
encoding 属性
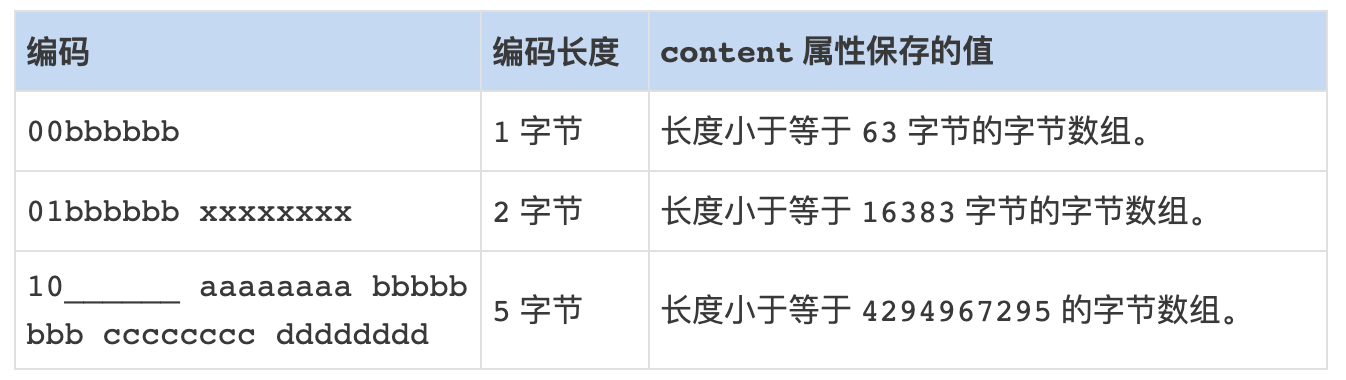
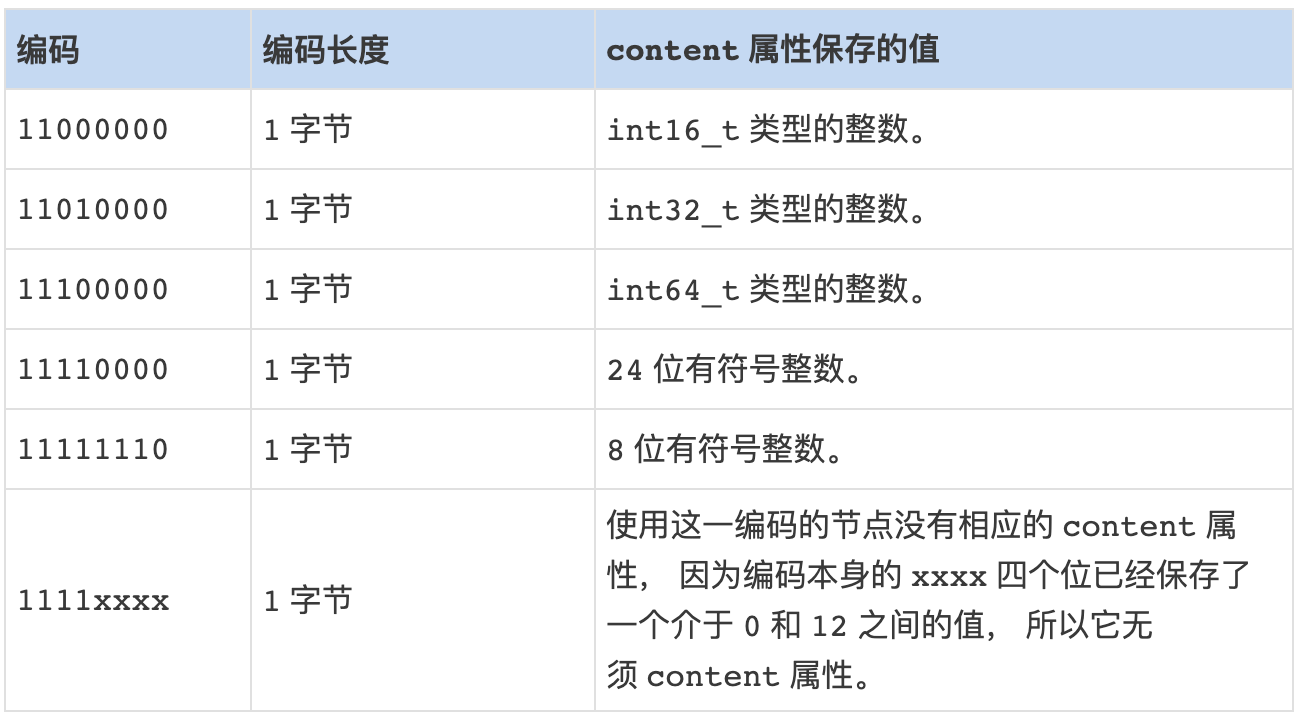
节点的 encoding 属性记录了节点的 content 属性所保存数据的类型以及长度:
-
一字节、两字节或者五字节长, 值的最高位为 00 、 01 或者 10 的是字节数组编码: 这种编码表示节点的 content 属性保存着字节数组, 数组的长度由编码除去最高两位之后的其他位记录;
-
一字节长, 值的最高位以 11 开头的是整数编码: 这种编码表示节点的 content 属性保存着整数值, 整数值的类型和长度由编码除去最高两位之后的其他位记录;
字节数组编码:
整数编码:
content
节点的 content 属性负责保存节点的值, 节点值可以是一个字节数组或者整数, 值的类型和长度由节点的 encoding 属性决定。
保存字节数组的节点示例:
- 编码的最高两位 00 表示节点保存的是一个字节数组;
- 编码的后六位 001011 记录了字节数组的长度 11 ;
- content 属性保存着节点的值 “hello world” 。

保存整数值的节点示例:
- 编码 11000000 表示节点保存的是一个 int16_t 类型的整数值;
- content 属性保存着节点的值 10086 。

连锁更新
前面说过, 每个节点的 previous_entry_length 属性都记录了前一个节点的长度:
-
如果前一节点的长度小于 254 字节, 那么 previous_entry_length 属性需要用 1 字节长的空间来保存这个长度值。
-
如果前一节点的长度大于等于 254 字节, 那么 previous_entry_length 属性需要用 5 字节长的空间来保存这个长度值。
现在一个压缩列表中, 有多个连续的、长度介于 250 字节到 253 字节之间的节点 e1 至 eN , 如图 所示。

因为 e1 至 eN 的所有节点的长度都小于 254 字节, 所以记录这些节点的长度只需要 1 字节长的 previous_entry_length 属性, 换句话说, e1 至 eN 的所有节点的 previous_entry_length 属性都是 1 字节长的。
这时, 如果我们将一个长度大于等于 254 字节的新节点 new 设置为压缩列表的表头节点, 那么 new 将成为 e1 的前置节点, 如图所示。
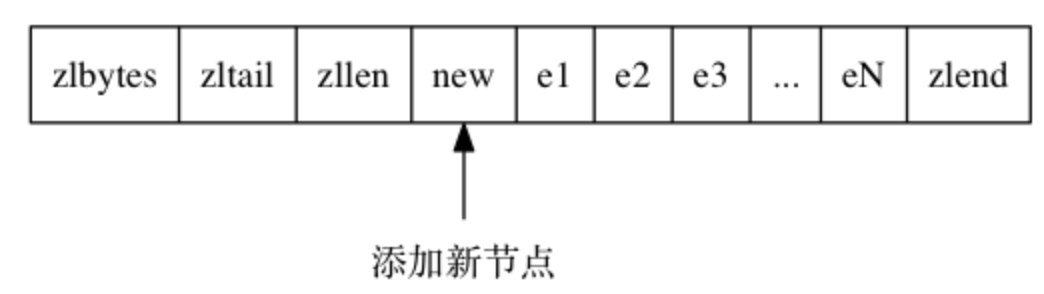
-
因为 e1 的 previous_entry_length 属性仅长 1 字节, 它没办法保存新节点 new 的长度, 所以程序将对压缩列表执行空间重分配操作, 并将 e1 节点的 previous_entry_length 属性从原来的 1 字节长扩展为 5 字节长。
-
e1 原本的长度介于 250 字节至 253 字节之间, 在为 previous_entry_length 属性新增四个字节的空间之后, e1 的长度就变成了介于 254 字节至 257 字节之间, 而这种长度使用 1 字节长的 previous_entry_length 属性是没办法保存的。
-
因此, 为了让 e2 的 previous_entry_length 属性可以记录下 e1 的长度, 程序需要再次对压缩列表执行空间重分配操作, 并将 e2 节点的 previous_entry_length 属性从原来的 1 字节长扩展为 5 字节长。
-
正如扩展 e1 引发了对 e2 的扩展一样, 扩展 e2 也会引发对 e3 的扩展, 而扩展 e3 又会引发对 e4 的扩展……为了让每个节点的 previous_entry_length 属性都符合压缩列表对节点的要求, 程序需要不断地对压缩列表执行空间重分配操作, 直到 eN 为止。
除了添加新节点可能会引发连锁更新之外, 删除节点也可能会引发连锁更新。
因为连锁更新在最坏情况下需要对压缩列表执行 N 次空间重分配操作, 而每次空间重分配的最坏复杂度为 O(N) , 所以连锁更新的最坏复杂度为 O(N^2) 。
linkedlist 实现
链表在 Redis 中的应用非常广泛, 比如列表键的底层实现之一就是链表: 当一个列表键包含了数量比较多的元素, 又或者列表中包含的元素都是比较长的字符串时, Redis 就会使用链表作为列表键的底层实现。
除了链表键之外, 发布与订阅、慢查询、监视器等功能也用到了链表, Redis 服务器本身还使用链表来保存多个客户端的状态信息, 以及使用链表来构建客户端输出缓冲区(output buffer)。
list 结构
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
} list;
listNode 结构
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
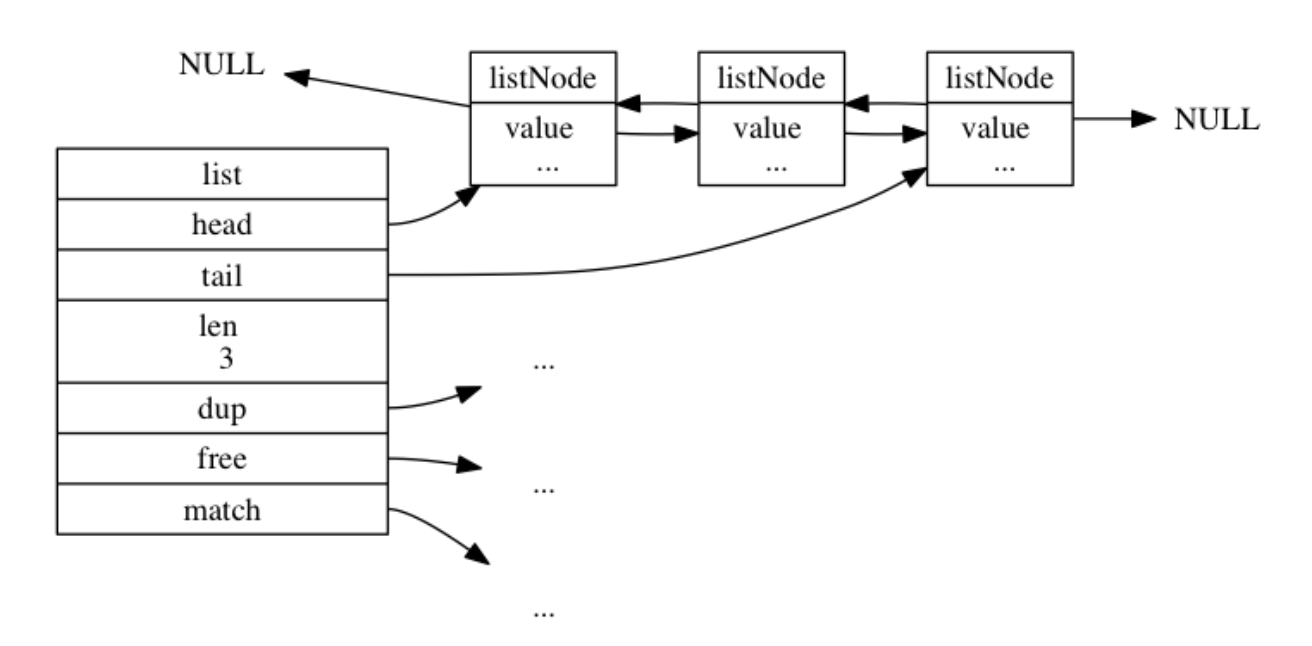
Redis 的链表实现的特性可以总结如下:
-
双端: 链表节点带有 prev 和 next 指针, 获取某个节点的前置节点和后置节点的复杂度都是 O(1) 。
-
无环: 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL , 对链表的访问以 NULL 为终点。
-
带表头指针和表尾指针: 通过 list 结构的 head 指针和 tail 指针, 程序获取链表的表头节点和表尾节点的复杂度为 O(1) 。
-
带链表长度计数器: 程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数, 程序获取链表中节点数量的复杂度为 O(1) 。
-
多态: 链表节点使用 void* 指针来保存节点值, 并且可以通过 list 结构的 dup 、 free 、 match 三个属性为节点值设置类型特定函数, 所以链表可以用于保存各种不同类型的值。
列表对象API源码
Redis 的双端链表实现:adlist.h 和 adlist.c
列表键的实现:t_list.c
添加元素
/* 将给定元素添加到列表的表头或表尾。
*
* 参数 where 决定了新元素添加的位置:
*
* - REDIS_HEAD 将新元素添加到表头
*
* - REDIS_TAIL 将新元素添加到表尾
*
* 调用者无须担心 value 的引用计数,因为这个函数会负责这方面的工作。
*/
void listTypePush(robj *subject, robj *value, int where) {
/* Check if we need to convert the ziplist */
// 是否需要转换编码?
listTypeTryConversion(subject,value);
if (subject->encoding == REDIS_ENCODING_ZIPLIST &&
ziplistLen(subject->ptr) >= server.list_max_ziplist_entries)
listTypeConvert(subject,REDIS_ENCODING_LINKEDLIST);
// ZIPLIST
if (subject->encoding == REDIS_ENCODING_ZIPLIST) {
int pos = (where == REDIS_HEAD) ? ZIPLIST_HEAD : ZIPLIST_TAIL;
// 取出对象的值,因为 ZIPLIST 只能保存字符串或整数
value = getDecodedObject(value);
subject->ptr = ziplistPush(subject->ptr,value->ptr,sdslen(value->ptr),pos);
decrRefCount(value);
// 双端链表
} else if (subject->encoding == REDIS_ENCODING_LINKEDLIST) {
if (where == REDIS_HEAD) {
listAddNodeHead(subject->ptr,value);
} else {
listAddNodeTail(subject->ptr,value);
}
incrRefCount(value);
// 未知编码
} else {
redisPanic("Unknown list encoding");
}
}
ziplist 插入节点
/*
* 根据指针 p 所指定的位置,将长度为 slen 的字符串 s 插入到 zl 中。
*
* 函数的返回值为完成插入操作之后的 ziplist
*
* T = O(N^2)
*/
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
// 记录当前 ziplist 的长度
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry entry, tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
// 如果 p[0] 不指向列表末端,说明列表非空,并且 p 正指向列表的其中一个节点
// 那么取出 p 所指向节点的信息,并将它保存到 entry 结构中
// 然后用 prevlen 变量记录前置节点的长度
// (当插入新节点之后 p 所指向的节点就成了新节点的前置节点)
// T = O(1)
entry = zipEntry(p);
prevlen = entry.prevrawlen;
} else {
// 如果 p 指向表尾末端,那么程序需要检查列表是否为:
// 1)如果 ptail 也指向 ZIP_END ,那么列表为空;
// 2)如果列表不为空,那么 ptail 将指向列表的最后一个节点。
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
// 表尾节点为新节点的前置节点
// 取出表尾节点的长度
// T = O(1)
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
// 尝试看能否将输入字符串转换为整数,如果成功的话:
// 1)value 将保存转换后的整数值
// 2)encoding 则保存适用于 value 的编码方式
// 无论使用什么编码, reqlen 都保存节点值的长度
// T = O(N)
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
// 计算编码前置节点的长度所需的大小
// T = O(1)
reqlen += zipPrevEncodeLength(NULL,prevlen);
// 计算编码当前节点值所需的大小
// T = O(1)
reqlen += zipEncodeLength(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
// 只要新节点不是被添加到列表末端,
// 那么程序就需要检查看 p 所指向的节点(的 header)能否编码新节点的长度。
// nextdiff 保存了新旧编码之间的字节大小差,如果这个值大于 0
// 那么说明需要对 p 所指向的节点(的 header )进行扩展
// T = O(1)
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
/* Store offset because a realloc may change the address of zl. */
// 因为重分配空间可能会改变 zl 的地址
// 所以在分配之前,需要记录 zl 到 p 的偏移量,然后在分配之后依靠偏移量还原 p
offset = p-zl;
// curlen 是 ziplist 原来的长度
// reqlen 是整个新节点的长度
// nextdiff 是新节点的后继节点扩展 header 的长度(要么 0 字节,要么 4 个字节)
// T = O(N)
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) {
// 新元素之后还有节点,因为新元素的加入,需要对这些原有节点进行调整
/* Subtract one because of the ZIP_END bytes */
// 移动现有元素,为新元素的插入空间腾出位置
// T = O(N)
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
// 将新节点的长度编码至后置节点
// p+reqlen 定位到后置节点
// reqlen 是新节点的长度
// T = O(1)
zipPrevEncodeLength(p+reqlen,reqlen);
/* Update offset for tail */
// 更新到达表尾的偏移量,将新节点的长度也算上
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
// 如果新节点的后面有多于一个节点
// 那么程序需要将 nextdiff 记录的字节数也计算到表尾偏移量中
// 这样才能让表尾偏移量正确对齐表尾节点
// T = O(1)
tail = zipEntry(p+reqlen);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
// 新元素是新的表尾节点
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
// 当 nextdiff != 0 时,新节点的后继节点的(header 部分)长度已经被改变,
// 所以需要级联地更新后续的节点
if (nextdiff != 0) {
offset = p-zl;
// T = O(N^2)
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
// 一切搞定,将前置节点的长度写入新节点的 header
p += zipPrevEncodeLength(p,prevlen);
// 将节点值的长度写入新节点的 header
p += zipEncodeLength(p,encoding,slen);
// 写入节点值
if (ZIP_IS_STR(encoding)) {
// T = O(N)
memcpy(p,s,slen);
} else {
// T = O(1)
zipSaveInteger(p,value,encoding);
}
// 更新列表的节点数量计数器
// T = O(1)
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
ziplist 删除节点
/* Delete "num" entries, starting at "p". Returns pointer to the ziplist.
*
* 从位置 p 开始,连续删除 num 个节点。
*
* 函数的返回值为处理删除操作之后的 ziplist 。
*
* T = O(N^2)
*/
static unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
unsigned int i, totlen, deleted = 0;
size_t offset;
int nextdiff = 0;
zlentry first, tail;
// 计算被删除节点总共占用的内存字节数
// 以及被删除节点的总个数
// T = O(N)
first = zipEntry(p);
for (i = 0; p[0] != ZIP_END && i < num; i++) {
p += zipRawEntryLength(p);
deleted++;
}
// totlen 是所有被删除节点总共占用的内存字节数
totlen = p-first.p;
if (totlen > 0) {
if (p[0] != ZIP_END) {
// 执行这里,表示被删除节点之后仍然有节点存在
/* Storing `prevrawlen` in this entry may increase or decrease the
* number of bytes required compare to the current `prevrawlen`.
* There always is room to store this, because it was previously
* stored by an entry that is now being deleted. */
// 因为位于被删除范围之后的第一个节点的 header 部分的大小
// 可能容纳不了新的前置节点,所以需要计算新旧前置节点之间的字节数差
// T = O(1)
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen);
// 如果有需要的话,将指针 p 后退 nextdiff 字节,为新 header 空出空间
p -= nextdiff;
// 将 first 的前置节点的长度编码至 p 中
// T = O(1)
zipPrevEncodeLength(p,first.prevrawlen);
/* Update offset for tail */
// 更新到达表尾的偏移量
// T = O(1)
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
// 如果被删除节点之后,有多于一个节点
// 那么程序需要将 nextdiff 记录的字节数也计算到表尾偏移量中
// 这样才能让表尾偏移量正确对齐表尾节点
// T = O(1)
tail = zipEntry(p);
if (p[tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
/* Move tail to the front of the ziplist */
// 从表尾向表头移动数据,覆盖被删除节点的数据
// T = O(N)
memmove(first.p,p,
intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
} else {
// 执行这里,表示被删除节点之后已经没有其他节点了
/* The entire tail was deleted. No need to move memory. */
// T = O(1)
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe((first.p-zl)-first.prevrawlen);
}
/* Resize and update length */
// 缩小并更新 ziplist 的长度
offset = first.p-zl;
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff);
ZIPLIST_INCR_LENGTH(zl,-deleted);
p = zl+offset;
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
// 如果 p 所指向的节点的大小已经变更,那么进行级联更新
// 检查 p 之后的所有节点是否符合 ziplist 的编码要求
// T = O(N^2)
if (nextdiff != 0)
zl = __ziplistCascadeUpdate(zl,p);
}
return zl;
}















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









