







前言
本文是 《Redis 数据结构》合集的第四篇文章,建议大家从第一篇文章开始阅读这样效果更好:
-
揭秘Redis哈希表底层实现
-
揭秘Redis集合底层实现
-
机密Redis有序列表底层实现
哈希对象
哈希对象的编码可以是 ziplist 或者 hashtable 。
ziplist 编码
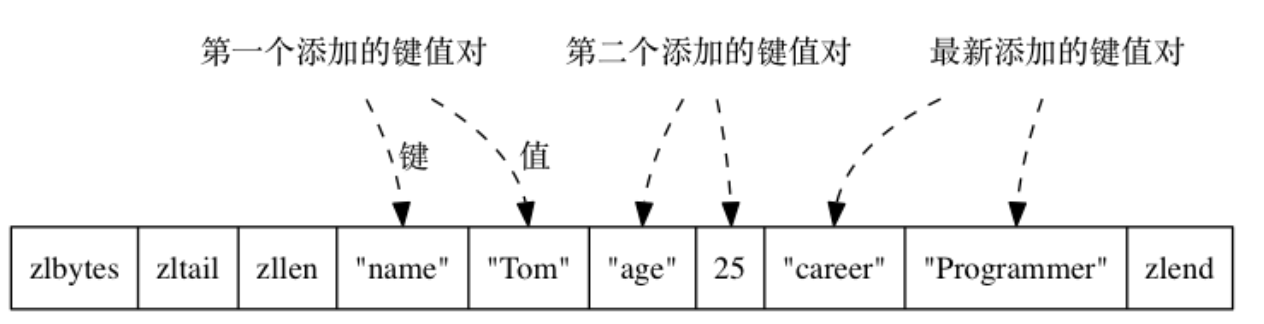
ziplist 编码的哈希对象使用压缩列表作为底层实现, 每当有新的键值对要加入到哈希对象时, 程序会先将保存了键的压缩列表节点推入到压缩列表表尾, 然后再将保存了值的压缩列表节点推入到压缩列表表尾, 因此:
- 保存了同一键值对的两个节点总是紧挨在一起, 保存键的节点在前, 保存值的节点在后;
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向, 而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
redis> HSET profile name "Tom"
(integer) 1
redis> HSET profile age 25
(integer) 1
redis> HSET profile career "Programmer"
(integer) 1
ziplist 编码的 hash 对象的内存布局如下:
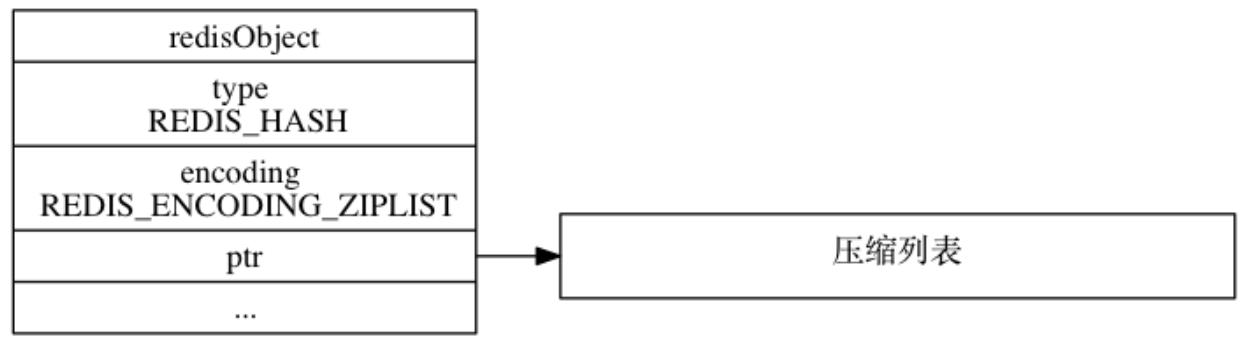
在《揭秘Redis列表底层实现》中介绍过压缩列表,与列表对象中的压缩列表不同的是哈希对象的压缩列表是按 k->v->k-v 的方式连续的排列子压缩列表中:
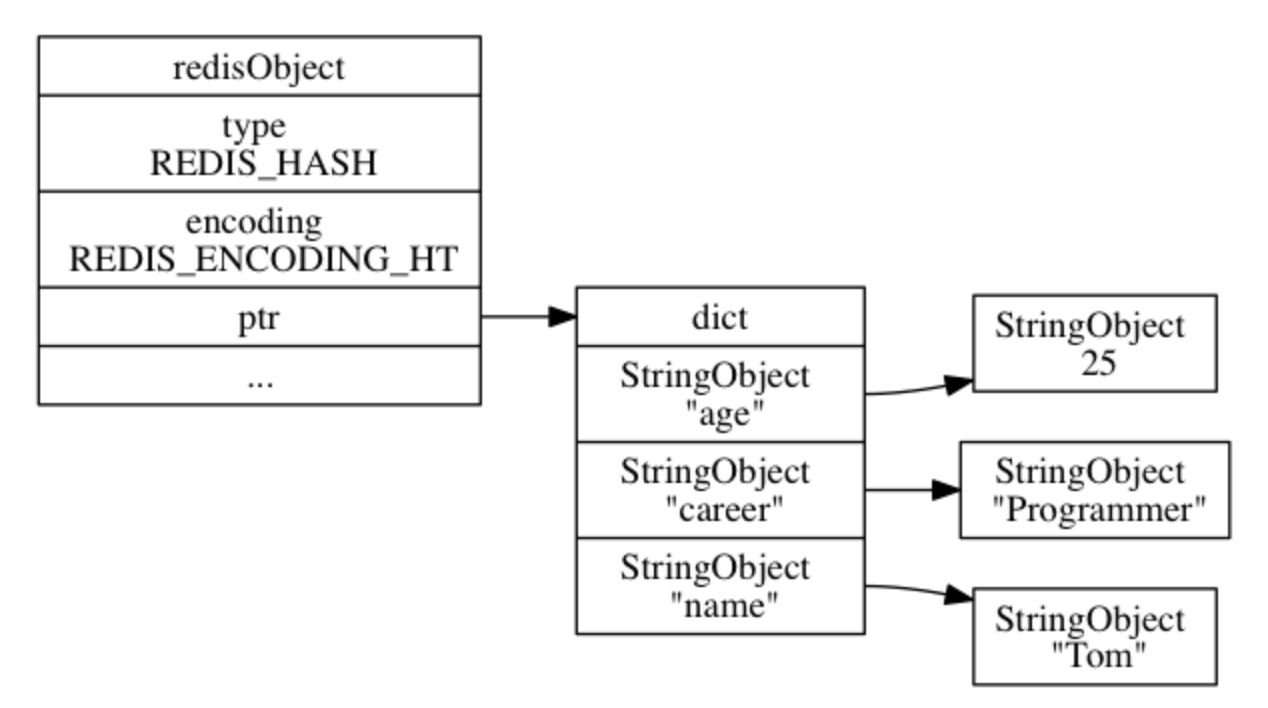
hashtable 编码
hashtable 编码的哈希对象使用字典作为底层实现, 哈希对象中的每个键值对都使用一个字典键值对来保存:
字典的每个键都是一个字符串对象, 对象中保存了键值对的键;
字典的每个值都是一个字符串对象, 对象中保存了键值对的值。
编码转换
当哈希对象可以同时满足以下两个条件时, 哈希对象使用 ziplist 编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节;
- 哈希对象保存的键值对数量小于 512 个;
不能满足这两个条件的哈希对象需要使用 hashtable 编码。
# 哈希对象只包含一个键和值都不超过 64 个字节的键值对
redis> HSET blah greeting "hello world"
(integer) 1
redis> OBJECT ENCODING blah
"ziplist"
# 向哈希对象添加一个新的键值对,值的长度为 68 字节
redis> HSET blah story "many string ... many string ... many string ... many string ... many"
(integer) 1
# 编码已改变
redis> OBJECT ENCODING blah
"hashtable"
字典
字典在 Redis 中的应用相当广泛, 比如 Redis 的数据库就是使用字典来作为底层实现的, 对数据库的增、删、查、改操作也是构建在对字典的操作之上的。
除了用来表示数据库之外, 字典还是哈希键的底层实现之一: 当一个哈希键包含的键值对比较多, 又或者键值对中的元素都是比较长的字符串时, Redis 就会使用字典作为哈希键的底层实现。
在字典中, 一个键(key)可以和一个值(value)进行关联(或者说将键映射为值), 这些关联的键和值就被称为键值对。
字典中的每个键都是独一无二的, 程序可以在字典中根据键查找与之关联的值, 或者通过键来更新值, 又或者根据键来删除整个键值对, 等等。
字典结构
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
type 属性和 privdata 属性是针对不同类型的键值对, 为创建多态字典而设置的。每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
- ht 属性是一个包含两个项的数组, 数组中的每个项都是一个 dictht 哈希表, 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
- 除了 ht[1] 之外, 另一个和 rehash 有关的属性就是 rehashidx : 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 -1 。
哈希表结构
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
- table 属性是一个数组, 数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针, 每个 dictEntry 结构保存着一个键值对。
- size 属性记录了哈希表的大小, 也即是 table 数组的大小, 而 used 属性则记录了哈希表目前已有节点(键值对)的数量。
- sizemask 属性的值总是等于 size - 1 , 这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面。
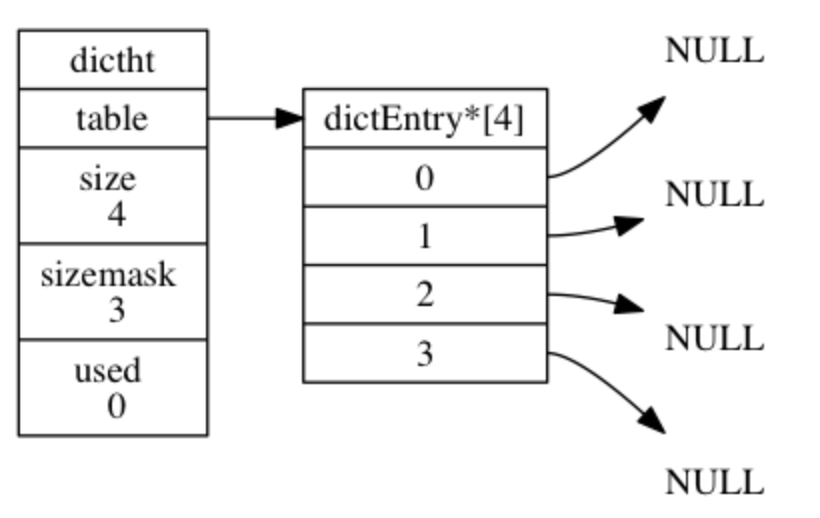
哈希表节点结构
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
- key 属性保存着键值对中的键。
- v 属性则保存着键值对中的值, 其中键值对的值可以是一个指针, 或者是一个 uint64_t 整数, 又或者是一个 int64_t 整数。
- next 属性是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来解决键冲突(collision)的问题。
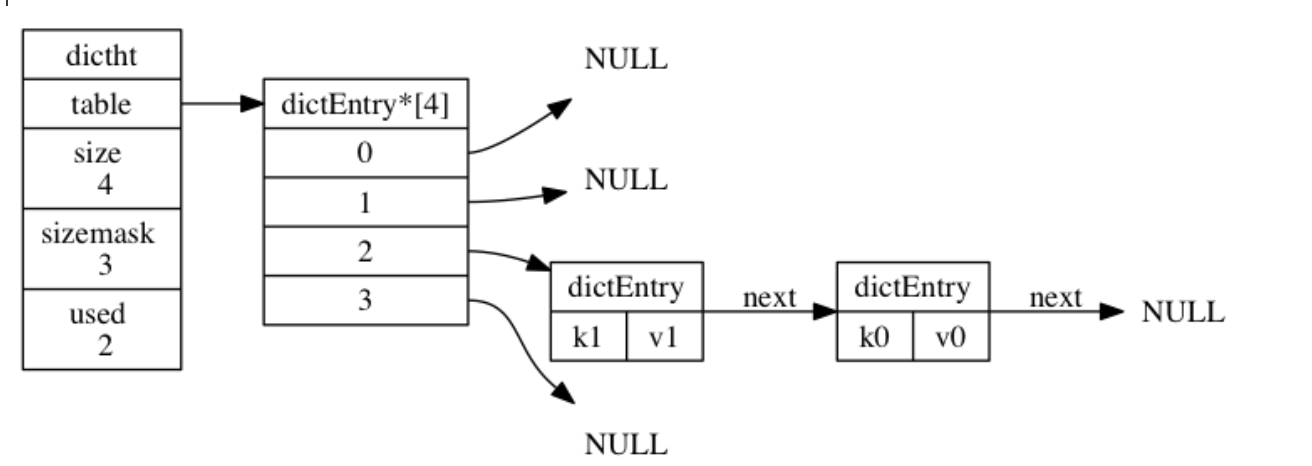
普通状态下(没有进行 rehash)的字典:
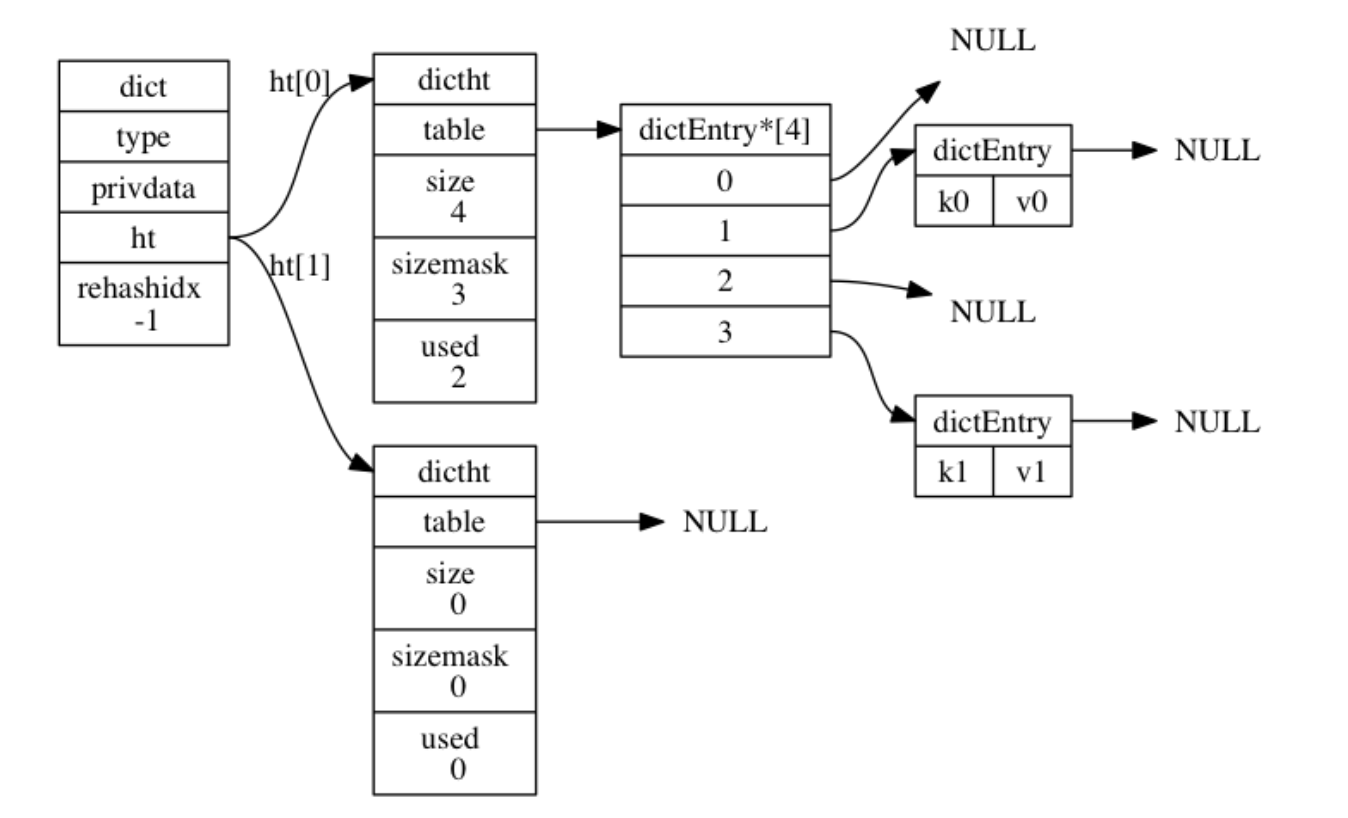
哈希算法
计算索引
当要将一个新的键值对添加到字典里面时, 程序需要先根据键值对的键计算出哈希值和索引值, 然后再根据索引值, 将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。
# 使用字典设置的哈希函数,计算键 key 的哈希值
hash = dict->type->hashFunction(key);
# 使用哈希表的 sizemask 属性和哈希值,计算出索引值
# 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1]
index = hash & dict->ht[x].sizemask;
哈希冲突
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时, 我们称这些键发生了冲突(collision)。
Redis 的哈希表使用链地址法(separate chaining)来解决键冲突: 每个哈希表节点都有一个 next 指针, 多个哈希表节点可以用 next 指针构成一个单向链表, 被分配到同一个索引上的多个节点可以用这个单向链表连接起来, 这就解决了键冲突的问题。
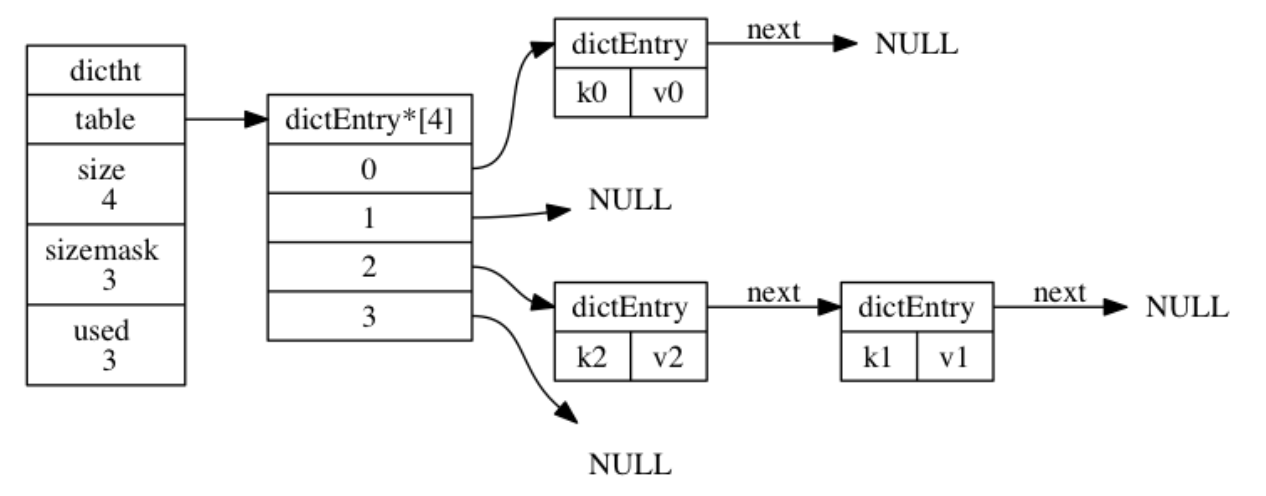
因为 dictEntry 节点组成的链表没有指向链表表尾的指针, 所以为了速度考虑, 程序总是将新节点添加到链表的表头位置(复杂度为 O(1)), 排在其他已有节点的前面。
rehash
哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。
负载因子
# 负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[0].used / ht[0].size
扩容与缩容
扩容条件
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 1 ;
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5 ;
执行 BGSAVE 命令或 BGREWRITEAOF 命令的过程中, Redis 需要创建当前服务器进程的子进程, 而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率, 所以在子进程存在期间, 服务器会提高执行扩展操作所需的负载因子, 从而尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存。
缩容条件
当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作。
rehash过程
- 以及 ht[0] 当前包含的键值对数量 (也即是 ht[0].used 属性的值):
- 如果执行的是扩展操作, 那么 ht[1] 的大小为第一个大于等于 ht[0].used * 2 的 2^n (2 的 n 次方幂);
- 如果执行的是收缩操作, 那么 ht[1] 的大小为第一个大于等于 ht[0].used 的 2^n 。
- 将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到 ht[1] 哈希表的指定位置上。
- 当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后 (ht[0] 变为空表), 释放 ht[0] , 将 ht[1] 设置为 ht[0] , 并在 ht[1] 新创建一个空白哈希表, 为下一次 rehash 做准备。
渐进式 rehash
扩展或收缩哈希表需要将 ht[0] 里面的所有键值对 rehash 到 ht[1] 里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。
渐进式 rehash过程
以下是哈希表渐进式 rehash 的详细步骤:
- 为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
- 在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始。
- 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
- 随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
渐进式 rehash 执行期间的哈希表操作
因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
哈希对象源码
新建字典
/*
* 创建一个新的字典
* T = O(1)
*/
dict *dictCreate(dictType *type, void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
/*
* 初始化哈希表
* T = O(1)
*/
int _dictInit(dict *d, dictType *type, void *privDataPtr)
{
// 初始化两个哈希表的各项属性值
// 但暂时还不分配内存给哈希表数组
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
// 设置类型特定函数
d->type = type;
// 设置私有数据
d->privdata = privDataPtr;
// 设置哈希表 rehash 状态
d->rehashidx = -1;
// 设置字典的安全迭代器数量
d->iterators = 0;
return DICT_OK;
}
/*
* 重置(或初始化)给定哈希表的各项属性值
* p.s. 上面的英文注释已经过期
* T = O(1)
*/
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
新建hash表
/*
* 根据需要,初始化字典(的哈希表),或者对字典(的现有哈希表)进行扩展
*
* T = O(N)
*/
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
// 渐进式 rehash 已经在进行了,直接返回
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
// 如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表
// T = O(1)
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
// 一下两个条件之一为真时,对字典进行扩展
// 1)字典已使用节点数和字典大小之间的比率接近 1:1
// 并且 dict_can_resize 为真
// 2)已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
// 新哈希表的大小至少是目前已使用节点数的两倍
// T = O(N)
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
rehash
/* Performs N steps of incremental rehashing. Returns 1 if there are still
*
* 执行 N 步渐进式 rehash 。
*
* 返回 1 表示仍有键需要从 0 号哈希表移动到 1 号哈希表,
* 返回 0 则表示所有键都已经迁移完毕。
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table.
*
* 注意,每步 rehash 都是以一个哈希表索引(桶)作为单位的,
* 一个桶里可能会有多个节点,
* 被 rehash 的桶里的所有节点都会被移动到新哈希表。
*
* T = O(N)
*/
int dictRehash(dict *d, int n) {
// 只可以在 rehash 进行中时执行
if (!dictIsRehashing(d)) return 0;
// 进行 N 步迁移
// T = O(N)
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
// 如果 0 号哈希表为空,那么表示 rehash 执行完毕
// T = O(1)
if (d->ht[0].used == 0) {
// 释放 0 号哈希表
zfree(d->ht[0].table);
// 将原来的 1 号哈希表设置为新的 0 号哈希表
d->ht[0] = d->ht[1];
// 重置旧的 1 号哈希表
_dictReset(&d->ht[1]);
// 关闭 rehash 标识
d->rehashidx = -1;
// 返回 0 ,向调用者表示 rehash 已经完成
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
// 确保 rehashidx 没有越界
assert(d->ht[0].size > (unsigned)d->rehashidx);
// 略过数组中为空的索引,找到下一个非空索引
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
// 指向该索引的链表表头节点
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
// 将链表中的所有节点迁移到新哈希表
// T = O(1)
while(de) {
unsigned int h;
// 保存下个节点的指针
nextde = de->next;
/* Get the index in the new hash table */
// 计算新哈希表的哈希值,以及节点插入的索引位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 插入节点到新哈希表
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
// 更新计数器
d->ht[0].used--;
d->ht[1].used++;
// 继续处理下个节点
de = nextde;
}
// 将刚迁移完的哈希表索引的指针设为空
d->ht[0].table[d->rehashidx] = NULL;
// 更新 rehash 索引
d->rehashidx++;
}
return 1;
}
尝试将键插入到字典中
/*
* 尝试将键插入到字典中
*
* 如果键已经在字典存在,那么返回 NULL
*
* 如果键不存在,那么程序创建新的哈希节点,
* 将节点和键关联,并插入到字典,然后返回节点本身。
*
* T = O(N)
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
// 如果条件允许的话,进行单步 rehash
// T = O(1)
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
// 计算键在哈希表中的索引值
// 如果值为 -1 ,那么表示键已经存在
// T = O(N)
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
// T = O(1)
/* Allocate the memory and store the new entry */
// 如果字典正在 rehash ,那么将新键添加到 1 号哈希表
// 否则,将新键添加到 0 号哈希表
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// 为新节点分配空间
entry = zmalloc(sizeof(*entry));
// 将新节点插入到链表表头
entry->next = ht->table[index];
ht->table[index] = entry;
// 更新哈希表已使用节点数量
ht->used++;
/* Set the hash entry fields. */
// 设置新节点的键
// T = O(1)
dictSetKey(d, entry, key);
return entry;
}















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









