










使用kettle批量下载文件
最新有项目中需要批量下载文件并把结果导入到数据中,通过一些实验测试,kettle确实可以胜任。问题是关键是如果通过http批量下载文件,本文将详细说明,假设你已经了解了kettle的基本知识,如果需要可以查看我的系列入门教程。
本文的示例代码可以在这里下载.
主作业
kettle的转换中没有通过http下载文件的步骤,但是job的有对应的步骤,所以在主job调用子job(Download.kjb),需要下载的文件列表通过一个转换提供。

文件列表转换
这里我仅仅使用数据表步骤提供五条记录文件,有两个字段分别为“filename”和“url”(url的内容根据你的业务需要,这里使用一个示例供测试),为了让这些数据在download.kjb中可以访问,后面使用了job类别中“copy rows to result”步骤。
下载的作业
download作业只下载一个单独的文件,但是我们需要针对文件列表中每条记录都要运行。这里需要在作业的高级设置,选中“Execute for every input row”,实现循环调用。
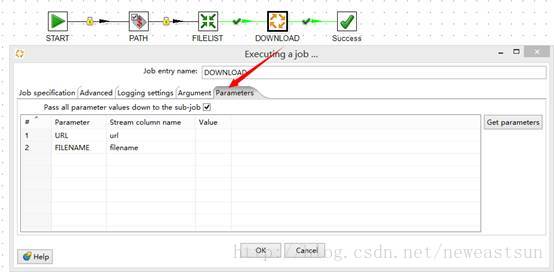
在http步骤中,我们需要设置filename和url,这两个字段内容来自输入后,我们使用变量${URL}和${FILENAME},为了使这些数据和变量关系对应,我们需要做两件事情。
1) 需要声明“URL”和“FILENAME”命名参数
在作业的属性设置,命名参数选项卡中设置。

2) 选要指定字段和变量(命名参数)的映射关系
在主作业中双击download作业步骤,然后再命名参数选项中配置映射关系。同时在主作业中定义了PATH变量,确定文件保存的位置,http步骤中使用该变量确定文件位置及名称。
结论
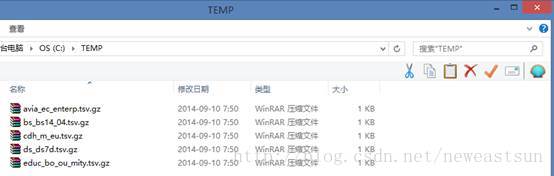
运行完成后,可以在c:\temp目录中可以成功下载的文件,如果把文件的结果读入到数据库,就不是难事了。有需要通过其他的文章讲解。















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









