







IP代理池是一个用于管理和提供代理IP地址的系统或服务。在网络中,IP代理池的主要目的是帮助用户隐藏其真实IP地址,以实现一些特定的目标,如爬取网站数据、访问受限制的内容或保护个人隐私等。以下是对IP代理池的解释:
-
IP代理的概念: 代理(Proxy)是指一种充当中间人的服务器或服务,用户通过代理与目标服务器通信,从而隐藏其真实的网络身份。代理服务器可以拦截、修改、转发用户和目标服务器之间的通信数据。
-
IP代理池的作用: IP代理池是一个包含多个代理IP地址的集合。通过使用IP代理池,用户可以轮流使用不同的代理IP地址,防止被目标服务器或网站封禁,提高访问成功率。这对于需要频繁访问或爬取大量数据的任务特别有用。
-
动态IP切换: IP代理池通常会周期性地更新,添加新的代理IP,同时淘汰失效或被封禁的IP。这使用户能够实现动态IP切换,减少被检测到的风险,提高匿名性和稳定性。
-
应用场景:
- 爬虫和数据采集: 在爬取网站数据时,通过不断切换代理IP,可以避免被网站封禁,提高爬取效率。
- 访问受限制的内容: 一些网站可能根据用户的地理位置或IP地址限制访问,通过使用代理IP可以绕过这些限制。
- 网络安全和隐私保护: 用户可以使用代理IP来隐藏其真实IP地址,提高在网络上的匿名性,增强隐私保护。
-
IP代理池的管理: 管理IP代理池包括添加新的代理IP、监控代理IP的可用性、定期检测代理IP的匿名性和速度等。一些工具和服务可以帮助用户自动管理代理IP池。
搭建方法:
1.首先,需要搭建获取ip的环境和方法
一个GitHub开源项目,已对原项目做了更改xiaoou2/proxy_pool (github.com)
1.将git项目下载下来
git clone git@github.com:jhao104/proxy_pool.git
2.在conda搭建环境,py3.8就够了
conda create --name proxy_pool python=3.83.激活环境
conda activate proxy_pool4.打开下载好git文件配置好刚刚初始化的编译器环境后,安装相对应的包
pip install -r requirements.txt5.可能会因为部分冲突的原因有些包无法下载
通过简单pip install 包名==版本号简单下载即可
6.修改下载好的文件下的setting.py文件配置
#这个配置是基于第一次使用redis数据库和第一次使用ip代理池的小伙伴,如有大佬都使用过,自行修改
# setting.py 为项目配置文件 # 配置API服务 HOST = "0.0.0.0" # IP PORT = 5010 # 监听端口 # 配置数据库 DB_CONN = 'redis://:@127.0.0.1:6379/0' # 配置 ProxyFetcher PROXY_FETCHER = [#从12个获取代理的网址中随机获取代理 "freeProxy01", "freeProxy02", "freeProxy03", "freeProxy04", "freeProxy05", "freeProxy06", "freeProxy07", "freeProxy08", "freeProxy09", "freeProxy10", "freeProxy11" ]
2.下载redis数据库(如果已经有了的无需下载)
这个数据库可以看作是一个过渡,就是通过proxy_pool传递到redis,然后再传递到你自己的代码中,通过https传递
1.1.Linux环境安装Redis
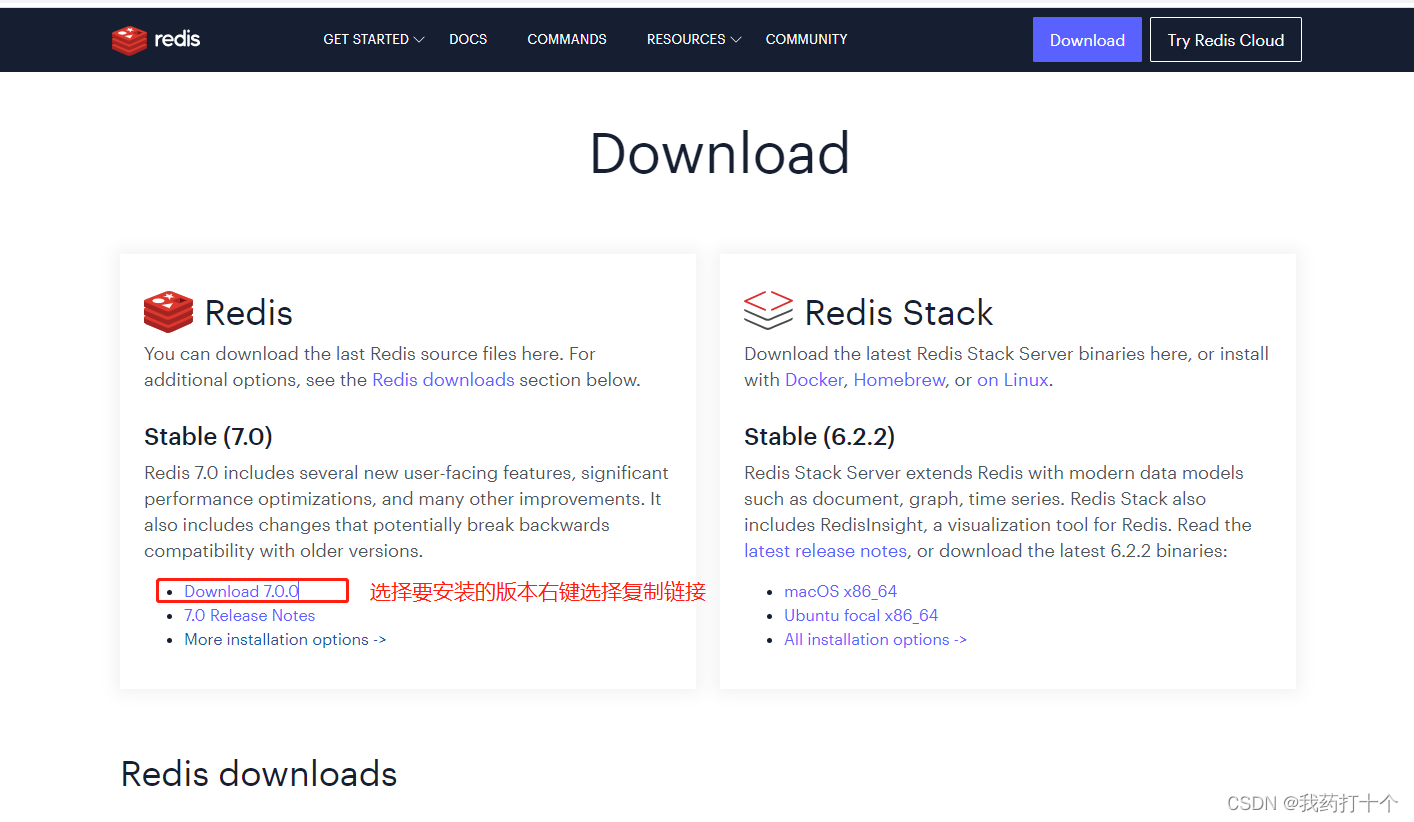
step-1:下载Redis
进入官网找到下载地址 Download | Redis
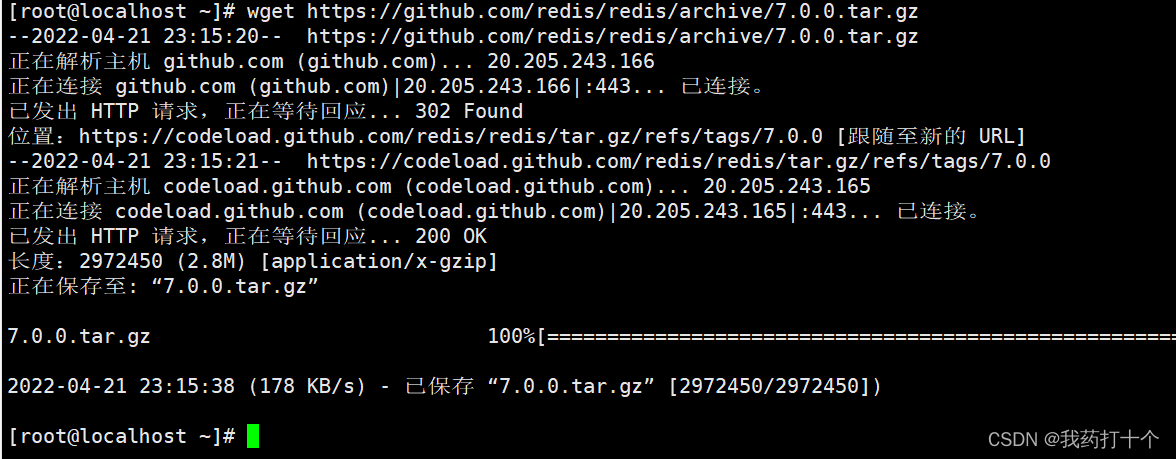
wget https://github.com/redis/redis/archive/7.0.0.tar.gz
step-2:解包
tar -zvxf 7.0.0.tar.gz
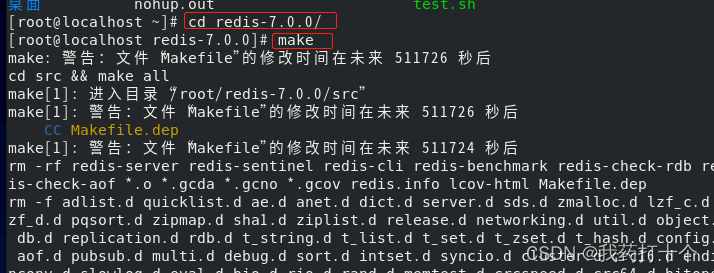
step-3:编译
cd redis-7.0.0 make
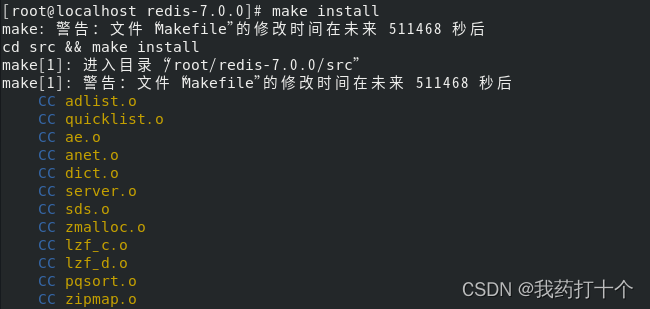
step-4:安装
make install
step-5(方式一):启动
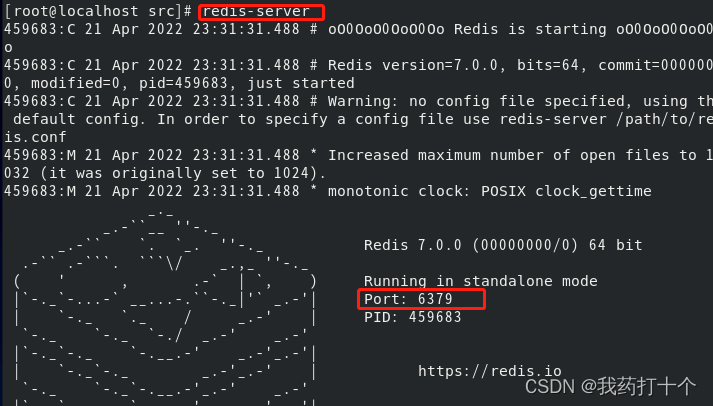
cd src redis-server
step-5(方式二):指定配置文件启动
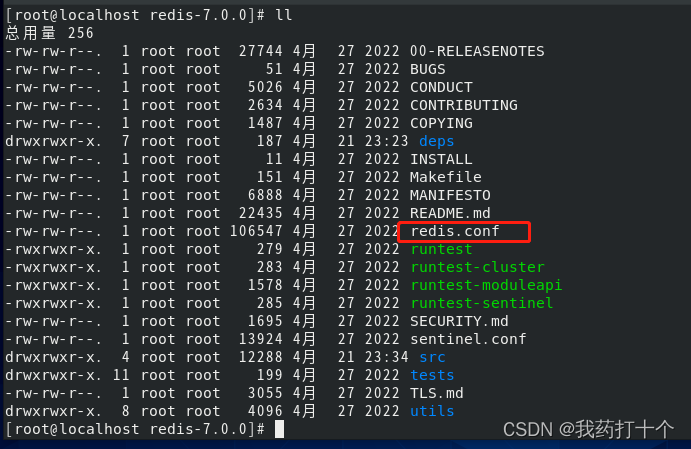
在redis的安装目录下有一个redis.conf配置文件
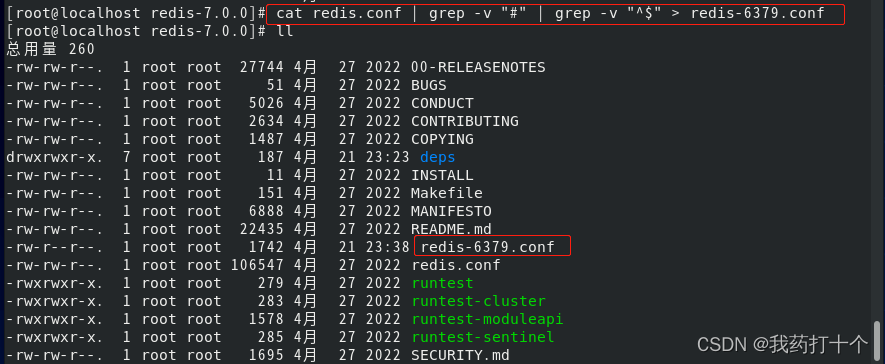
redis.conf文件里面没有用的信息比较多,使用cat命令过滤一下,生成一个新的配置文件
cat redis.conf | grep -v "#" | grep -v "^$" > redis-6379.conf
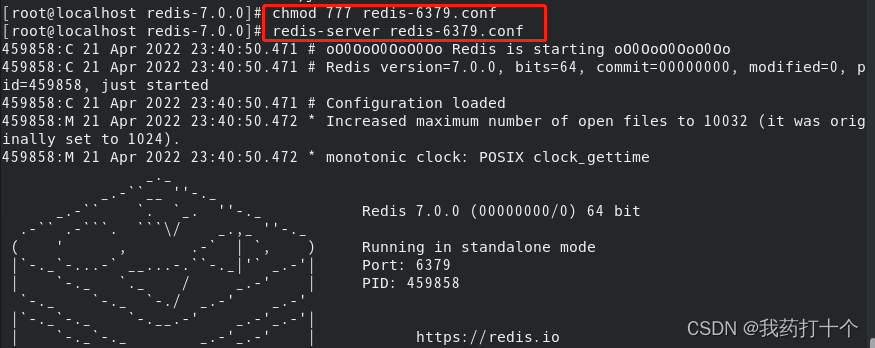
然后在这个配置文件修改自己需要的配置项,修改结束,启动redis
redis-server redis-6379.conf
step-6:校验
新建一个会话后在redis-4.4.0/src目录下使用命令连接 redis-cli
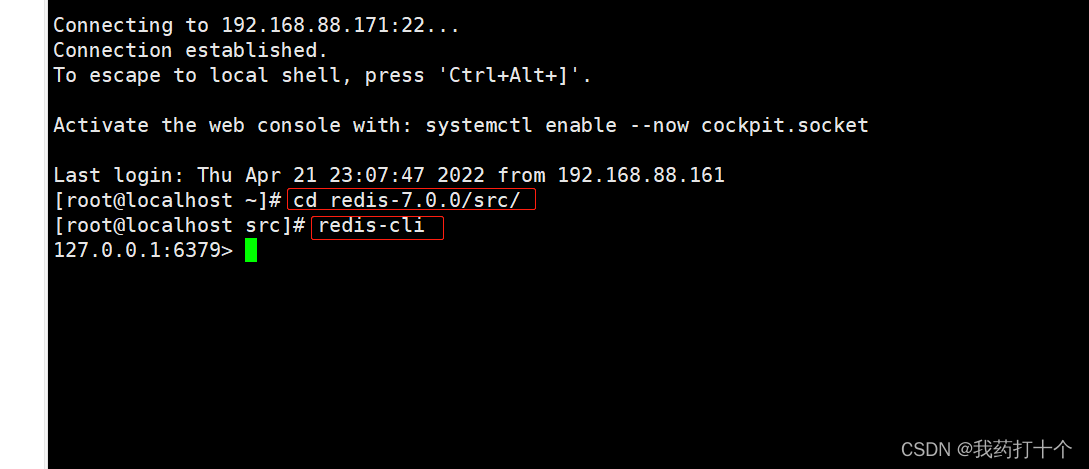
2.2.Windows环境安装Redis
step-1:下载文件
- 链接: Redis相关软件安装包.zip_免费高速下载|百度网盘-分享无限制 (baidu.com)
- 提取码: ri3s
3.启动redis数据库(windows环境)
在Redis文件夹里面,按顺序启动刚刚下载好的文件
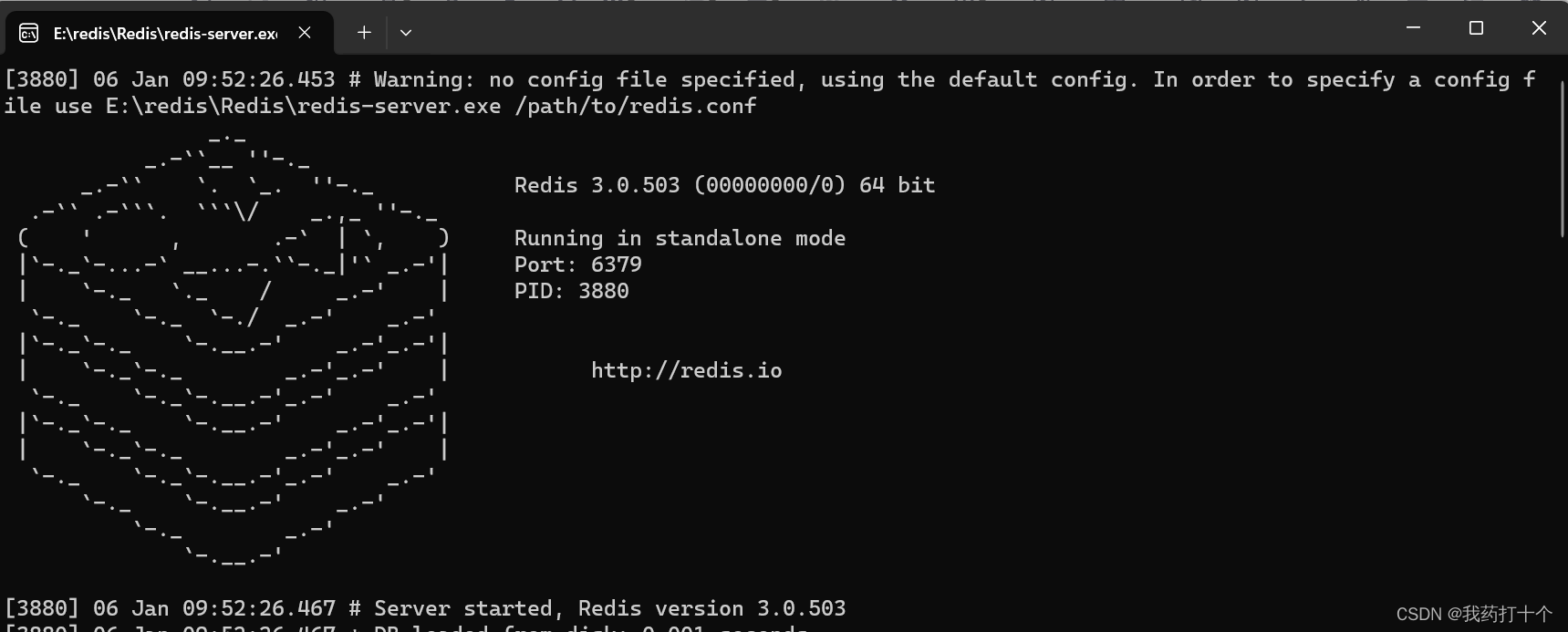
就会出现下面这两个命令行
4.启动proxy_pool获取代理程序
4.1在proxy_pool文件路径下,进入conda环境
conda activate proxy_pool4.2 运行调动程序
# 如果已经具备运行条件, 可用通过proxyPool.py启动。
# 程序分为: schedule 调度程序 和 server Api服务
# 启动调度程序
python proxyPool.py schedule
# 启动webApi服务
python proxyPool.py server
4.3运行结果
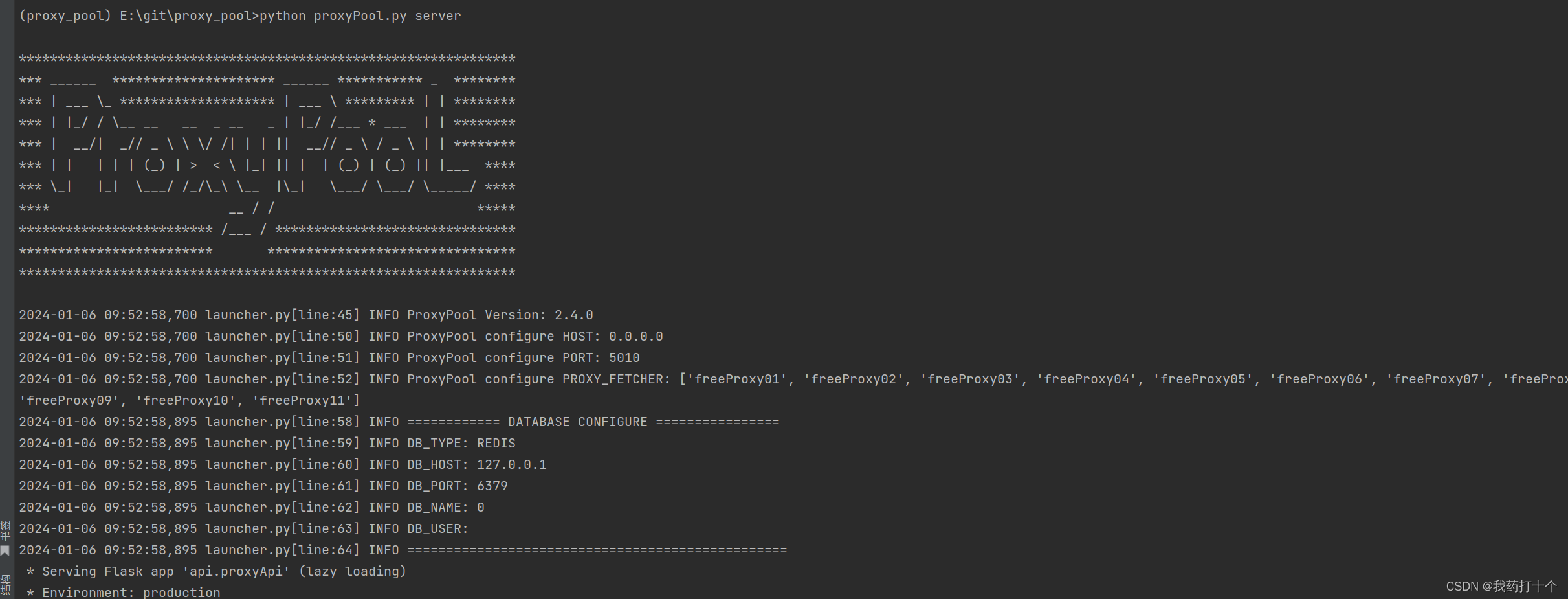
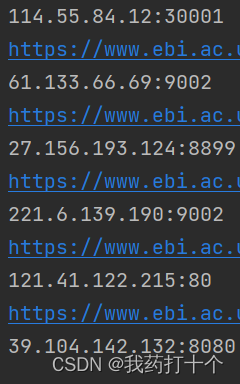
5.查询获取的ip代理和地区

6.如果在爬虫中使用,可以自己建立接口调用
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
#这里主要放你的请求代码,通过proxy = get_proxy().get("proxy")获得随机ip,然后主要在request等请求中加入,具体框架具体不同用法,例如:yield scrapy.Request(url=URL, callback=self.Single_Model, meta={'proxy': proxy},cookies=Cookie)#, meta={'proxy': proxy}
def getHtml():#可用可不用,看自己需要
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return None主要还是get_proxy获取代理然后根据自己任务进行调配使用(下面以scrapy框架作为演示)
proxy = self.get_proxy().get("proxy")
print(proxy)
yield scrapy.Request(url=URL, callback=self.Single_Model, meta={'proxy': proxy},cookies=Cookie)#, meta={'proxy': proxy}
主要使用ip代理池的方法和过程就如上所示,具体的其他用法请阅读GitHub文件给出的指引,这里就不再过多赘述了
希望这篇博文对你有帮助!!!!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









