






最新鲜的 ECCV 2020,二值神经网络精度首超ResNet? ReActNet 是 Bi-Real Net 作者在二值化研究领域的最新成果,精度达到了惊人的 69.4%,比著名的 XNOR-Net 的结果 51.2% 要高出了足足 18.2% ,所需的 FLOPs 仅是前者的一半!真的有这么神奇吗?

论文原地址:https://arxiv.org/abs/2003.03488
论文代码:https://github.com/liuzechun/ReActNet
大亮点:通过优化激活值的分布大幅提高了精确度 (ReAct-PReLU and ReAct-Sign functions)
对激活值动手脚这个想法其实不是这篇论文的原创。XNOR-Net,Dorefa-Net等目前采用的二值化手段都会对激活值乘上一个系数(比如说,权重的绝对值的平均值)来使二值网络可以表示更丰富的信息,或者说也可以理解成使二值化后的权重和全精度的权重之间的差异不那么大。如下所示:
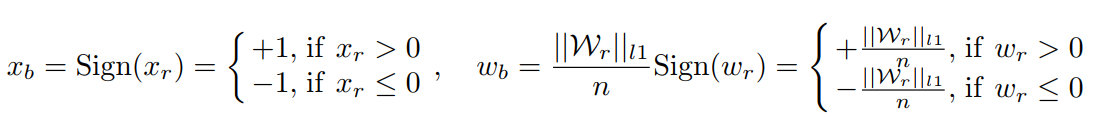
权重的分布一般是双峰分布(我在对INQ的解析中也有提到过,具体可以看看我的另一篇文章),如果我们想尽量减少二值化后的权重和全精度的权重之间的差异,我们就应该把两个峰对应的数作为-1和+1。一般来说权重的分布“大体”上是关于原点对称的,所以我们只需要使用一个简单的系数,就可以把分布缩放到合适的位置,这样我们的目的也就基本达成了。减小二值化权重和原权重的差异有利于在重训练阶段更快更好地恢复精度,如果二值化权重差的太多,那么原权重也就失去价值了,效果可能就和重头训练一样,而重头训练一个二值网络是十分困难的,因为二值网络不够冗余,无法学得很好。我们可以认为这种手段是对权重分布的一种改变(改变了标准差)。
可见,数值的分布对网络的精度是有影响的,改变数值分布一直以来都是一大研究点。神经网络里涉及数值分布的地方有权重、梯度和激活值。对权重的改变除了改变标准差之外,还有一些研究涉及到了对权重进行归一化(IR-net,CVPR 2020);有些研究涉及对梯度进行零均值化(https://arxiv.org/abs/2004.01461,也是ECCV 2020)。它们改变的基本上就是数值分布的均值或标准差,也取得了挺好的效果。ReActNet其实也不例外,只是它针对的是激活值的分布。

首先,作者提出激活值的分布对二值化网络的精度会有一定的影响。如上图中的猫(老鼠?),对于全精度网络来说,激活值的分布对结果不会有什么影响,该看得到的特征还是可以看得到,无论是暗点还是亮点我们都可以辨认出是猫,神经网络也一样可以做到;但对于二值网络来说,由于只有0和1两种值,如果我们对激活值进行平移,猫的清晰程度会发生很大的变化,对于网络来说就意味着识别难度在改变。如果我们能改变激活值的分布(平移改变均值,或者放缩改变标准差)使之更有利于二值网络去学习,那二值网络的精度就可以得到提升了。这也就是这篇论文在做的事。
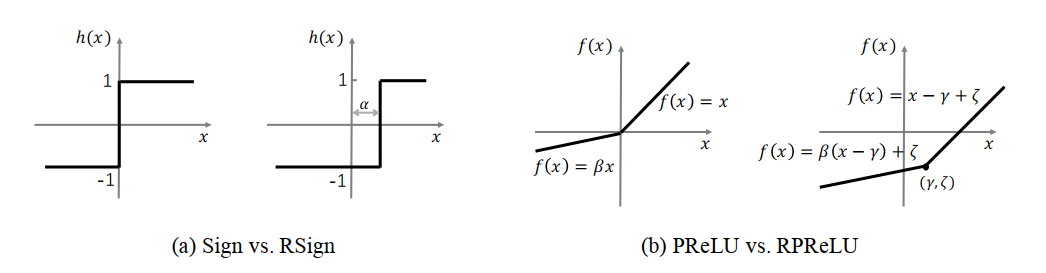
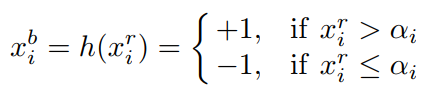
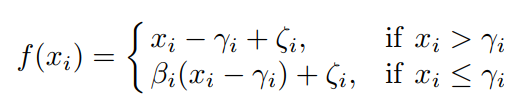
论文作者提出了RSign和RPReLU来取代Sign(二值的函数)和PReLU(激活函数)。这两个函数都是channel-wise的,也就是每个通道都有自己的四个参数。两个函数都是简单的线性变化,主要也是改变了数值分布的均值和标准差。公式里的四个参数都是可学习的,不是超参数。作者给出了这四个参数的梯度:
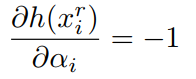
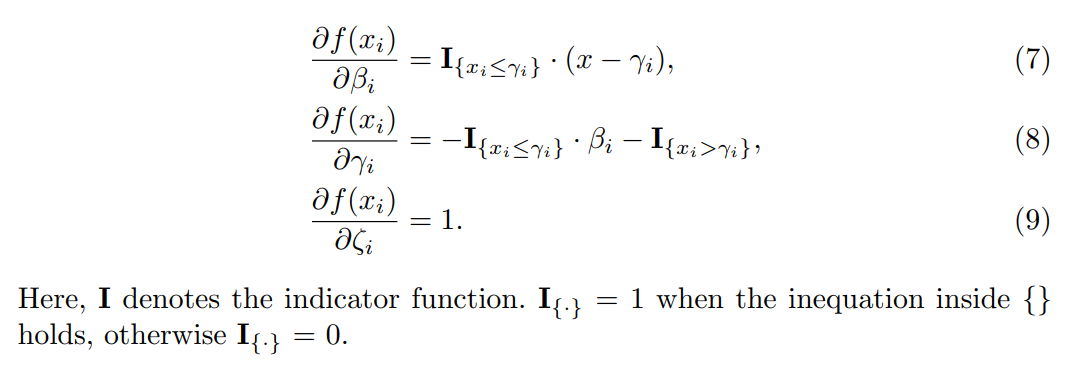
在进行SGD的过程中神经网络也可以一起把这些参数给学到了,从而把激活值调整到最适合自己的状态。这个方法把精度提高了6.9%(Imagenet)。
小亮点:Distributional Loss
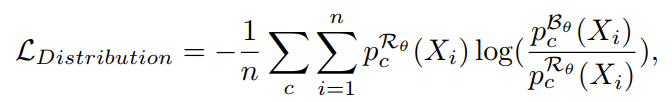
作者还采用distributional loss作为最终的损失函数,意思是要让二值网络的输出接近原来的全精度网络的输出。相似度的衡量用的是KL divergence。这个小方法可以提高1.4%的精确度。
实验结果
以下数据均为Imagenet数据集的结果:
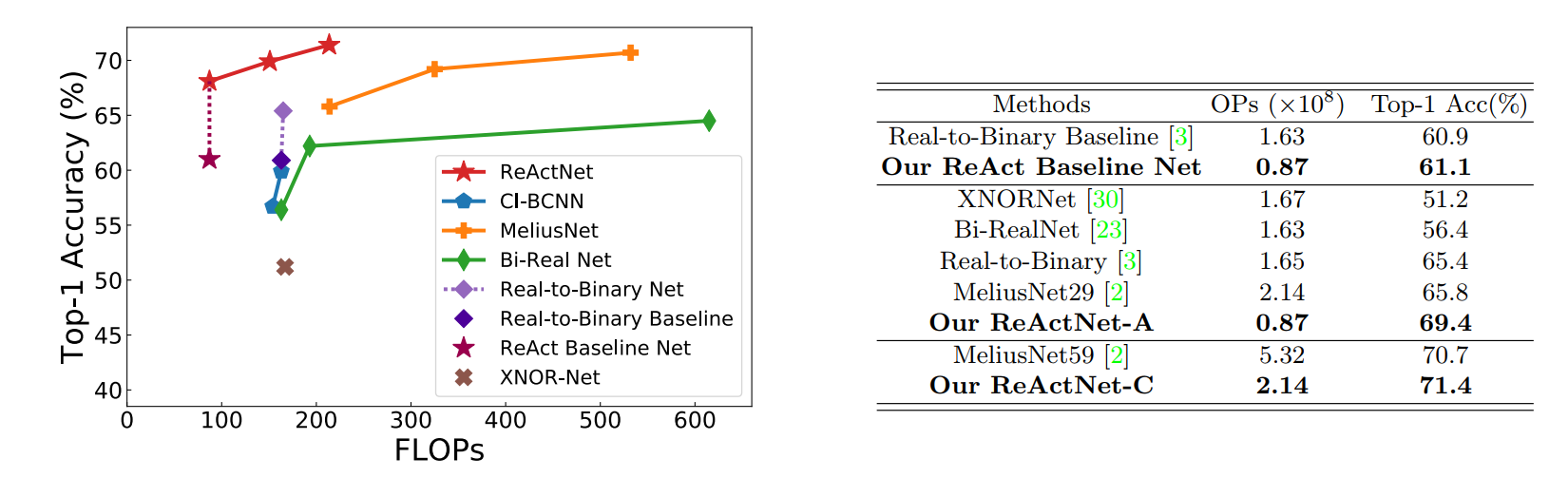


但是呢这个模型其实是MobileNetV1的二值模型,对比表格中并没有给出它相对于原模型的精确度损失是多少。文中有提到损失是within 3.0%。这个结果很有意思,IR-net在二值权重全精度激活值的配置下精确度损失也是about 3.0%。这说明经过一定的改变后二值化的激活值是足够表征网络需要的所有信息的,剩下的精确度损失如何降低我觉得主要要看权重了(或许还有梯度)。
总结
方法确实不错,但其实也不是真的很突破的那种。原MobileNetV1的计算量是0.58GFLOPS(数据来源:神经网络量化-知乎),这个网络的计算量是0.087GFLOPS(OPs = BOPs/64 + FLOPs,OPs可以从上面的图中获得),为原网络的0.15倍。计算量可以等效为原网络的9.6(64*0.15)比特量化网络?好像说不过去,毕竟我自己做实验4比特网络都可以几乎无损压缩(只损失0.1%~0.2%),8比特是绝对的无损压缩。这个结果显然不是很行,我觉得量化网络最终是要和量化前的原网络比才有意义,这样才能投入到生产应用中,真正用量化的技术加速网络的执行。换一个网络来比较就好像拿Resnet的二值网络和Alexnet比较一样不靠谱(有点过分,但意思就是这个)。以上只是我的个人愚见,不管怎么说,论文中提供的思路还是很值得我们学习的。
想知道更多论文解读和深度学习方法,欢迎访问我的博客:https://fishercat.top

















 2435
2435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









