






 论文介绍了一种名为ReAct的方法,通过结合大语言模型的推理和行动能力,提高理解和交互决策任务的性能。实验显示,ReAct在问答、事实验证和决策任务中优于传统方法,增强了模型的可解释性和鲁棒性。
论文介绍了一种名为ReAct的方法,通过结合大语言模型的推理和行动能力,提高理解和交互决策任务的性能。实验显示,ReAct在问答、事实验证和决策任务中优于传统方法,增强了模型的可解释性和鲁棒性。
ReAct: Synergizing Reasoning and Acting in Language Models 论文详细介绍了将大语言模型的能力与推理和行动相结合,以提高其在理解和交互决策任务中的表现。让我们一块来解读下。
论文摘要
论文主要探讨了如何将大语言模型的能力与推理和行动相结合,以提高其在理解和交互决策任务中的表现。该方法名为ReAct,通过交替生成推理轨迹和特定任务的动作,使两者之间产生更大的协同作用。实验结果表明,在问答和事实验证等任务中,ReAct能够克服传统链式思维推理中存在的幻觉和错误传播问题,并且生成的任务解决路径比基线更加可解释。此外,在两个互动决策基准测试中,ReAct的表现优于模仿学习和强化学习方法,分别提高了成功率34%和10%。

论文方法
方法描述
本文提出的 ReAct(Reasoning Action Trajectory) 提供了一种基于少样本学习的多模态推理框架,用于回答自然语言问题。ReAct 通过在给定的任务上下文中自动搜索相关信息并根据搜索结果生成合理的答案。该方法使用了手动构建的 ReAct 格式的内容作为小样本提示Prompt并输入给LLM,以帮助模型更好地理解任务和上下文信息。
方法改进
为了解决传统的思维链方法CoT(Chain-of-thought prompting)容易出现虚假事实或想法的问题,本文提出了 ReAct 和 CoT-SC 的结合方法。具体来说,当 ReAct 没有在给定的步数内返回答案时,会切换到 CoT-SC;而当 CoT-SC 中大多数答案出现次数不到总次数的一半时,则会回到 ReAct。这种方法可以在保证准确性的前提下提高解决问题的速度和效率。
解决的问题
ReAct 提供了一种有效的解决方案,可以帮助语言模型更好地理解和回答自然语言问题。与传统的少样本学习方法相比,ReAct 更加高效、准确,可以处理更复杂的任务和场景。同时,本文还提出了一种新的结合方法,进一步提高了模型的性能和鲁棒性。
论文实验
论文主要介绍了ReAct这一新型的模型在不同任务上的表现,并与现有方法进行了比较。具体来说,本文进行了以下三个对比实验:
第一个实验是针对HotpotQA和Fever两个任务的比较。在这个实验中,作者使用了PaLM-540B作为基础模型,并比较了四种不同的提示方法(标准提示、CoT提示、Act提示和ReAct提示)的效果。结果表明,ReAct提示比Act提示表现更好,在这两个任务上都取得了更好的准确率。
第二个实验是对ReAct和CoT两种提示方法的比较。在这个实验中,作者比较了ReAct提示和CoT提示在HotpotQA和Fever两个任务上的效果。结果表明,ReAct提示在Fever任务上表现略好于CoT提示,但在HotpotQA任务上略微落后于CoT提示。
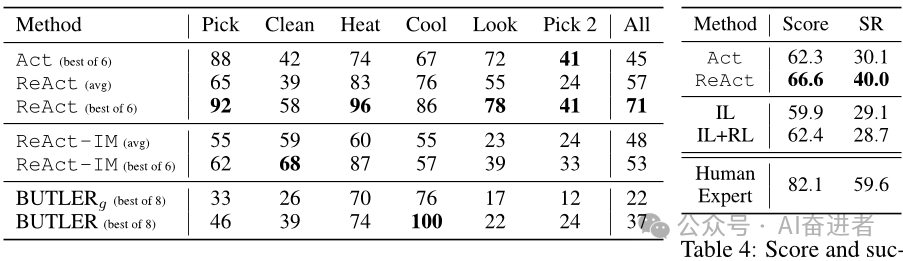
第三个实验是在ALFWorld和WebShop两个决策制定任务上的比较。在这个实验中,作者使用了随机标注的轨迹来提示模型,比较了Act提示和ReAct提示在这两个任务上的效果。结果表明,ReAct提示在这两个任务上都表现得更好,特别是在WebShop任务上,ReAct提示的表现十分优秀。
总的来说,本文展示了ReAct提示在多个任务上的优异表现,并证明了内部推理和外部反馈相结合的重要性。


论文总结
文章优点
该论文提出了ReAct的方法,将推理和行动结合起来,用于解决各种自然语言推理和决策问题。该方法在多个基准测试中表现出色,并且具有以下优点:
-
简单直观:设计ReAct提示是直接的,人类注释者只需将其思考以语言的形式添加到其采取的动作之上。
-
通用灵活:由于灵活的Thought → Action → Observation 模式,ReAct适用于各种任务,包括问答、事实验证、文本游戏和网页导航等。
-
性能表现良好:ReAct仅需学习一到六个上下文示例即可泛化到新任务实例,始终优于只使用推理或行动的基线方法。
-
可解释性和可控性:ReAct提供了可解释的决策过程,使人类能够轻松检查推理和事实正确性。此外,人类还可以通过编辑思路来控制或纠正代理行为。
方法创新点
该论文的主要贡献在于提出了ReAct方法,这是一种基于提示的语言模型,可以实现推理和行动之间的协同作用。具体来说,该方法实现了以下创新点:
-
引入了新的行动空间:将行动空间扩展为L,即语言空间,允许模型生成自由形式的语言思维,而不是仅仅执行操作。
-
使用无监督的少样本学习:ReAct只需要几个上下文示例就可以泛化到新任务实例,这使得它成为一种有效的无监督学习方法。
-
实现了与外部环境的交互:ReAct允许模型与外部环境(如Wikipedia)进行交互,从而支持更复杂的推理和决策过程。
未来展望
该论文提出的ReAct方法为解决自然语言推理和决策问题提供了一个有前途的方法。未来的研究可以从以下几个方面进一步发展:
-
探索更多任务类型:虽然该论文主要关注知识密集型推理任务,但ReAct也可以应用于其他类型的自然语言处理任务,例如对话系统和机器翻译。
-
提高行动空间的质量:当前的行动空间限制较大,无法满足复杂任务的需求。因此,未来的研究可以探索如何提高行动空间的质量,以便更好地支持推理和决策。
-
结合强化学习:ReAct目前是一种无监督的学习方法,但它仍然缺乏对于长期奖励的关注。因此,未来的研究可以考虑结合强化学习,以实现更好的长期规划和决策能力。
各模式Prompt举例
Original:
![]()
Act:

CoT:

ReAct:

可以感受一下ReAct 的Thought → Action → Observation模式。
关于我:AI产品经理(目前在寻找新机会),主要关注AI Agent 应用。公众号:AI奋进者。如有好的想法欢迎一起沟通交流。
Agent系列文章已经逐步更新:
Agent 系列之 ReWOO框架解析![]() https://blog.csdn.net/letsgogo7/article/details/138259507
https://blog.csdn.net/letsgogo7/article/details/138259507
Agent系列之 Plan-and-Solve Prompting 论文解析![]() https://blog.csdn.net/letsgogo7/article/details/138259154
https://blog.csdn.net/letsgogo7/article/details/138259154
Agent系列之LangChain中ReAct的实现原理浅析![]() https://blog.csdn.net/letsgogo7/article/details/138197137
https://blog.csdn.net/letsgogo7/article/details/138197137
Agent系列之ReAct: Reasoning and Acting in LLM 论文解析![]() https://blog.csdn.net/letsgogo7/article/details/138259590Agent 系列之 LLM Compiler框架解析
https://blog.csdn.net/letsgogo7/article/details/138259590Agent 系列之 LLM Compiler框架解析![]() https://blog.csdn.net/letsgogo7/article/details/138284351
https://blog.csdn.net/letsgogo7/article/details/138284351















 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









