







距离度量(distance measure)函数dist(∙,∙)满足的一般性质:
- 非负性:dist(xi,xj)≥0;
- 同一性:dist(xi,xj)=0,当且仅当xi=xj;
- 对称性:dist(xi,xj)=dist(xj,xi), ;
- 直递性:dist(xi,xj)≤dist(xi,xk)+dist(xk,xj), .
常用的距离度量方法是闵可夫斯基距离(Minkowski distance)距离度量法,一般表示为:
![]() (1)
(1)
式中p≥0, p=2即为欧式距离(Euclidean distance),p=1时即为曼哈顿距离(Manhattan distance)。通常情况下,样本属性可分为“有序属性”(ordinal attribute)和“无序属性”(non-ordinal attribute),“有序属性”的属性值之间的距离具有一定的连续属性,能够直接在属性值上计算距离,因此,从一定意义上来讲,闵可夫斯基距离通常用于有序属性。而无序属性可用VDM(Value Difference Metric)[Stanfill and Waltz, 1986],其表示为:
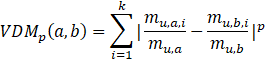 (2)
(2)
式中,![]() 表示属性在
表示属性在![]() 上取值为a的样本数,
上取值为a的样本数,![]() 表示在第i个样本簇中在属性u上取值为a的样本数,k为样本簇数目,a和b分别表示两种不同的离散值。
表示在第i个样本簇中在属性u上取值为a的样本数,k为样本簇数目,a和b分别表示两种不同的离散值。
当样本中不同属性的重要性不同时,可以使用“加权距离”(weight distance),以加权“闵可夫斯基距离”(Minkowski distance)为例:
![]() (3)
(3)
其中权重![]() (i=1,2,…,n),
(i=1,2,…,n),![]() 。
。
参考自周志华《机器学习》















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









