







一.写在前面
oo第一单元需要学生通过对表达式结构进行建模,完成多变量多项式的括号展开,初次体会层次化设计的思想。在这个单元的学习中,我学到了递归下降的方法,面向对象的三大思想(封装,继承,多态),并且懂得怎么用容器存储对象,用类来管理对象。最重要的是,这个单元让我懂得了架构的重要性,一个好的架构在这连续三周难度增加的开发中起到非常大的帮助。虽然这种思维的改变特别漫长且痛苦。
二.任务要求
作业1:根据题目设定的形式化表述对表达式进行展开括号的处理,输出恒等变形后的表达式
作业2:在作业1基础上的形式化表述中增加多层括号,自定义函数和三角函数的要求,同样是输出恒等变形后的表达式
作业3:在作业1和作业2基础上的形式化表述中增加求导算子,也同样是输出恒定变形后的表达式
三.设计思路
文法规则

总体思路
花了大概两天确认思路,结合第一次训练提供的代码和往届学长的思路,最后总结出自己的结构,总体分为5个部分:输入-->字符串预处理-->递归下降将表达式处理成多项式相加--->多项式的处理和合并-->最后表达式分为多项式输出。
架构分析

首先从主函数中得到字符串,然后放到 Lexer 进行预处理,最后字符串装在 Lexer 里一起放到Paser 进行递归下降处理转化成n个多项式相加。其中下降分为三个部分,Exper ,Tansform,Fartor ;Fartor 中分为Exper ,Power ,Trigo ,Number ,Derication 五个部分,利用递归下降进行不断细分后,把Fartor 用LinkedList 容器装在Term 里面,Terms 中的Fartor 再进行计算后封装在Tansform 中,就变成一个个符合规则的项,再把Tansform 用ArrayList 容器装在Exper 里面,最后main 方法调用Exper 改写的toString 方法将输入的input 经过一系列处理得到的结果输出。
Lexer--词法分析器
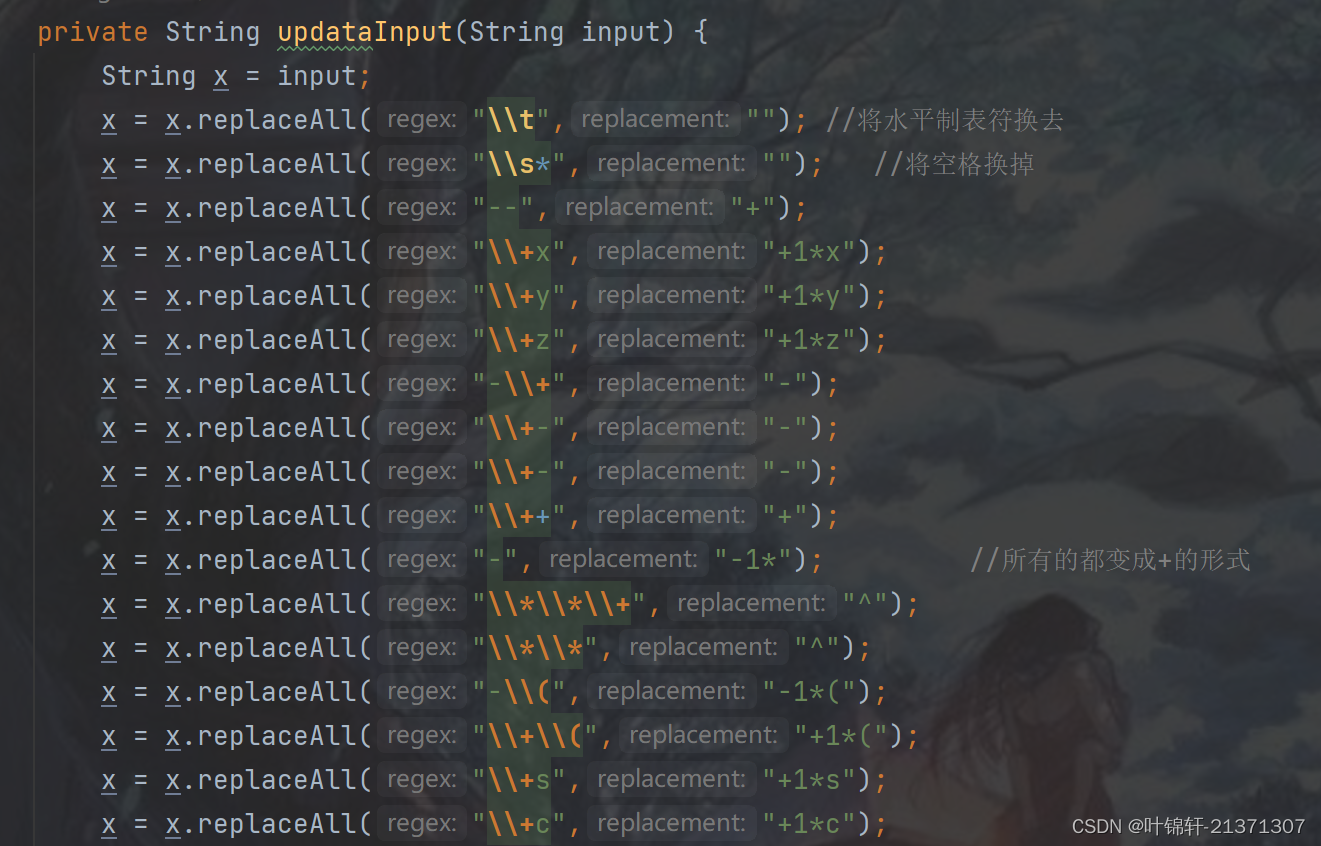
Lexer 有两大作用,一个作用是预处理,预处理当中做了三件事情:第一件是将所有空格处理,并且进行一些+-,--,+( 等符号进行更加标准化的处理,方便后续的处理。(下图放入部分代码)
第二件是将自定函数消去,将实参带入直接变成展开的表达式(下图放入部分代码)。
例如f(x)=x+4;expr = f(x**2); 化简后变成expr=x**2+4
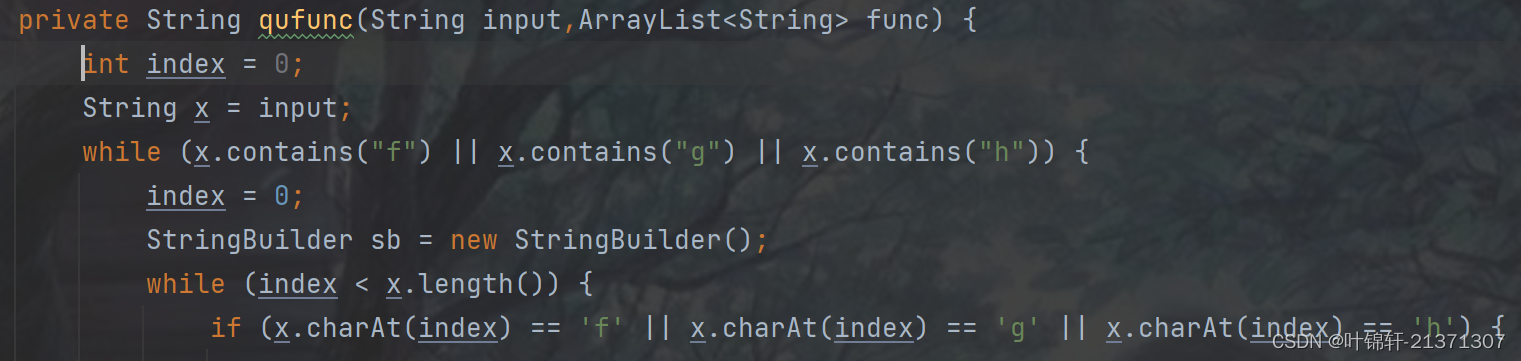
第三件是将指数消去,变成多个表达式相乘(下图放入部分代码)
例如expr = (x+1)**2; 化简后变成expr = (x+1)*(x+1)

另一个作用是把预处理过后的字符串进行词法分析,拆分成一个个小元素,例如30*dx(sin(x))拆分成30,dx,sin,(,x,)。处理过后所有元素都被解析出来,后续再利用Parser 读入分析即可.
一个个元素通过peek()进行读取,,通过next()指向下一个元素。
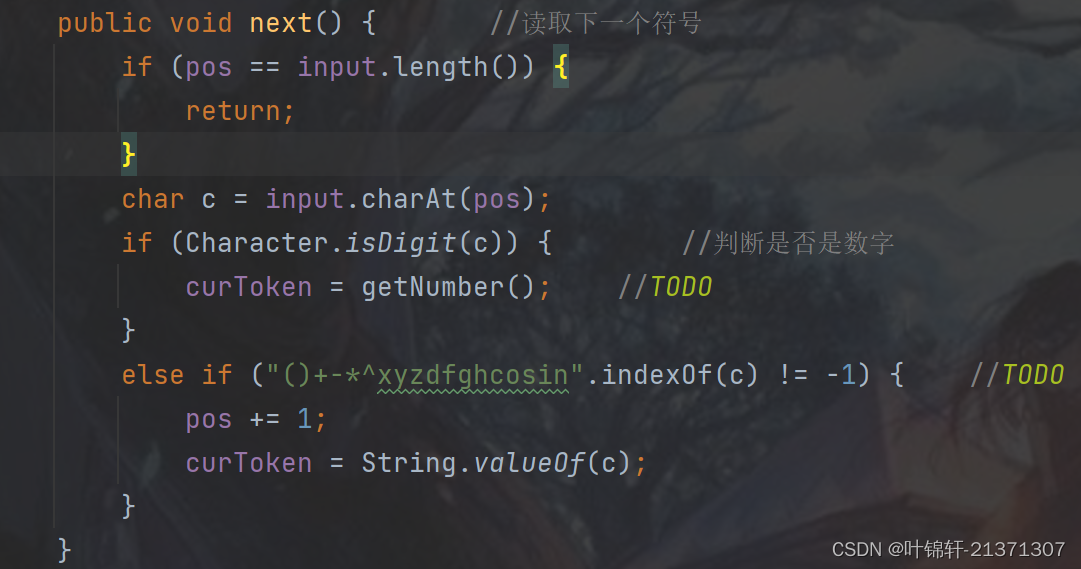

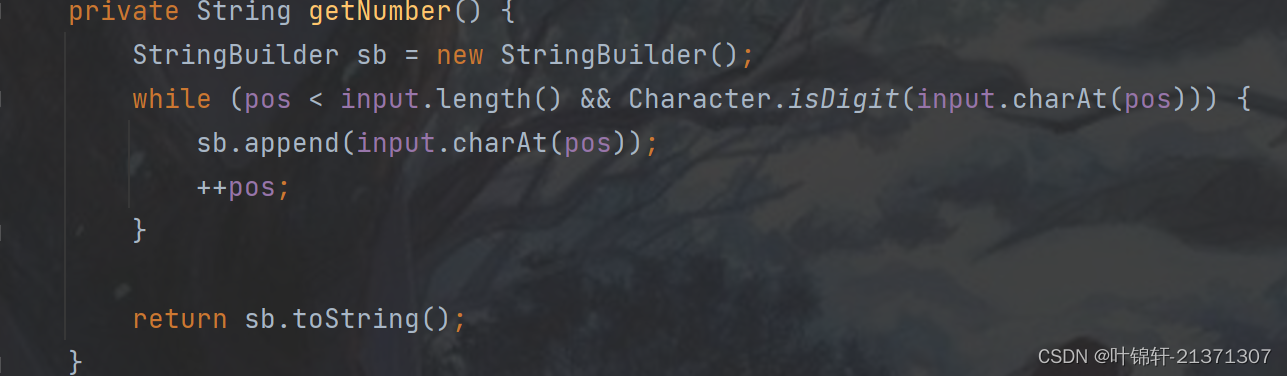
Parser--解释器
Parser就是利用了第一次作业训练中的写法,将Lexer中拆解的元素选取后分为三个部分---parseExpr,parseTerm,parseFactor。每一个部分都按照题目中的文法进行解析。
parseExpr--解析表达式
因为表达式由各个项组成,项之间用+号连接,因此按此格式进行解析,将每个项解析出来,每个+之间调用parseTerm。注意表达式可能会有符号表示整个表达式的正负,因此需要特殊处理。(部分代码如下)
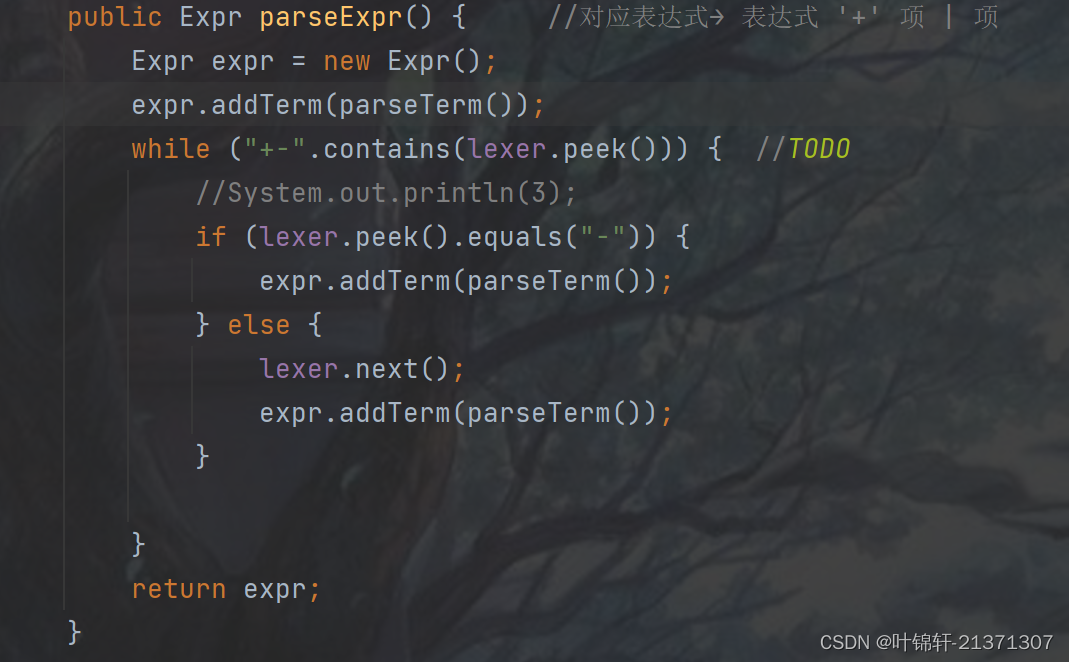
parseTerm--解析项
项由各个因子组成,各个因子之间用*连接,据此将每个因子解析出来,每个*之间调用parseFactor

parseFactor--解析因子
因子分为系数,变量x/y/z(以及它们的指数),指数,三角函数,(表达式),因此分为这几个部分讨论
遇到括号(时将因子解析成表达式
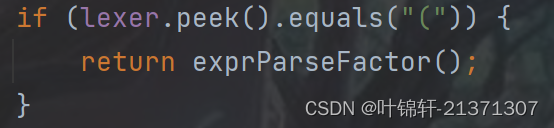
遇到 d时解析成指数形式

遇到x/y/z时解析成变量形式

遇到s/c解析成三角函数形式

这样递归下降处理后完成了大部分内容
Term-->Tansform:项的计算
项由各个因子组成之后还不能满足题目要求的输出格式,项中的表达式因子需要拆去括号变成系数,变量或者三角函数形式,因此还需要一个计算的步骤,因此我设计了一个Terms 的calc 方法将其中因子进行计算,最后形成(系数)*(变量^指数)*(三角函数^指数)的规范形式

此外,经过项中表达式计算后还是未能满足输出要求,还需要处理导数,本次导数有如下要求

再进行上述calc计算后,每一个terms都变成了标准的Tansform 形式,导数其实在Tansform 中做成类似于一个标志flag ,当有这个标志的时候进行导数运算,因此我再创立operation 函数进行导数的运算

toString
最后所有的形式都变成了输出要求的格式,此时就可以进行输出了。输出时也采用递归下降的思路,expr是由Tansform+Tansform+……+Tansform组成,因此可以这样表达:

tansform形式是(系数)*(变量^指数)*(三角函数^指数),根据这输出即可
一些细节
三角函数内部也是一个表达式,可以调用Lexer+Parse 进行解析
自定义函数定义的时候也会遇到求导形式,题目要求:

因此需要在函数带入实参之前就把指数形式进行处理了,我的理解是函数等号右边也是表达式,因此我选择在输入的时候就把它当成表达式处理成标准式子

架构过程
hw1
在第一次作业时候大体架构就是这样,后面两次迭代的时候我并未对其进行修改,只是按照要求增量进行一些完善
hw2
第二次作业增加了多层括号,自定义函数和三角函数。
多层函数因为我采用的是递归下降,因此并不需要进行处理已经可以实现。
自定函数只是输入形式上发生了改变,然后在预处理的时候就把函数替换成第一次作业要处理的表达式形式。
三角函数是项中多了一个因子,因此我多创建了一个类,在解析的时候多判断一下是否是这个因子,往后的处理都增加一下这个因子的处理即可,处理形式和之前都很类似。
hw3
第三次作业我认为是最简单的一次作业,只增加了求导的计算,而对于这个我的处理本质上也是加上一个特判,如果碰到d,则这个项的flag变成1,往后计算的时候按照题目要求的规则将其进行相应的计算就可以。(部分代码如下)

自定义函数代换的时候会遇到嵌套带入的问题,因此此时需要在定义时将x/y/z换成一个形式。我选择换成A/B/C

至此,所有的问题都得以解决!第一单元完成。
架构优缺点分析
这个架构是我第一周花费一个通宵想出来的,我个人认为还是挺符合面向对象的思想,每个处理过程都封装成一个个类,交给相应的方法进行处理,各司其职。
但是缺点也很明显,虽然大体的结构挺好,但是有些具体计算过程非常冗长,还是有许多面向过程的影子,这从后面度量分析也可以看出,因此还需要改善。还有就是我的优化没有做的很完美,导致输出较为冗长。
四.代码复杂度分析
代码规模
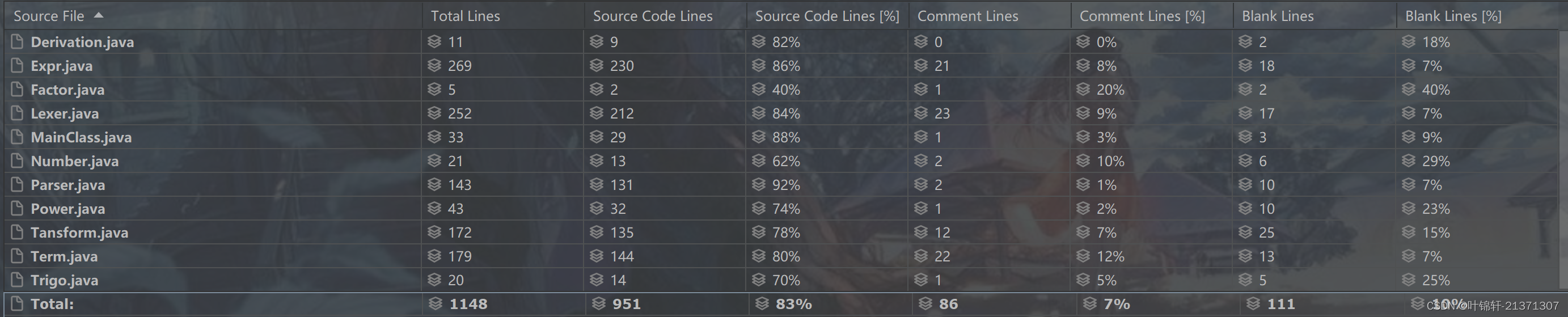
可以看出重心放在Lexer,Expr和Parser上。
类的度量分析

可以看出在平均复杂度方面,Lexer,Expr,Term,Parser都比较高,可能是我还保留一定面向过程的思想,因此方法内写的非常复杂,这几个方法的加权复杂度也很高,也需要注意。
下次架构的时候,一些具体复杂的计算其实可以再创建一个类,这样可以减少面向过程的缺点。
方法的度量分析
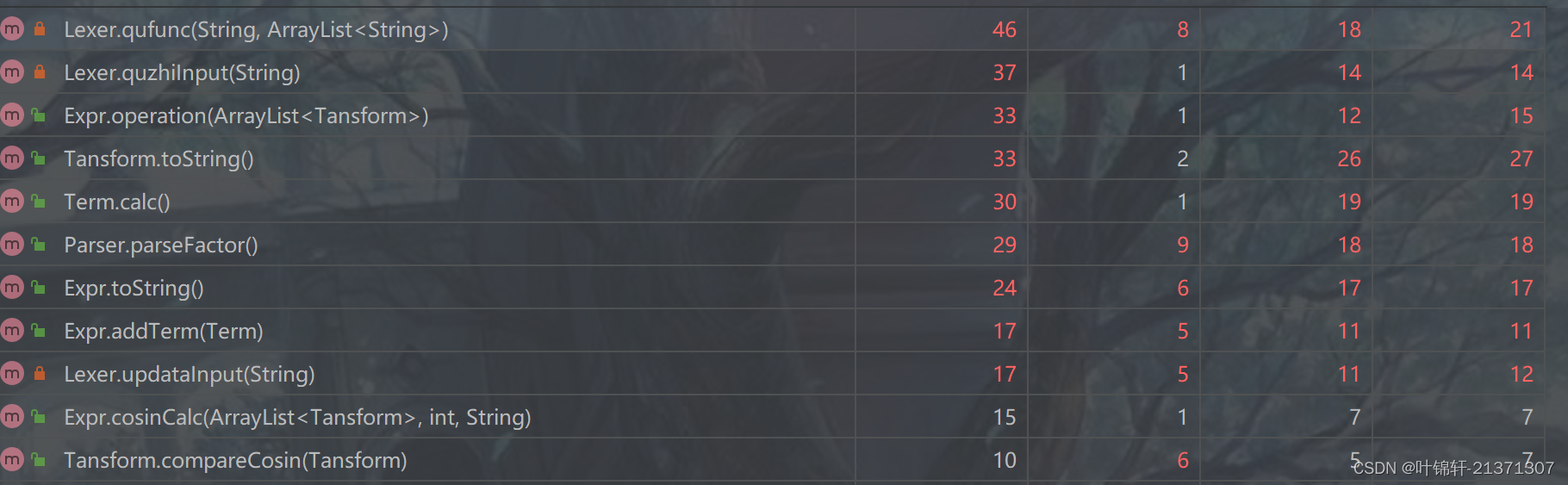
我只截取了有红色标识的地方,可以看出是主要集中在Lexer,Expr,Term,Parser中的几个方法。在计算,合并和分析的过程中不可避免的出现了面向过程的写法,因此将方法写的复杂。
五.Bug分析及hack策略
hw1
第一次作业的强测寄了两个点,是因为-+-,---,+-+的预处理没有干净,因此在进行元素解释分析的时候识别错误,在预处理时提前进行处理即可。在互测时我也是因为这个问题被人hack了
hw2
第二次作业崩的特别惨(哭,因此这次作业完成的很快,而且三角函数需要进行一定的合并优化,因此我对自己输出的表达式进行处理使其尽可能短,但是因为没有做到全面的测试因此在优化后漏洞百出,不仅强测错了8个点,互测还被🔪烂了。给我了一个特别大的警示。
总共发现了四个bug
第一:对0次方的处理没有到位,应该对表达式的0次方直接变为1,而之前代码确还保留表达式
第二:+sinx,+cosx等无法处理,因为我处理统一是用递归下降碰到*变成因子,因此解决方法是将+sinx之类的变成+1*sinx。
第三:函数处理的时候碰到有空格就无法识别,此时应该将空格删去再处理
第四:优化性能的时候想把1*删去,但是最后碰到例如8881*x这类以1结尾*因子的时候删去1*导致错误
hw3
第三次作业经历上一次作业的教训,我代码编写的谨慎许多,而且有评测机进行全面的测试,因此bug很少,强测没有问题,互测只被人找到了一个bug。因为表达式中当有括号时,里面也算对表达式进行处理,但是在处理过程中最开头的+号未考虑进去,导致后面数字录进去时识别到正号出错,因此加了一个正号的判断。
总结:
bug出现的地方都是一些特别小的细枝末节,比如像零次方,+-+,开头符号等等一些特殊的输入,这种地方需要特判,因此有时没有考虑那么全面就会导致漏洞百出。当然,我hack其他人的时候也是按照这个思路,考虑一些这样的细节看看对方有没有想到,正确率还不低。
六.心得体会
第一单元的学习可谓痛苦不堪,我觉得其中最难的便是跳出面向过程的舒适圈,利用对我来说完全不熟悉,或者说十分别扭的面向对象对的方法完成较大规模的工程。这样的转变在第一周体会的特别明显,最开始设计时我还抱着侥幸的心理,用面向过程的方法企图将作业完成,结果写的举步维艰,最后无奈只能重构,顺便记录一下人生第一次通宵hhh,从晚上9点到早上8点花11个小时完成重构。当写完的那一刻,真是心酸又自豪。往后的两次作业,因此第一次通宵迭代设计的好处并没有花费很长时间,在第一次作业基础上简单迭代一下即可完成。这更让我体会到了好架构的重要性。
这一个月的学习,我总结了一下几点经验:其一,在动手之前一定要较为详细的想好完整的架构,并且长远的想一下自己的架构扩展性强不强,是不是只针对这一次作业进行的开发,能否进行后续的迭代。千万不要像我第一次那样胡乱动手最后心酸重构。其二,评论区和往届学长的思路和博客可以借鉴,但是不要盲目跟随,一定要结合自己的结构进行学习,不然出现的四不像会让人欲哭无泪。其三,优化一定一定要慎重,每一步的优化,都会多出许多意想不到的bug,在我第二次作业进行优化后各种Bug出现,导致后面强测寄的很惨。最后,测试要做全面,如果你想全面的优化,那么更加全面的测试必不可少,本人不太会写评测机,因此第一次作业和第二次作业都是手动构造数据找Bug,所以强测都没有全部过。第三次作业借了同学的评测机进行较为几千组较为全面的测试,因为测试比较全面,第三次强测就比较成功,可见测试的重要性。
最后,回顾这一个月来oo的学习,喜忧参半,一千多行的代码量还是很有成就感的,特别感谢学长和助教细心的指导,希望下一次的作业能写的更熟练,架构更完善。















 6157
6157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









