







101 在学生表 Student 的系别 (Sdept) 属性中查询信息系 (IS) 、数学系 (MA) 和计算机系 (CS) 的学生姓名 (Sname) 和性别 (Ssex) ,正确的命名格式应为:B
SELECT Student FROM Sname, Ssex WHERE Sdept IN (‘IS’, ’MA’, ‘CS’)
SELECT Sname, Ssex FROM Student WHERE Sdept IN (‘IS’, ’MA’, ‘CS’)
SELECT Sname, Ssex FROM Student WHERE Sdept (IS, MA, CS)
SELECT Sname, Ssex FROM Student WHERE Sdept LIKE IS, MA, CS
select后写上需要选择的列名,from表名,where后写选择条件,要求查询这三个系的学生使用in进行选择,in后面写系名的可能值,如果查询到的数据系名在可能值中则被选中
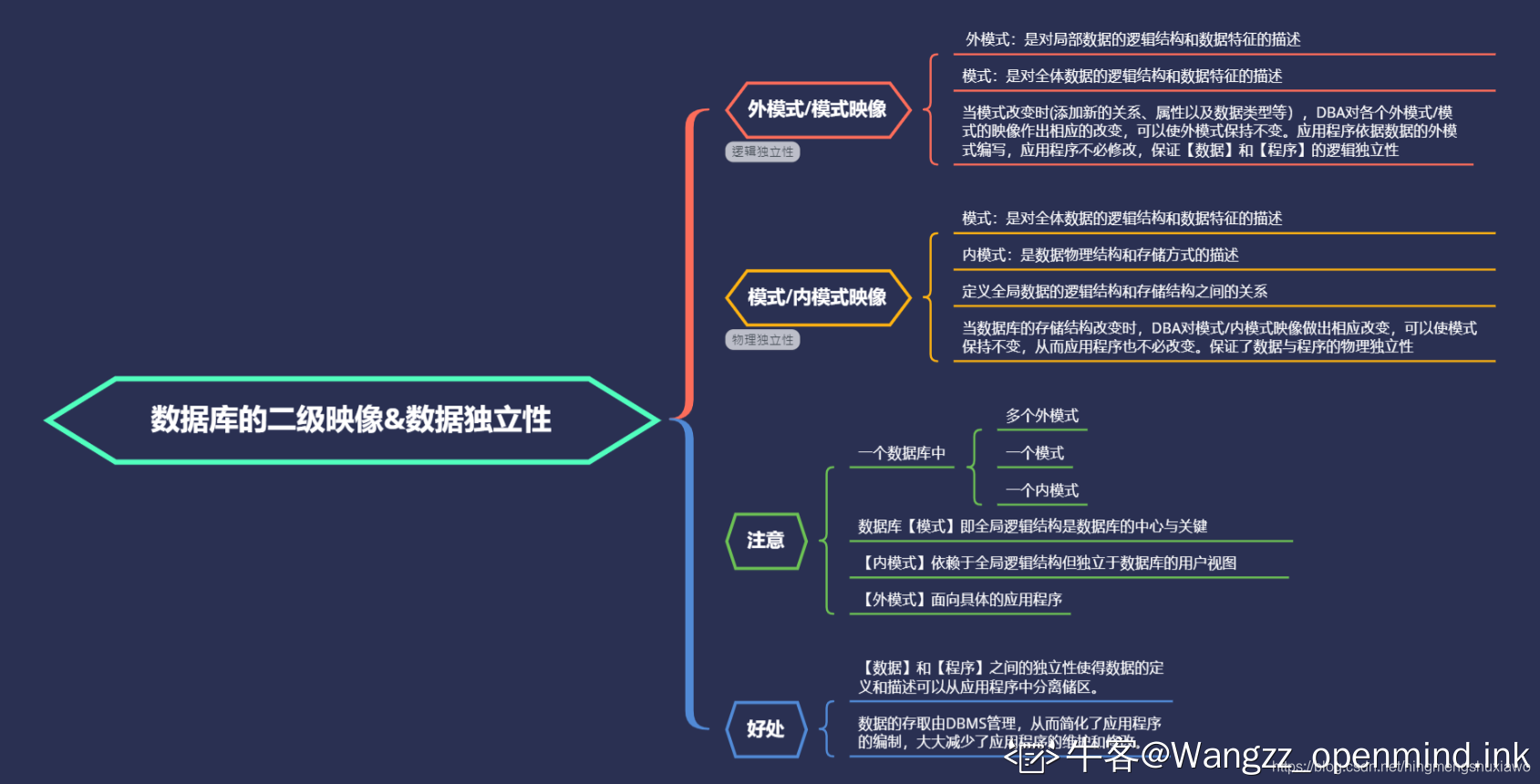
102 在数据库三级模式结构中,描述数据库中全体逻辑结构和特性的是(D )
外模式
内模式
存储模式
模式
外模式面向应用程序。模式是逻辑结构。内模式是物理结构
103 消除了部分函数依赖的1NF的关系模式,必定是( B)
1NF
2NF
3NF
4NF
[解析] 第一范式要求元组的每个分量必须是不可分的数据项。
第二范式要求在第一范式基础上每一个非主属性完全函数依赖于码。
第三范式要求在第二范式基础上每一个非主属性不传递依赖于码。
Boyce-Codd范式要求在第一范式基础上对于每一个非平凡的函数依赖X-Y都有X包含码。
第四范式要求在第一范式基础上对于每一个非平凡的多值依赖X→→Y(Y不是X的子集)都有X包含码。
因此,消除了部分函数依赖的1NF关系模式属于2NF。
104 下列关于数据库安全性的类型和一般措施的叙述中,哪些是正确的( ABD )
数据库的安全性威胁会导致丧失或削弱数据库的完整性、可用性、机密性
一般DBMS包含一个数据库安全和授权子系统,用于负责数据库的安全性功能以避免发生未授权的访问
自主安全性机制用于对多级安全性进行控制
基于角色的访问控制可用于数据库安全性控制
数据库安全性机制:
- 自主安全性机制:通过权限在用户之间传递,使用户自己来管理数据库;(权限)
- 强制安全性机制:通过对数据和用户强制分类,使不同类别的用户能访问到不同类型的数据;(数据分类)
- 推断控制机制:防止推断出不该被知道的数据;(推断)
- 数据加密存储机制:对数据加密。(加密)
多级安全是指:给每一类数据设定一个安全级别,同时给每一类用户也设定安全级别,以此来控制什么级别的数据能被什么级别的用户访问。
105 关于索引,选项中说法错误的是( C )
建立索引的目的是提高检索数据库的速度。
索引会降低数据库的写入性能。
索引越多数据库检索越快。
应该在经常查询或排序的列上创建索引。
B:修改性能和检索性能是互相矛盾的;当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。
C:对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
106 并发事务的交叉执行破坏了事务的(B)。
原子性
隔离性
一致性
永久性
对 数据库 的操作都是在事务中进行的。
事务是指一组相互依赖的操作行为。事务中的操作是不可分割的工作单元,由一组在业务逻辑上相互依赖的SQL语句组成,有ACID特征。
Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败。
Consistency(一致性):只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初状态。
Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。
Durability(持久性):事务结束后,事务处理的结果必须能够得到固化。
数据库中有多个事务同时存在,就是事务并发,此时就不能保证事务隔离性,SQL-92定义了事务隔离级别,描述了给定事务的行为对其它并发执行事务的暴露程度,或者说是一个事务必须与其它事务进行隔离的程度。隔离级别由低到高为:
Read Uncommitted,Read Committed,Repeatable Read, Serializable
隔离级别越高,越能保证数据的完整性和一致性,但对并发性能的影响也越大。
http://www.2cto.com/database/201501/373684.html
107 下面有关sql绑定变量的描述,说法错误的是?D
绑定变量是指在SQL语句中使用变量,改变变量的值来改变SQL语句的执行结果
使用绑定变量,可以减少SQL语句的解析,能减少数据库引擎消耗在SQL语句解析上的资源
使用绑定变量,提高了编程效率和可靠性,减少访问数据库的次数
使用绑定变量,查询优化器会预估的比字面变量更加真实
D,绑定变量被使用时,查询优化器会忽略其具体值,因此其预估的准确性远不如使用字面量值真实
108 现有表book,主键bookid设为标识列。若执行语句:select * into book2 from book, 以下说法正确的是?AD
若数据库中已存在表book2, 则会提示错误。
若数据库中已存在表book2, 则语句执行成功,并且表book2中的bookid自动设为标识。
若数据库中不存在表book2, 则语句执行成功,并且表book2中的bookid自动设为主键。
若数据库中不存在表book2, 则语句执行成功,并且表book2中的bookid自动设为标识。
select into from 和 insert into select都是用来复制表,两者的主要区别为: select into from 要求目标表不存在,因为在插入时会自动创建。insert into select from 要求目标表存在
109 对关系模型叙述错误的是(D)
建立在严格的数学理论、集合论和谓词演算公式的基础之上
微机DBMS绝大部分采取关系数据模型
用二维表表示关系模型是其一大特点
不具有连接操作的DBMS 也可以是关系数据库系统
有联系才有关系,所以关系模式必须要能够连接
110 下列说法中,不属于数据模型所描述的内容是 C 。
数据结构
数据操作
数据查询
数据约束
数据模型的组成要素有:
1.数据结构,描述数据库的组成对象以及对象之间的联系,数据结构是所描述的对象类型的集合,是对系统静态特征的描述
2.数据操作,是指对数据库中各种对象的实例允许执行的操作的集合,主要有查询和更新。
3.数据的完整性约束条件,是一组完整性规则的集合。完整性规则是给定的数据模型中数据及其联系所具有的之约和依存规则,用以限定符合数据模型的数据库状态以及状态的变化,以保证数据的正确、有效、相容。
111 在关系模式DB中,任何二元关系模式的最高范式必定是 ____D
1NF
2NF
3NF
BCNF
范式是“符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度”。
1NF:每个关系r的属性值为不可分的原子值
2NF:满足1NF,非主属性完全函数依赖于候选键(左部不可约)
3NF:满足2NF,消除非主属性对候选键的传递依赖
BCNF:满足3NF,消除每一属性对候选键的传递依赖
112 在关系模型中,每一个二维表称为一个?A
关系
属性
元组
主码(键)
元组是关系数据库中的基本概念,关系是一张表, 表中的每行(即数据库中的每条记录)就是一个元组 ,每列就是一个属性。 在二维表里,元组也称为记录。
113 关于视图和游标,选项中说法错误的是( A)
视图可以进行增改查等操作,通常视图是一个表或者多个表的行或列的子集,对视图的修改会影响到基本表
相比多表查询,使用视图使得我们获取数据更加容易
游标可以定在查询结果集的特定行,也可以从结果集的当前行检索一行或多行
通常我们并不使用游标,但是需要逐条处理数据的时候,游标显得十分重要
视图是一个或多个基本表或视图导出的表,是一个虚表,数据库中只存放视图的定义,不存放视图对应的数据,对视图的操作最终都转化为基本表的操作。 A在定义上错了。
视图数据是表数据的一个体现,数据是不可更改的,表数据更新的时候,视图数据会自动更新。
114 mysql数据库中一张user表中,其中包含字段A,B,C,字段类型如下:A:int,B:int,C:int根据字段A,B,C按照ABC顺序建立复合索引idx_A_B_C,以下查询语句中使用到索引idx_A_B_C的语句有哪些?ABD
select *from user where A=1 and B=1
select *from user where 1=1 and A=1 and B=1
select *from user where B=1 and C=1
select *from user where A=1 and C=1
复合索引可以只使用复合索引中的一部分,但必须是由最左部分开始,且可以存在常量。
因复合索引为idx_A_B_C,所以查询条件只能是在a,ab,abc,ac才算 使用到索引idx_A_B_C
复合索引: Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。 例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 当最左侧字段是常量引用时,索引就十分有效
115 关于数据库,下列描述中,正确的是AD
having 和where都是用来筛选用的,having是筛选组,而where是筛选记录
在sql中,关键字delete表示直接删除表,而drop表示删除表中数据
主键是能确定一条记录的唯一标识,不能有重复,允许为空
在数据库设计中,一个多对多的关系可通过一个中间表分为两个一对多的关系
数据库设计的三大范式当中,第二范式要求一个数据库表中不包含已在其他表中包含的非主关键字信息
第二范式:首先是 1NF,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
第三范式(3NF):首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
1、delete:删除表中的行,用法:delete from 表明 where 列名=值。
2、drop:删除整个表,drop table 表名。
3、truncate:删除表中的数据,相当于delete不加where条件。
116 在一个采用(A)数据库体系结构的网络数据库应用系统中,计算机C上运行着DBMS软件和应用程序,并存有所有用户数据,其余各节点作为终端通过通信线路向计算机C发出数据库应用请求。
集中式
主从式
客户机/服务器
分布式
因为数据库和应用程序均储存在一台计算机上,故为集中式体系结构; 如果数据库存放在服务器上,应用程序存放在客户机上,则为主从式(客户机/服务器式)体系结构; 如果数据库物理上存放在不同的场地,则为分布式体系结构

117 下列哪一个Transact-SQL语句能够实现收回user2查询基本表T的权限( D)。
REVOKE UPDATE ON T
GRANT SELECT ON T TO user2
DENY SELECT ON T TO user2
REVOKE SELECT ON T FROM user2
–回收建表、改表、删表、查表权限
REVOKE CREATE ON T FROM user2;
REVOKE DROP ON T FROM user2;
REVOKE ALTER ON T FROM user2;
REVOKE SELECT ON T FROM user2;
–回收表记录的增删改权限
REVOKE INSERT ON T FROM user2;
REVOKE UPDATE ON T FROM user2;
REVOKE DELETE ON T FROM user2;
–查看权限
SHOW GRANTS FOR user2;
–扩展一下,给用户加权限是:
GRANT CREATE ,SELECT,ALTER,DROP ON T TO user2;
–也可以单独赋予权限
GRANT SELECT ON T TO user2;
118 数据库中事务隔离分为4个级别,其中允许“不可重复读”的有?BC
SERIALIZABLE
READ COMMITTED
READ UNCOMMITTED
REPEATABLE READ

119 若系统在运行过程中,由于某种硬件故障,使存储在外存上的数据部分损失或全部损失,这种情况称为( C )。
事务故障
系统故障
介质故障
运行故障
数据库常见的四种故障
(1)事务内部的故障:事务内部故障可分为预期的和非预期的,其中大部分的故障都是非预期的。预期的事务内部故障是指可以通过事务程序本身发现的事务内部故障; 非预期的事务内部故障是不能由事务程序处理的,如运算溢出故障、并发事务死锁故障、违反了某些完整性限制而导致的故障等。
(2)系统故障:系统故障也称为软故障,是指数据库在运行过程中,由于硬件故障、数据库软件及操作系统的漏洞、突然停电灯情况,导致系统停止运转,所有正在运行的事务以非正常方式终止,需要系统重新启动的一类故障。这类事务不破坏数据库,但是影响正在运行的所有事务。
(3)介质故障:介质故障也称为硬故障,主要指数据库在运行过程中,由于磁头碰撞、磁盘损坏、强磁干扰、天灾人祸等情况,使得数据库中的数据部分或全部丢失的一类故障。
(4)计算机病毒故障:计算机病毒故障是一种恶意的计算机程序,它可以像病毒一样繁殖和传播,在对计算机系统造成破坏的同时也可能对数据库系统造成破坏(破坏方式以数据库文件为主) 。
120 关系数据模型的基本数据结构是(D)
树
图
索引
关系
关系数据模型的逻辑结构是关系
层次数据模型的逻辑结构是树
网状数据结构的逻辑结构是图
121 为了提高数据库的性能,需要针对系统设计基准测试进行压力测试,那么进行压力测试时需要考虑以下哪些指标(BCD)
可扩展性
响应时间
并发性
吞吐量
122 以下不是SQL语句中的聚合函数的是? D
SUM
AVG
COUNT
DISTINCT
1 求和函数——SUM();
2. 计数函数——COUNT();
3.最大/最小值函数—MAX()/MIN();
4.均值函数——AVG();
DISTINCT 用于返回唯一不同的值。
聚合函数就是将多个数据统计为一个结果
123 下述SQL语句中,起修改表中数据作用的命令动词是()D
AETER
CREATE
INSERT
UPDATE
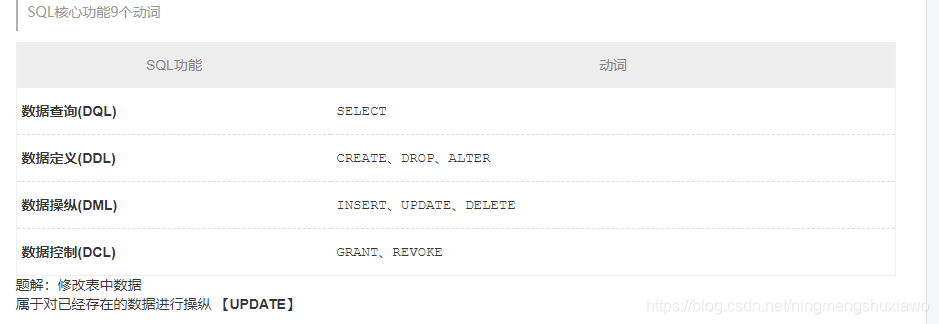
124 设有学生关系student(sno,sname,sdept,mname),表示学号,姓名,系,系主任。该关系中存在如下函数依赖:则关系student属于( B )范式?
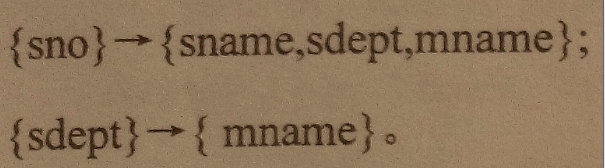
1NF
2NF
3NF
BCNF
满足第一范式:因为每一行或者列只有一个值或者属性。
满足第二范式:是因为主键只有一个
不满足第三范式:是因为在第一个表中含有第二个表的非主键属性。
存在函数传递依赖因此不是3NF
2NF的标准是非主属性完全依赖于主属性
3NF的标准是非主属性不依赖于其他非主属性,显然不满足3NF
125 当关系 S 自然联接时,能够把 S 原该舍弃的元组放到结果关系中的操作是 ( )
左外连接
右外连接
外部并
外连接
1、内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符)。包括相等联接和自然联接。
内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。例如,检索 students和courses表中学生标识号相同的所有行。
2、外联接。外联接可以是左向外联接、右向外联接或完整外部联接。 在 FROM子句中指定外联接时,可以由下列几组关键字中的一组指定:
1)LEFT JOIN或LEFT OUTER JOIN
左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
2)RIGHT JOIN 或 RIGHT OUTER JOIN
右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
3)FULL JOIN 或 FULL OUTER JOIN
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
3、交叉联接
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。 FROM 子句中的表或视图可通过内联接或完整外部联接按任意顺序指定;但是,用左或右向外联接指定表或视图时,表或视图的顺序很重要。有关使用左或右向外联接排列表的更多信息,请参见使用外联接。
126 一般情况,企业会将从一个供应商处一次所进的多种货物办理一次入库,因此设计了关系模式:入库单(单号, 日期, 库房, 供应商,物品, 数量, 金额),下列说法正确的是_____A____。
不满足第2范式;
满足第2范式但不满足第3范式;
满足第3范式;
都不对。

127 关系模式中各模式之间的关系为 (C)。

128 athletes 表包含运动员姓名,年纪和代表国家。下面哪个查询可以找出代表每个国家最年轻的运动员情况?A
SELECT name, country, age FROM athletes WHERE (country, age) IN (SELECT country, min(age) FROM athletes GROUP BY country)
SELECT name, country, age FROM athletes WHERE (country, age) IN (SELECT min(age), country FROM athletes GROUP BY country)
SELECT name, country, age FROM athletes WHERE (country, age) IN (SELECT country, min(age) FROM athletes) GROUP BY country
SELECT name, country, age FROM athletes WHERE age IN (SELECT country, min(age) FROM athletes GROUP BY country)
A:是正确的
B:嵌套查询的子查询列名顺序和in之前的返回列名不一致
C:group by是跟在where后面的
D:嵌套查询的子查询是有两个返回值,而In之前只有一个age所以数据只会返回age不会返回国家与题目不符.
select后面写需要选择的列名,from表名,where进行条件选择
使用国家以及年龄进行筛选,要求这个国家和年龄是这个国家里年龄最小的
使用in进行筛选,in后面的数据应为每个国家年龄最小运动员数据,因此从运动员表中选择出国家及最小年龄,以国家进行分组,A正确
B由于in后面选择出表的列顺序与in前面查找数据的顺序不同无法得到该结果
C将以国家分组放在括号外面导致in后面括号中select语法错误,并且不符合题意
D只以年龄进行in筛选无法确定是哪个国家的运动员,无法得到正确结果
129 Web程序通常采用MVC架构来设计,数据库相关操作属于(A)?
Model
Controller
都不属于
View
MVC框架是三层架构:模式层、视图层、控制层
模式层:表示企业数据和业务逻辑,是应用程序的主体部分;
视图层:是用户看到的并与之交互的界面;
控制层:接收用户的输入并调用模型和视图去完成用户的需求;
属于和数据库相关操作是在模式层。
130 SQL基本表的创建中是通过哪个子句实现实体完整性规则的。
外键子句
主键子句
检查子句
NOT NULL
实体完整性规则:这条规则要求关系中元组在组成主键的属性上不能有空值.如果出现空值,那么主键值就起不了唯一标识元组的作用.
131 用命令()可以查看mysql数据库中user表的表结构?ABD
desc user;
show create table user;
show columns for user;
describe user;

132 相对于非关系模型,关系数据模型的缺点之一是( A ) 。
存取路径对用户透明,需查询优化
数据结构简单
数据独立性高
有严格的数学基础
BCD均为优点,只能选择A,A也很好理解,因为我们查询的时候是不知道数据的存储路径和方式,所以需要注意查询优化。
133下列聚合函数中不忽略空值 (null) 的是()(2001年10 月全国卷) C
SUM (列名)
MAX (列名)
COUNT ( * )
AVG (列名)
在统计字段没有满足条件的数值时,只有count()返回数值0或者 其他,其他聚合函数会返回null值
134 一个1:n联系可以转换为一个独立的关系模式,关系的码为(C)。
实体的码
各实体码的组合
n端实体的码
每个实体的码
一个联系转化为一个关系模式,与该联系相连的各实体的码以及联系
的属性转化为关系的属性,该关系的码则有三种情况:
若联系为1:1,则每个实体的码均是该关系的后选码。
若联系为1:n,则关系的码为n端实体的码。
若联系为m:n,则关系的码为诸实体码的组合。
135 Mysql sql注入中使用延时注入时常用的语句是(BC)
wait for delay ‘0:0:10’
sleep(5)
benchmark(100000000,md5(1))
union select
利用Sleep()或Benchmark()等函数让MySQL执行时间变长,并结合条件判断语句IF(expr1,expr2,expr3),通过页面的响应时间长短来判断语句返回的值是TRUE还是FALSE👉从而猜解一些未知的字段。
WAITFOR不是SQL的标准语句,所以它只适用于SQL Server数据库。
136 淘宝网上的信息处理系统属于(C)
B/S 模型
C/S 模型
分布式模型
面向对象模型
C/S模型:客户端/服务器模型
所有你有客户端的应用都属于这一模型,比如英雄联盟什么的
B/S模型:浏览器/服务器模型
通过http协议,用网页就能和主服务器交互实现应用,比如网页在线游戏什么的
分布式:把程序拆分成不同的服务器分别进行处理,然后组合处理结果传回用户用于逻辑复杂应用,可以分担服务器压力,业务任意组合
面向对象模型:封装,继承,模块化
比较新的数据模型,优势劣势都很明显,维护比较困难,所以现阶段适用于逻辑特定的应用如医疗,工程项目。
单单说淘宝网上的信息处理,肯定是不同客户端,不同业务都有不同服务器负责,中间件组装整理,返回。选C
137 使用 CREATE SCHEMA 语句建立的是(A)。
数据库
表
视图
索引

138 关系型数据库创建表都有主键。以下对主键描述正确的是:c
主键是唯一索引,唯一索引也是主键
主键是一种特殊的唯一性索引,只可以是聚集索引
主键是唯一、不为空值 的列
对于聚集索引来说,创建主键时,不会自动创建主键的聚集索引
不同的存储引擎对于主键索引的实现是不一样的。就mysql而言,Innodb存储引擎的实现方式是聚集索引,MyISAM存储引擎的实现方式就不是聚集索引。
139
定义学生、教师和课程的关系模式STC(SNO,SN,SA,TN,CN,G),其中的六个属性分别为学生的学号、姓名、年龄、教师的姓名、课程名以及学生的成绩,则该关系为( A )。
第一范式
第二范式
第三范式
BCNF范式
解析 : 【解析】范式是符合某一种级别的关系模式的集合。关系数据库中的关系必须满足一定的要求,满足不同程度要求的为不同范式。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、Boyce-Codd范式(BCNF)、第四范式(4NF)和第五范式(5NF)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。 第一范式:主属性(主键)不为空且不重复,字段不可再分(存在非主属性对主属性的部分依赖)。 第二范式:如果关系模式是第一范式,每个非主属性都没有对主键的部分依赖。 第三范式:如果关系模式是第二范式,没有非主属性对主键的传递依赖和部分依赖。 BCNF范式:所有属性都不传递依赖于关系的任何候选键。 题目中关系模式STC满足第一范式,但不满足第二范式。故本题答案为A选项。
只要一个属性或几个属性的组合能确定所有其他属性都可以是候选码,简称码,主码从候选码里面选取 学号+教师名也可以是主码
第一范式,所有列必须是原子项,即不可分割,不能存在数组集合等。 第二范式,在满足第一范式的基础上,所有非主键列必须完全依赖于主键,如从学生的学号可以推算出学生的姓名 年龄,但是却无法推断出老师和课程名。因此不满足第二范式。 第三范式:要求非主键列与主键直接相关,不能相互依赖,比如存在年龄分析等与年龄有关的列。
码是唯一标识实体的属性或者属性组
140 设关系 R 和 S 的属性个数分别为 r 和 s ,则 (R×S) 操作结果的属性个数为 ( A)
r+s
r-s
r×s
max(r,s)

是问属性个数,不是元组个数
141 关系数据模型的三个组成部分中,不包括(C)
数据结构
完整性规则
恢复
数据操作
关系模型的三个组成部分,是指关系数据模型的数据结构、
关系数据模型的操作集合、
关系数据模型的完整性约束
数据模型
数据模型(Data Model)是数据特征的抽象。数据(Data)是描述事物的符号记录,模型(Model)是现实世界的抽象。数据模型从抽象层次上描述了系统的静态特征、动态行为和约束条件,为数据库系统的信息表示与操作提供了一个抽象的框架。数据模型所描述的内容有三部分:数据结构、数据操作和数据约束。
概念模型
概念模型(Conceptual Data Model),是一种面向用户、面向客观世界的模型,主要用来描述世界的概念化结构,它是数据库的设计人员在设计的初始阶段,摆脱计算机系统及DBMS的具体技术问题,集中精力分析数据以及数据之间的联系等,与具体的数据管理系统(Database Management System,简称DBMS)无关。概念数据模型必须换成逻辑数据模型,才能在DBMS中实现。
逻辑模型
逻辑模型(Logical Data Model),是一种面向数据库系统的模型,是具体的DBMS所支持的数据模型,如网状数据模型(Network Data Model)、层次数据模型(Hierarchical Data Model)等等。此模型既要面向用户,又要面向系统,主要用于数据库管理系统(DBMS)的实现。
物理模型
物理模型(Physical Data Model),是一种面向计算机物理表示的模型,描述了数据在储存介质上的组织结构,它不但与具体的DBMS有关,而且还与操作系统和硬件有关。每一种逻辑数据模型在实现时都有其对应的物理数据模型。DBMS为了保证其独立性与可移植性,大部分物理数据模型的实现工作由系统自动完成,而设计者只设计索引、聚集等特殊结构。
142 关系R和S进行自然连接时,要求R和S含有一个或多个公共(D)
元组
行
记录
属性
自然连接(Natural join)是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且在结果中把重复的属性列去掉。而等值连接并不去掉重复的属性列
143 数据库系统达到了数据独立性是因为采用了 (D )。
层次模型
网状模型
关系模型
三级模式结构
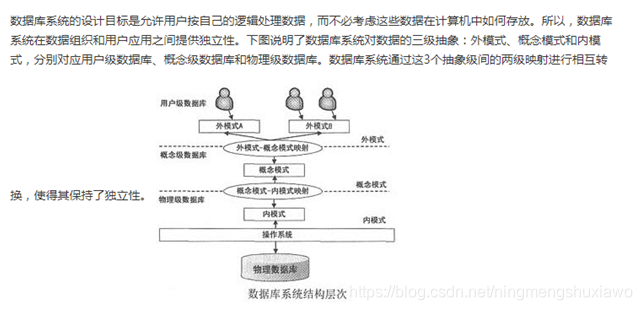
三级模式结构,它包括外模式、概念模式、内模式,有效地组织、管理数据,提高了数据库的逻辑独立性和物理独立性。用户级对应外模式,概念级对应概念模式,物理级对应内模式,使不同级别的用户对数据库形成不同的视图。所谓视图,就是指观察、认识和理解数据的范围、角度和方法,是数据库在用户“眼中"的反映,很显然,不同层次(级别)用户所“看到”的数据库是不相同的。
144 设有一个关系: DEPT ( DNO , DNAME ),如果要找出倒数第三个字母为 W ,并且至少包含 4 个字母的 DNAME ,则查询条件子句应写成 WHERE DNAME LIKE (B )。
’_ _ W _ %’
’_ % W _ ’
’ W _ ’
’ W _ %’
%和_都为通配符,而“%”表示0个或多个字符,“ _ ”则表示一个字符,查倒数第三个字符W,所以应该是W_ ,但是要求要至少包含4个字符,所以在W前面添加%,又必须有一个所以就多加了一个""。
145 视图设计一般有 3 种设计次序,下列不属于视图设计的是 B 。
自顶向下
由外向内
由内向外
自底向上
通常有如下几种方法:
1、自顶向下。先全局框架,然后逐步细化
2、自底向上。先局部概念结构,再集成为全局结构
3、由里向外。先核心结构,再向外扩张
4、混合策略。1与2相结合,先自顶向下设计一个概念结构的框架,再自底向上为框架设计局部概念结构
146 设有事务T1和T2,其并发操作顺序如下所示(其中 ①②③④⑤ 表示时间从前到后的顺序) C

不一致分析
丢失更新
读了“脏数据”
写错误
读取了其他事务未提交的数据(事务回滚了)
147 设有两个事务T1、T2,其并发操作如图所示,下面评价正确的是( B)? (改A为X)

该操作不存在问题
该操作丢失修改
该操作不能重复读
该操作读“脏”数据
丢失修改:原本两个事务的目的是T1先把A的值加10,A变为58。然后T2把A的值再减2,即A变成56。但是根据题目中的执行顺序,A的值变为48-2=46,即T2的修改覆盖了T1的修改,这种现象叫做丢失修改。
不可重复读:不可重复读是指事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。
读"脏"数据:读"脏"数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤消,这时T1已修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为"脏"数据,即不正确的数据。
选B,该操作丢失修改。
当两个或多个事物读入同一数据并修改,会发生丢失更新问题,即后一个事物更新的结果被前一事务所做更新覆盖。 即当事务T1和T2同时进行时,在执行到3操作时,事务T1将X的值改变成58(48+10),X的值已经改变,但并未提交,因此这时事务T2接收到X的值仍是48,在执行到4时,事务T2将X的值改变成46(48-2),造成步骤三的修改操作丢失,未起作用。
148 以下创建索引的语句正确的是( BC )
CREATE INDEX in1 ON w_user(u_name(10));
CREATE INDEX in2 ON w_user(u_pass(3));
CREATE INDEX in3 ON w_user(u_img(10));
CREATE INDEX in4 ON w_user(u_info);
创建索引的语句是create index indexname on tablename (username (length))
其中若是char和varchar类型,length可以小于字段实际长度,若是blob或text类型,必须指定length!
149 关于索引的说法,以下正确的是(ABCE)
数据库索引能避免进行数据库全表的扫描。
特定的情况下,索引可以避免排序操作。
存在非聚集索引时,有时无需访问数据页即可得到数据。
只要建立索引就能显著提高查询速度。
存在聚集索引时,有时无需访问数据页即可得到数据。
150 层次模型可以表示多对多的联系。请问这句话的说法是正确的吗?错误
层次模型可以表示一对多的联系
网状模型可以表示多对多的联系
151 下面哪个SQL命令用来向表中添加列(D)
MODIFY TABLE TableName ADD COLUMN ColumnName
MODIFY TABLE TableName ADD ColumnName
ALTER TABLE TableName ADD COLUMN ColumnName
ALTER TABLE TableName ADD ColumnName Type
增加列:alter table tableName add columnName varchar (30)
删除列:alter table tableName drop column columnName
152 在关系模式R中,Y函数依赖于X 的语义是:( B )。
在R的某一关系中,若两个元组的X值相等,则Y值也相等。
在R的每一关系中,若两个元组的X值相等,则Y值也相等。
在R的某一关系中,Y值应与X值相等。
在R的每一关系中,Y值应与X值相等。

153 已知关系 R 如图 1 所示,可以作为 R 主码的属性组是 ( B)。
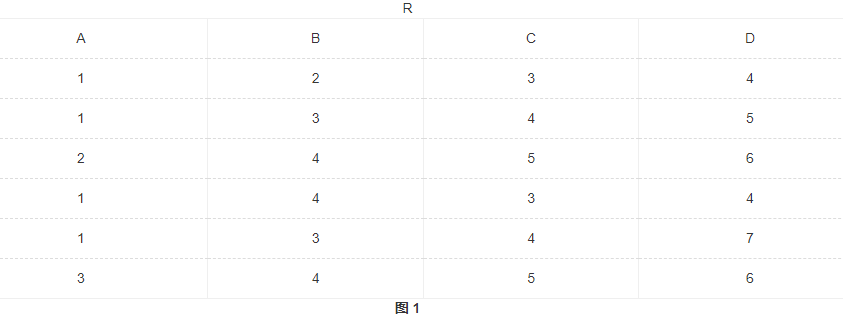
ABC
ABD
ACD
BCD
作为主键的属性组,要求不能出现相同值.
ACD中,第一行和第四行均出现134,被排除;
ABC中,第二行和第五行均出现134,被排除;
BCD中,第三行和第六行均出现456,被排除.
154 有订单表orders,包含字段用户信息userid,字段产品信息productid,以下语句能够返回至少被订购过两次的productid? D
select productid from orders where count(productid)>1
select productid from orders where max(productid)>1
select productid from orders where having count(productid)>1 group by productid
select productid from orders group by productid having count(productid)>1
顺序为:select, from, where, group by, having, order by, limit
where增加分组前的限定,having增加分组后的限定
group by 通常和集合函数SUM(),AVG().MAX(),MIN(),COUNT()等结合在一起,后接限制条件语句 having,不可用where语句!
155 查询优化策略中,正确的策略是( D)。
尽可能早地执行笛卡尔积操作
尽可能早地执行并操作
尽可能早地执行差操作
尽可能早地执行选择操作
1.选择运算尽可能早做,在优化策略中这是最重要,最基本的一条,它常常可以使执行节约几个数量级,因为选择运算一般使计算的中间结果大大变小
2.把投影运算和选择运算同时进行。如果有若干的投影和选择运算,并且他们都对同一个关系进行操纵的话,就可以在扫描此关系的同时完成所有的这些运算以避免重复扫描关系。
3.把投影同其前或其后的双目运算结合起来,没有必要为了去掉某些字段而扫描一遍关系
4.把某些选择同在他前面要执行的笛卡儿积结合成一个连接运算,连接特别是等值连接运算要比同样关系上的笛卡儿积省很多时间
5.找出公共子表达式
156 关系模型有三类完整性约束:实体完整性、参照完整性和用户定义的完整性,定义外键实现的是( B)完整性。
实体完整性
参照完整性
用户定义的完整性
实体完整性、参照完整性和用户定义的完整性
实体完整性 => 主键;参照完整性 => 外键;用户定义的完整性(域完整性)=> 对属性值进行约束
157 一个表的候选码一定是主码。 错误
码是数据系统中的基本概念。所谓码就是能唯一标识实体的属性,他是整个实体集的性质,而不是单个实体的性质。它包括超码,候选码,主码。 超码是一个或多个属性的集合,这些属性可以让我们在一个实体集中唯一地标识一个实体。如果K是一个超码,那么K的任意超集也是超码,也就是说如果K是超码,那么所有包含K的集合也是超码。 候选码是从超码中选出的,自然地候选码也是一个或多个属性的集合。因为超码的范围太广,很多是我们并不感兴趣即无用处的。所以候选码是最小超码,它们的任意真子集都不能成为超码。例如,如果K是超码,那么所有包含K的集合都不能是候选码;如果K,J都不是超码,那么K和J组成的集合(K,J)有可能是候选码。 是从多个候选码中任意选出一个做为主码,如果候选码只有一个,那么候选码就是主码。虽然说主码的选择是比较随意的,但在实际开发中还是要靠一定的经验,不然开发出来的系统会出现很多问题。一般来说主码都应该选择那此从不或者极少变化的的属性。
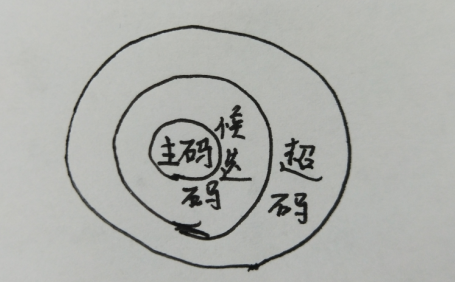
超码:一个或多个属性的集合,这些属性的组合可以使我们在一个实体集中唯一的标识一个实体。
例如:学生是一个实体,则学生的集合是一个实体集,而超码是用来在学生的集合中区分不同的学生。假设学生(实体)具有多个属性:学号,身份证号,姓名,性别。因为通过学号可以找到唯一一个学生,所以{学号}是一个超码,同理{学号,身份证号}、{学号,身份证号,姓名}、{学号,身份证号,姓名,性别}、{身份证号}、{身份证号,姓名}、{身份证号,姓名、性别}也是超码.在这里,因为不同的学生可能拥有相同的姓名,所以姓名不可以区别一个学生,既{姓名}不是一个超码,{性别}、{姓名、性别}也不是。
虽然超码可以唯一标识一个实体,但是可能大多数超码中含有多余的属性。所以我们需要候选码。
候选码:如果任意超码的真子集不能包括超码,则称其为候选码;超码包括候选码;
在上例中,只有{学号}、{身份证号}都是候选码;另外,如果性别和姓名可以唯一标识一个学生,则{姓名,性别}也为超码。
主码:被数据库设计者选中的,用来在同一实体集中区分不同实体的候选码;此外,应该选择哪些从不或极少变化的属性;
从候选码中选出主码,候选码有多个,主码唯一。
158 数据的逻辑独立性是指( C )
存储结构与物理结构的逻辑独立性
数据与存储结构的逻辑独立性
用户的应用程序与数据库的逻辑结构是相互独立的
数据元素之间的逻辑独立性
数据的逻辑独立性是指数据库逻辑结构的变化(如数据定义的修改、数据间联系的变更等)不影响用户的应用程序。
数据的物理独立性是指数据库的存储格式和组织方法改变时,不影响数据库的逻辑结构,从而不影响应用程序。

159 计算每位学生的多学科加总成绩的SQL是____C_
select sum(score) as total,stud_name from [成绩表](nolock)
select count(score) as total,stud_name from [成绩表](nolock)
select sum(score) as total,stud_name from [成绩表](nolock) group by stud_name
select count(score) as total,stud_name from [成绩表](nolock) group by stud_name
根据stud_name对学生进行分组,分组后,同一个学生的所有成绩分为一组,用sum(score)计算出总分,最有列名为total。但是题目应该加限定条件,学生不能重名,否则会出错。
count()函数里面的参数是列名的的时候,那么会计算有值项的次数。
Sum()函数里面的参数是列名的时候,是计算列名的值的相加,而不是有值项的总数。
160 数据库管理系统是(C)
.一个完整的数据库应用系统
.一组硬件
.一组软件
.既有硬件,也有软件
数据库管理系统,database management system,简称dbms,是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库。用户通过dbms访问数据库中的数据,数据库管理员也通过dbms进行数据库的维护工作。它可使多个应用程序和用户用不同的方法在同时或不同时刻去建立,修改和询问数据库。
数据库管理系统是位于用户和OS之间的一层管理 软 件 ,数据库系统是由数据库,硬件,软件,数据库管理员组成。
161 1NF 的二维表消除了传递函数依赖,则必定是(A )?
1NF
2NF
3NF
BCNF
162 查询如果涉及到两个表,那么这两个表之间应具有()表间关系。
一对一
一对多
多对多
一对一或一对多
2个表,所以只可能有一对一或一对多的关系,多对多得3张表
163 在SQL中,与HAVING搭配使用的是(C)。
ORDER BY
WHERE
GROUP BY
SELECT
where字句在聚合前先筛选记录,作用在group by和having字句前。
having子句在聚合后对组记录进行筛选
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
如:
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value;
164
积分result表中有A B C D四列,要求:
1)当A列值大于等于B列时,选择A列否则选择B列
2)当C列值大于等于D列时,选择C列否则选择D列
用SQL语句实现正确的是:( C )
select ( when A>=B then A else B ) MAX_AB, ( when C>=D then C else D ) MAX_CD from result
select (case when A>=B then A else B ) MAX_AB, (case when C>=D then C else D ) MAX_CD from result
select (case when A>=B then A else B end) MAX_AB, (case when C>=D then C else D end) MAX_CD from result
select case when A>=B then A else B end MAX_AB, case when C>=D then C else D end MAX_CD from result
165 在数据库系统中,产生不一致的根本原因是(D )
数据存储量太大
没有严格保护数据
未对数据进行完整性控制
.数据冗余

166关系规范化中的删除操作异常是指(A )
不该删除的数据被删除
不该插入的数据被插入
应该删除的数据未被删除
应该插入的数据未被插入
插入:应该插入的没有插入 删除:不该删除的删除了
167 概念模型是现实世界的第一层抽象,这一类模型中最著名的模型是 ( D)
层次模型
关系模型
网状模型
实体-联系模型
数据模型分为两类,一类是概念模型,一类是逻辑模型和物理模型。
概念模型的表示方式是实体——联系方式,也叫E-R模型
168 在数据库的非关系模型中,基本层次联系是( ) 。
两个记录型以及它们之间的多对多联系
两个记录型以及它们之间的一对多联系
两个记录型之间的多对多的联系
两个记录之间的一对多的联系
非关系模型即格式化模型,包括层次模型和网状模型其,基本层联系是指两个记录间的一对多联系
169
在MySql中,concat函数的作用是是将传入的参数连接成为一个字符串,则concat(’aaa’,null,’bbb’)的结果是(D )
aaabbb
aaa
bbb
NULL
CONCAT合并字符串,只要有一个字符串为空,则输出为空;CONCAT_WS合并字符串,只要第一个字符串不为空,则输出不为空。
170 两个事务在加锁过程中相互等待,哪一个事务都不能继续执行下去,这种状态称为_____D。
回滚
活锁
提交
死锁
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
虽然进程在运行过程中,可能发生死锁,但死锁的发生也必须具备一定的条件,死锁的发生必须具备以下四个必要条件。
1)互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
2)请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
3)不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
4)环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
任何条件被破坏,死锁随之消亡。
171 SQL 中,下列涉及空值的操作,不正确的是( )
AGE IS NOT NULL
AGE IS NULL
AGE = NULL
NOT (AGE IS NULL)
null是一种状态,不能用=来判断,只能用is或is not
172 3NF(C)规范化为BCNF。
消除非主属性对码的部分函数依赖
消除非主属性对码的传播函数依赖
消除主属性对码的部分和传递函数依赖
消除非平凡且非函数依赖的多值依赖
A为2NF;
B为3NF;
C为BCNF;
D为4NF。
4NF ⊆ BCNF ⊆ 3NF ⊆ 2NF ⊆ 1NF
(1NF:表里的属性不能再细分)
173 下列不属于数据库并发操作带来的问题是(C)?
丢失修改
不可重复读
死锁
脏读
数据库事务并发带来的问题有:更新丢失、脏读、不可重复读、幻象读。
1、更新丢失:一个事务的更新覆盖了另一个事务的更新。
2、脏读:一个事务读取了另一个事务未提交的数据。
3、不可重复读:一个事务两次读取同一个数据,两次读取的数据不一致。
4、幻象读:一个事务两次读取一个范围的记录,两次读取的记录数不一致。
死锁 ,进程死锁,是个计算机技术名词。它是操作系统或软件运行的一种状态:在多任务系统下,当一个或多个进程等待系统资源,而资源又被进程本身或其它进程占用时,就形成了 死锁 。
数据库中的死锁,两个或多个事务都已经封锁了一些数据对象,然后又都请求对已为其他事务封锁的数据对象加锁,从而出现死等待。
数据库中为了实现并发控制,采取了封锁技术,但是封锁技术又会带来活锁和死锁的问题,所以死锁不是数据库事务并发带来的问题,而是解决事务并发带来的问题。

174 五种基本关系代数运算是(A )
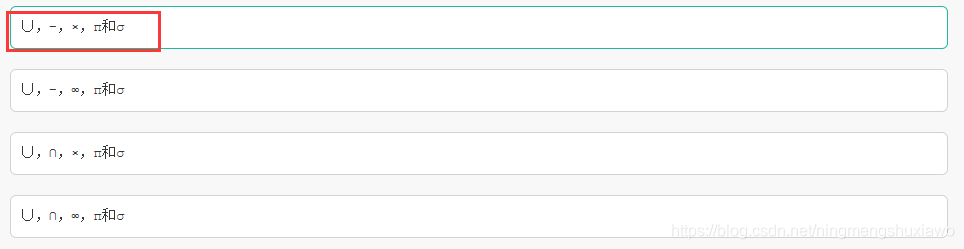
并、差、笛卡尔积、投影和选择,组成了关系代数完备的操作集。
∩可以由∪和-推导出
系代数运算中的基本运算包括并(∪)、差(-)、广义笛卡尔积(×)、投影(π)和选择(σ),其他运算的功能都可以由这五种基本运算来实现。
175 以下不同的数据库类型中,哪些不属于关系数据库范畴ACD
MongoDB
PostgreSQL
Redis
HBase
只有B属于关系型数据库;
A Mongodb数据属于文档型非关系数据库;
C Redis属于KV键值数据库
D Hbase属于列数据库
noSQL数据库其实有很多:
基于K-V:Redis, Voldemort, Oracle BDB
基于列存储:Cassandra, HBase, Riak.
基于文档型:CouchDB, MongoDB
176 自然连接是构成新关系的有效方法。一般情况下,当对关系 R 和 S 使用自然连接时,要求 R 和 S 含有一个或多个共有的(D )。
元组
行
记录
属性
自然联接是关系的横向结合,是将两个关系拼接成一个更宽的新关系,要求两个关系含有一个或多个共有的属性,生成的新关系中包含满足联接条件的元组。
两个关系通过共有的属性,即表的某一列,进行自然连接。
177 私网地址用于配置公司内部网络,下面选项中, (B) 属于私网地址。
128.168.10.1
10.128.10.1
127.10.0.1
172.15.0.1
为了弥补IPV4地址日益枯竭的矛盾,在A、B、C类地址中专门划出一小块地址作为全世界各地建设局域网使用,这些划出来专门作为局域网内网使用的IP地址称为私有网络地址(或称为私网地址,内网地址)。
私网地址不能在公网上出现,只能用在内部网路中,所有路由器都不能发送目标地址为私网地址的数据报。
标准规定的私网地址有:
A类私网地址:10.0.0.0~10.255.255.255
B类私网地址:172.16.0.0~172.31.255.255
C类私网地址:192.168.0.0~192.168.255.255
因此选B。
178 数据库物理设计完成后,进入数据库实施阶段,下列各项中不属于实施阶段的工作的是(B )。
建立库结构
扩充功能
加载数据
系统调试
简单来说:数据库实施阶段即尚未正式运行的阶段。
任务大概有四:
1.建立实际的数据库(将逻辑和物理设计的结果用sql语言等真正建立起来)
2.编写和调试应用程序
3.装数据(为了测试)
4.试运行
至于扩充功能,那是真正运行之后(运行和维护阶段)的工作,如果不满意还可能从头再来。
179 在数据库的安全性控制中,为了保护用户只能存取他有权存取的数据。在授权的定义中,数据对象的(A ),授权子系统就越灵活。
范围越小
范围越大
约束越细致
范围越适中
数据对象的范围越大,涉及的面的范围就越大,就要考虑该数据对象中的某些属性(ab)被这类用户有权访问,某些属性(bc)又被那类用户有权访问。所以数据对象的范围越小,就可以考虑整体将权限开放给某类用户,不用细致化去考虑授权。所谓“尾大不掉”~
180 已知 sys_user 表的建表语句如下: 现需获取 18 岁以下,且姓名重复的数据,以下 SQL 语句错误的有(ABD)
SELECT name,age
FROM sys_user
WHERE age<18
GROUP BY name;
SELECT name
FROM sys_user
WHERE age<18
GROUP BY name
HAVING COUNT(DISTINCT name)>1;
SELECT name
FROM sys_user
WHERE age<18
GROUP BY name
HAVING COUNT(name)>1;
SELECT name
FROM sys_user
WHERE age<18
GROUP BY name
HAVING COUNT(id)>1;
181 下列不属于数据安全性控制方法的是( )。
用户标识和鉴定
用户存取权限控制
数据加密
网络流量控制

网络流量控制是为了避免发送方把数据发送得过快,接收方可能会来不及接收,造成网络通信拥塞,不属于数据安全性控制方法。
182 DBMS 中实现事务隔离性的子系统是 ( C)
安全性管理子系统
完整性管理子系统
并发控制子系统
恢复管理子系统
 原子性由事务管理子系统来实现,一致性由完整性子系统实现,隔离性由并发控制子系统实现,持久性由恢复管理子系统实现。
原子性由事务管理子系统来实现,一致性由完整性子系统实现,隔离性由并发控制子系统实现,持久性由恢复管理子系统实现。
183 数据库的(B) 是指数据的正确性和相容性。
安全性
完整性
并发控制
恢复
数据库的安全性是指保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏。
数据库完整性(DatabaseIntegrity)是指数据库中数据在逻辑上的一致性、正确性、有效性和相容性。
184 对并发操作若不加以控制,可能会带来( D)问题。
不安全
死锁
死机
不一致
并发不加以控制会带来数据的不一致性问题,而对并发加以控制了,也就是加锁了,但是锁的控制没有弄好,才会带来死锁问题
是这样的,并发的话就是多个程序或者语句同时操作一个数据,这样就会产生不一致的问题,比如我对数据i进行两次加一操作,到时这两次操作都同时拿到i的值i被加两次但结果只被加了一次
185 某查询语句运行后返回的结果集为: C

SELECT class, AVG(score) FROM test WHERE class<3
SELECT class, AVG(score) FROM test WHERE class<3 GROUP BY class
SELECT class, AVG(score) FROM test WHERE class<3 GROUP BY ALL class
SELECT class, AVG(score) FROM test GROUP BY class HAVING class<3

186 对于满足SQL92标准的SQL语句: 其执行顺序应该是? A
select foo,count(foo)from pokes where foo>10group by foo having count (*)>5 order by foo
FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY
FROM->GROUP BY->WHERE->HAVING->SELECT->ORDER BY
FROM->WHERE->GROUP BY->HAVING->ORDER BY->SELECT
FROM->WHERE->ORDER BY->GROUP BY->HAVING->SELECT

187 下列关于视图与基本表的对比正确的是(A)。
视图的定义功能强于基本表
视图的操作功能强于基本表
视图的数据控制功能弱于基本表
上面提到的三种功能二者均相当
定义能力强于表,因为可以在多张表上定义视图,操作能力弱于表,控制能力相当
188 下列哪种完整性中,将每一条记录定义为表中的惟一实体,即不能重复 C
域完整性
引用完整性
实体完整性
其他
C.
实体完整性指表中行的完整性
域完整性指列的值域的完整性,如数据类型、格式、值域范围、是否允许空值等等
参照完整性基于外键与被引用主键之间的关系,确保键值在所有表中的一致性
实体完整性本质就是主码 选C
189 下列说法正确的是( )C
外模式、概念模式、内模式都只有一个
模式只有一个,概念模式和内模式有多个
外模式有多个,概念模式和内模式只有一个
三个模式中,只有概念模式才是真正存在的

190 若要“查询选修了3门以上课程的学生的学号”,则正确的SQL语句是(B )
SELECT S# FROM SC GROUP BY S# WHERE COUNT(*)> 3
SELECT S# FROM SC GROUP BY S# HAVING COUNT(*)> 3
SELECT S# FROM SC ORDER BY S# WHERE COUNT(*)> 3
SELECT S# FROM SC ORDER BY S# HAVING COUNT(*)> 3
1.order by 从英文里理解就是行的排序方式,默认的为升序。 order by 后面必须列出排序的字段名,可以是多个字段名。
2.group by 从英文里理解就是分组。必须有“聚合函数”来配合才能使用,使用时至少需要一个分组标志字段。
注意:聚合函数是—sum()、count()、avg()等都是“聚合函数”
count()属于聚合函数,where后面不能接聚合函数

191 在关系模型中,起导航数据作用的是(B )。
指针
关键码
DD
索引

192 在MySQL中,下列关于触发机器的描述正确的是(AC)
MySQL的触发器只支持行级出发,不支持语句级触发
触发器可以调用将数据返回客户端的存储程序
在MySQL中,使用new和old引用触发器中发生的记录内容
在触发器中可以使用显示或者隐式方式开始或结束事务的语句

193 消除了部分函数依赖的1NF的关系模式,必定是( B)。
1NF
2NF
3NF
BCNF
1NF : 属性是原子性的,即不可拆分的;例如姓名这个属性是一般不可拆分的;而社会保险号如果是由出生年月日与姓名缩写构成的话,就是可拆分的:包含可拆分的含义:出生年月日,姓名; 是否可拆分取决于对含义的解释;
2NF:解决了非主键属性对主键属性的部分依赖;如表(A, B, C, D),其中ABCD代表属性,假设(A, B)是主键,若C只依赖于B,则这个表是不符合2NF的,可拆分为(A, B, D)与 (B, C)两张表;很明显,如果主键只有一个属性,那么肯定是2NF
3NF:解决了非主键属性对主键属性的传递依赖;如表(A,B,C,D),如果主键是A, 而B依赖于A,C依赖于B,则这个表有传递依赖,是不符合3NF的;
范式的目的是为了减少/消除冗余;
194 快件信息表(waybillinfo)中存储了快件的所有操作信息,请找出在中山公园网点,异常派送(optype=‘异常派件’)次数超过3次的快件(waybillno),正确的sql为(D)
select waybillno, count(*) from waybillinfo where zonecode='中山公园' and optype='异常派件'
and count(waybillno) >3
select waybillno, count(*) from waybillinfo where zonecode='中山公园' and optype='异常派件'
order by waybillno having count(*) > 3
select waybillno, count(*) from waybillinfo where zonecode='中山公园' and optype='异常派件'
having count(*) > 3
select waybillno from waybillinfo where zonecode='中山公园' and optype='异常派件'
group by waybillno having count(*) > 3
1、where之后不能以函数作为条件
2、3、 having 是对 group by后的数据进行筛选过滤,必须要有group by才能用having。
having只能对group by的结果进行操作
having只用来在group by之后,having不可单独用,必须和group by用
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.将分组的结果进行having过滤
195 其中 S 表的主码为供应商号, P 表的主码为零件号,外码为供应商号,参照 S 表的供应商号,请问下面哪一条语句能插入到 P 表中? (B )
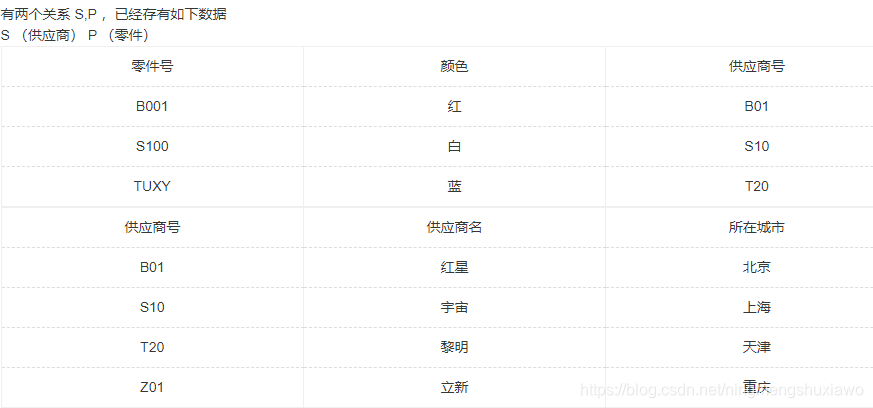
('S100',‘红’,‘T20’)
(‘TQOT’,‘绿’,NULL)
(‘A001’,‘黄’,‘T11’)
(NULL,‘红’,‘S20’)
选项A: P中的主键是零件号,所以零件号不能重复,故A错误。
选项C: S中没有 T11 这个主键,故不能成为P中的外键。
选项D: 主键不能为空。
外键可以为空,主键不可以
196 设有属性A,B,C,D,以下表示中不是关系的是__c___
R(A)
R(A,B,C,D)
R(A×B×C×D)
R(A,B)
笛卡儿积的结果是元组
197 关系数据模型的三个组成部分中,不包括(D)。
完整性规则
数据结构
数据操作
并发控制
关系数据模型的三个组成部分 完整性规则、 数据结构、 数据操作。
数据模型通常由数据结构、数据操作和数据的完整性约束条件三部分组成。
数据结构:描述数据库的组成对象以及对象之间的联系。
数据操作:指对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及有关的操作规则。
数据的完整性约束规则:一组完整性规则。
198 1968 年, IBM 公司推出的数据库管理系统 IMS 属于 B___
层次模型
树模型
关系模型
面向对象模型
IBS是层次模型数据库系统;
层次——树
网状——图
199 使用SQL语句建个存储过程proc_stu,然后以student表中的学号Stu_ID为输入参数@s_no,返回学生个人的指定信息。下面创建存储过程语句正确的是:( AB )
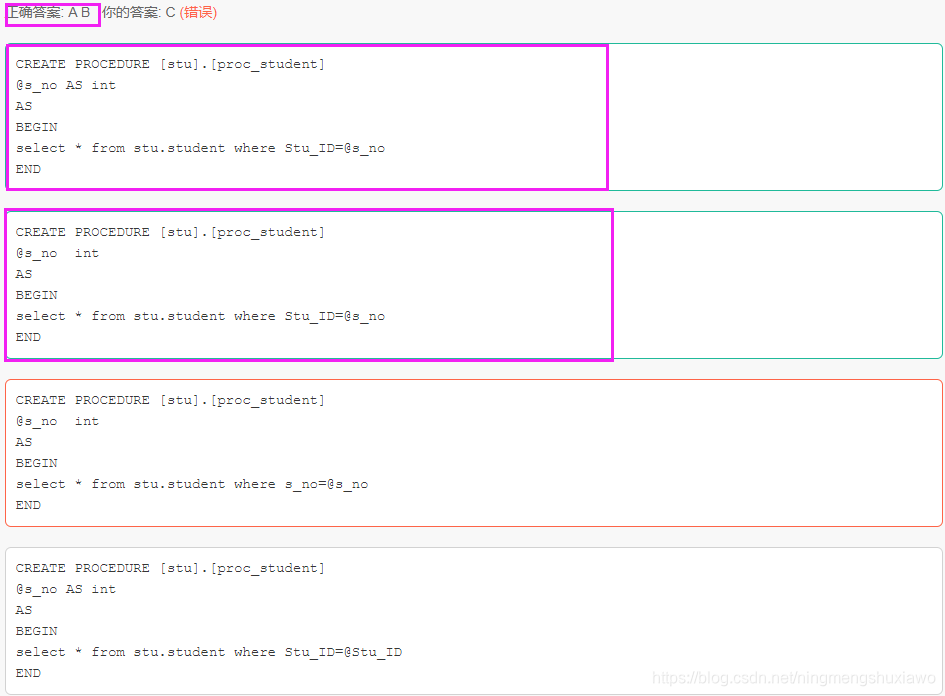
存储过程(stored procedure)是一组为了完成特定功能的SQL语句集合,经编译后存储在服务器端的数据库中,利用存储过程可以加速SQL语句的执行。
它可以提高SQL的速度,存储过程是编译过的,如果某一个操作包含大量的SQL代码或分别被执行多次,那么使用存储过程比直接使用单条SQL语句执行速度快的多。
200 用SQL查询 购买过goods_id 为1001的用户user_id(BCD)

select user_id from A where order_id = (select order_id from B where goods_id = '1001')
select a.user_id from A a,B b where a.order_id=b.order_id and b.goods_id='1001'
select user_id from A where order_id in (select order_id from B where goods_id = '1001')
Select A.user_id from A left join B on A.order_id=B.order_id where B.goods_id='1001'
在子表元素大于1时, 不能用= 要用in in(子表)
A错误在于多个返回查询值不能用=,要用in
对于D选项,在大多数的关系型数据库里面,如果在使用left join的同时,又把附表的条件放在where子句中,而不是 on子句中时,实际的执行效果相当于inner join .

















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









