






C++知识的应用
继承
基类对noncopyable的继承
多态
std::function和std::bind
总结
std::bind的思想实际上就是一种延迟计算的思想,将可调用对象保存起来,然后在需要的时候调用。
std::function一般要绑定一个可调用对象,类成员函数不能被绑定。而std::bind更加强大,成员函数、成员变量等都能绑定。现在通过std::function和std::bind配合使用,所有的可调用对象都有了统一的操作方法。
去除muduo对boost的依赖
boost库是muduo网络库依赖的第三方库。
在c++11标准出来之后,新增了std::function和std::bind,功能与boost::function和boost::bind相同。
因此就可以用标准库中的函数代替boost库中的函数,以此去除对boost库的依赖。
std::move()
std::move()函数可以以非常简单的方式将左值转换为右值引用。
通过std::move(),可以避免不必要的拷贝操作。
std::forward 完美转发
概念
在MemoryPool.h中的 T* newElement(Args&&... args) 函数中。
它的作用是实现函数参数的完美转发,通俗的讲就是根据传入的参数,决定将参数以左值引用还是右值引用的方式进行转发。
为什么需要完美转发
当传参为左值时,直接转发和完美转发的结果都是左值,是正确的。但是当传参是右值时,直接转发和完美转发的结果却不同了。
分析其原因,当一个右值作为传参被传入后,函数内便会分配栈空间来保存传参。此时的右值已经被传参中的变量名所指向,所以再次传入此右值时,实际传入的是指向它的变量名,即一个左值。所以会出现上图中传参为右值但是直接转发却为左值的情况。
智能指针
std::shared_ptr
TcpConnection的生存周期管理,为什么用shared_ptr管理
Thread
Thread中变量std::shared_ptr<std::thread> thread_;
为什么会有多个指针指向thread_?
thread_的类型就是标准库的thread,每个线程必然会有多个指针
std::unique_ptr
TcpServer
TcpServer中的接收器
std::unique_ptr<Acceptor> acceptor_;
TcpConnection
TcpConnection类中的套接字和Channel对象
std::unique_ptr<Socket> socket_;
std::unique_ptr<Channel> channel_;
EventLoopThreadPool
EventLoop线程池类中EventLoop线程数组
std::vector<std::unique_ptr<EventLoopThread>> threads_;
AsyncLogging
异步日志类中的Buffer数组
using BufferVector = std::vector<std::unique_ptr<Buffer>>;
BufferVector buffers_;
EventLoop
poller_处理I/O复用
timerQueue_是定时器队列
wakeupChannel_是封装了wakeupFd的Channel,用来处理wakeupFd对应的事件
std::unique_ptr<Poller> poller_;
std::unique_ptr<TimerQueue> timerQueue_;
std::unique_ptr<Channel> wakeupChannel_;
并发
std::lock_guard
std::unique_lock
构造
为什么使用noncopyable类禁止拷贝构造
浅拷贝问题
编译器默认生成的构造函数,是memberwise拷贝(也就是逐个拷贝成员变量)
class Widget {
public:
Widget(const std::string &name) : name_(name), buf_(new char[10]) {}
~Widget() { delete buf_; }
private:
std::string name_;
char *buf_;
};
对于上面的这个类,如果默认生成的拷贝构造函数,会直接拷贝buf_的值,导致两个Widget对象指向同一个缓冲区,这会导致析构的时候两次删除同一片区域的问题(这个问题又叫双杀问题)。
基类拷贝构造问题
自定义了基类和派生类的拷贝构造函数,但派生类对象拷贝时,调用了派生类的拷贝,而派生类的拷贝没有调用自定义的基类拷贝而是调用默认的基类拷贝。这样可能造成不安全,比如出现二次析构问题时,因为不会调用我们自定义的基类深拷贝,还是默认的浅拷贝。
设计模式
单例模式
ConnectionPool 数据库连接池
内存池
作用
- 避免内存碎片。
- 避免系统调用开销。
操作系统分用户态和内核态,我们只能在用户态进行操作。我们所使用的内存有栈和堆的,栈的内存自动分配和回收。对于程序员来说,主动申请和释放的内存是堆的内存。比如 malloc()、free()。
我们调用 malloc() 向堆申请内存,系统也分配给了我们。但是我们申请的这部分内存容易造成内部碎片,这会导致残缺的内存块不能被我们所利用。比如申请 4k 的内存块,系统剩余的内存空间也够。但是这些是不连续的,连续的块可能只有 2k 大小,那么就会发生内存分配失败的情况。
如果是公司级别的程序,不像个人写的 demo。那么随着服务器长久时间的运行,可能会出现不断蚕食剩余内存的情况,这种内存问题很难排查。
除此之外,malloc 是会涉及用户态和内核态转换的。经常这样转换会影响服务器性能,我们应尽量避免直接向系统申请内存。
因此我们需要内存池来解决上述问题,本质就是程序员自己设置一套管理内存的手段。我们向系统申请大块的内存并交由内存池来管理,编程中对应内存的申请和释放就交给内存池来处理了。这样出问题了,我们也可以从内存池那里先排查,更容易发现内存相关的问题。
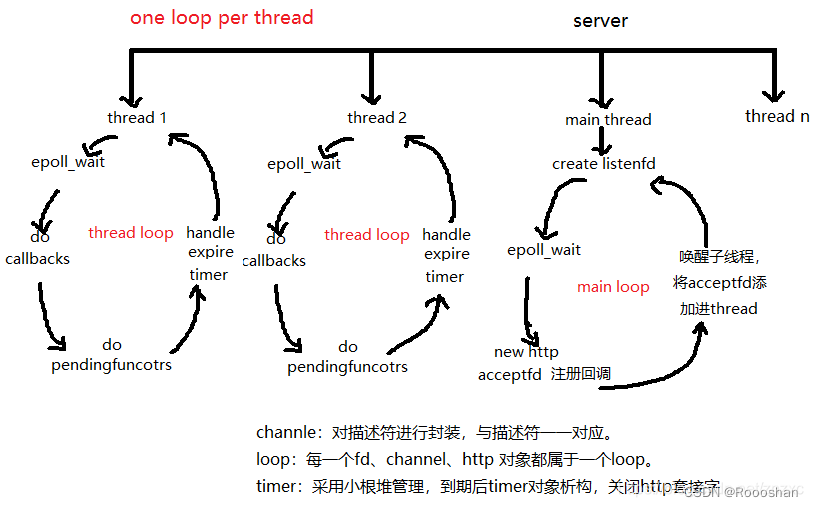
EventLoop
one thread per loop
主线程属于main loop,创建listenfd,创建listenfd的可读回调函数,该回调函数执行accept返回交流套接字,同时new一个http对象(与交流套接字绑定),添加进thread loop,从此这个交流套接字由thread loop负责,进行响应。
main loop只负责响应新的客户端连接,客户端与服务端的交流在thread loop中完成。















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









