








目录
1.Learning with errors (LWE)(简单了解下,同态性质更关键!!!)
2.Somewhat Homomorphic Encryption (SHE)
3.Vectorized Homomorphic Encryption
··············· ·码字辛苦--点赞支持--引用注名···················
一. 概要
本文的摘要是介绍了一种名为Vectorized BatchPIR的批量私人信息检索(BatchPIR)方案,该方案通过使用单个密文检索多个数据库条目实现了低通信和低计算的目标。作者观察到可以通过使用向量化RLWE同态加密的变体来节省通信,并设计了一种方法来合并加密独立条目的密文。在下载一个包含256个条目的批次时,该方案的摊销通信开销是不安全基线的19.2倍,比最先进的PIR方案好7.5倍,比现有的BatchPIR方案好两个数量级。贡献点在于提出了一种新的BatchPIR方案,实现了低通信和低计算的目标。
本文的主要贡献是介绍了一种名为Vectorized BatchPIR的批量私人信息检索(BatchPIR)方案,该方案通过使用单个密文检索多个数据库条目实现了低通信和低计算的目标。作者设计了一种向量化RLWE同态加密的变体,并提出了一种合并加密独立条目的方法。该方案的通信开销比不安全基线好7.5倍,比最先进的PIR方案好两个数量级。

二.背景知识
1.Learning with errors (LWE)(简单了解下,同态性质更关键!!!)
是一种基于格的加密技术,它是一种在计算上难以解决的问题。LWE问题的基本形式是:给定一个由n个向量组成的矩阵A和一个向量b,以及一个小的误差向量e,找到一个向量s,使得As+e=b。LWE问题的难度在于,对于给定的A和b,找到s是困难的,因为误差向量e是随机的。LWE问题是一种基础的加密原语,可以用于构建各种加密方案,包括私有信息检索(PIR)方案。在本文中,SimplePIR方案的安全性基于LWE假设,即LWE问题的解决难度足以保证SimplePIR方案的安全性。在文字提及到(𝑛, 𝑞, 𝜒)-LWE,解释一下:𝑛代表向量的维度,𝑞代表整数模数,𝜒代表误差分布。因此,(𝑛, 𝑞, 𝜒)-LWE问题描述了在给定向量维度𝑛、整数模数𝑞和误差分布𝜒的情况下,解决Learning with errors (LWE)问题的难度。这种参数化的LWE问题在密码学中具有重要意义,因为不同的参数取值可以导致不同难度的LWE问题,从而影响基于LWE问题构建的加密方案的安全性。因此,对于给定的𝑛、𝑞和𝜒,(𝑛, 𝑞, 𝜒)-LWE问题的难度可以用来评估基于LWE假设的加密方案的安全性
Secret-key Regev encryption:是一种基于LWE假设的加密方案,由Regev在2005年提出。该方案的安全性基于LWE问题的困难性,即在给定矩阵A和向量b的情况下,找到向量s是困难的,其中b是由A和s的点积加上一个小的误差向量e得到的。Secret-key Regev encryption方案的基本思想是将明文编码为一个向量,并将其与一个随机向量的点积加上一个小的误差向量,然后将其加密。具体来说:
LWE问题如下,已知A和r无法解密获得s。
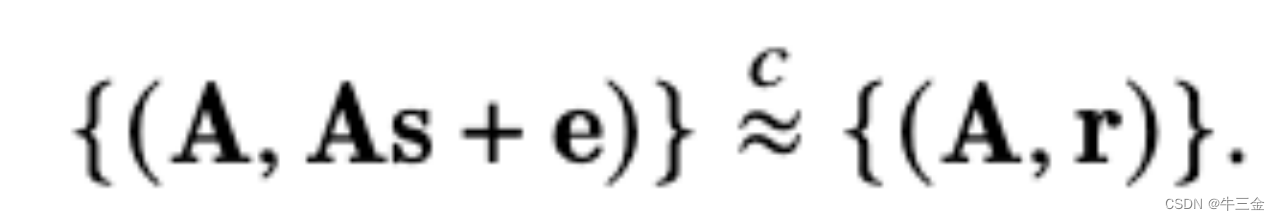
2.Somewhat Homomorphic Encryption (SHE)
我们仅需要知晓其具备的计算特性:
• CtCtAdd(c1,c2):(密文加法同态) This operation takes as input two ci-
phertexts c1 ∈R2q and c2 ∈R2q , and outputs a ciphertext
encrypting the sum of two plaintexts.
• CtPtMul(c,p): (常数乘密文)This operation takes as input a plaintext
p ∈Rt and a ciphertext c ∈R2q encrypting m ∈Rt, and
outputs a ciphertext encrypting p ·m.
• CtCtMul(c1,c2): (密文乘法同态)This operation takes as input two ci-
phertexts c1 ∈ R2q and c2 ∈ R2q and outputs a ciphertext
encrypting the product of two plaintexts.
3.Vectorized Homomorphic Encryption
我们仅需要知晓其具备的计算特性,即可根据提供的参数实现密文的整体移动:
• CtRotate(c,r): (密文流转)This operation takes as input a ciphertext
c encrypting a plaintext vector v = [v1,v2,··· ,vn] and
a value r ∈ [0,n). It outputs a ciphertext encrypting
v′ = [vn−r+1,vn−r+2,··· ,vn,v1,v2,··· ,vn−r], i.e., v
rotated by r slots.对于一组明文 v = [v1,v2,··· ,vn],加密后获得一个多项式,采用该方法可以在不解密的前提下实现密文的变动,使得解密后明文为向后移动常数r的明文空间。
性能说明:

从上图中我们可以看出,对于密态乘十分消耗时间,其次密文流转也比较消耗时间,而对于密文加、常数乘都消耗极少(常数乘就是多个密文相加)。
4.传统的批量匿踪查询(batchPIR)
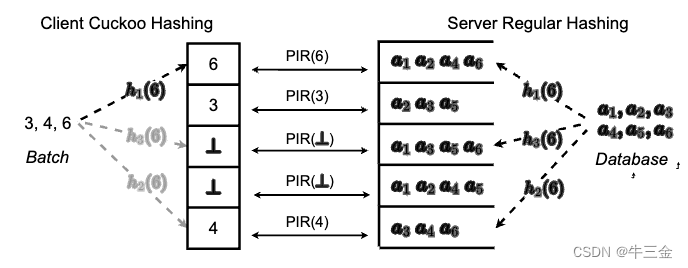
client 使用Cuckoo Hashing将所有想要查询的数据插入其中,server方使用Simple Hash将所有数据插入其中,client每个槽仅有一个数据,server方每个槽有多个数据,然后在各个槽中使用单条匿踪查询。具体方案可查看原文[1]。值得注意的是,这个方案的效率:仅b次同态乘(b为hash表长度通常为查询请求的1.5倍)以及可以忽略的同态加,但其传输开销巨大,需要b条密文。
三、方案说明
1.单条匿踪查询:
A 数据库多维度拆解:
在很早XPIR中就有提到,如何加速查询效率,如果数据库有100条数据,我们进行一次查询需要生成一个唯“1”的零向量[0,0,...1,0,0,0]仅要查询的位置为1,其余数据均为0。这样我们需要大量的100次密态乘和100次密态加,假如现在我们将数据库拆解成2维,即一个10*10的矩阵,挨个将100条数据放入矩阵,查询方发送两个查询向量,一个来确定行位置,一个确定列位置,那么我们仅需要10次密态乘和10次密态加,这里将计算复杂度从O(n)降低至O(√N)。如果我们将维度再次升高值三维,查询方发送三个查询向量,计算复杂度可以从O(n)降低至O(3√N),但也不是维度越高越好,本文中的最佳维度为3。如下图,数据方拥有27条数据,将数据拆解成row(行)、column(列)、slice(片)。查询方想要查询8,其位置为第2行、第1列、第1片。

图一
步骤说明:
· 使用第一密文请求乘以每一片的每一列,并且使用同态流转,将结果向后流转一位。然后将每一片的结果相加获得新的片数据据。
· 使用第二密文请求乘以新的片数据,并同样使用密文流转,最后相加获得列数据。
· 最后使用第三密文请求乘列数据获得最终请求结果。
B 密文流转优化:
在②中需要密文流转9次、④中3次,一共12次,为减小次数,将请求密文进行流转,然后明文同样进行流转,减小密文的流转:
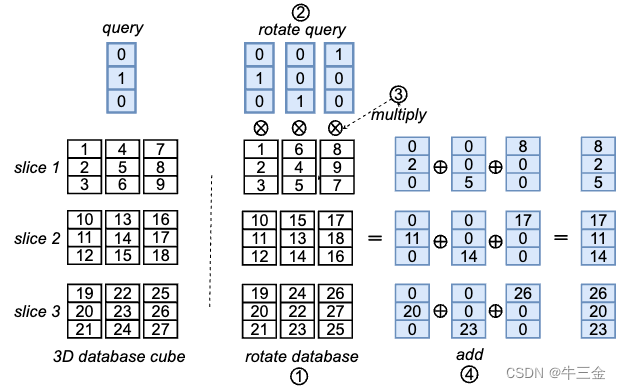
图二
C 向量查询完整流程:


在Algorithm3 第3行为上文图二的②说的密文流转,步骤6为上图二的③④。步骤8-18为上文的图一的③、④、⑤、⑥。而对于Algorithm1和2可以理解为一种packing,将查询的数据和查询的请求都放入一个明文空间,这些数据和请求的间隔为g。比如[1,2,3],请求为2即[0,1, 0],会或恶数据集[1,0,0,...,0,2,0,0...,0,3,0,...,0],请求打包成[0,0,...,1,0...0],每条数据间隔g个。这种做法可以充分利用密文空间,在批量匿踪查询方案中会体现出来。
2.批量匿踪查询:
A 响应合并:
回到传统的批量匿踪查询算法,我们可以看到获得多个密文数据,如果简单的将其合并将会碰撞,如下图:
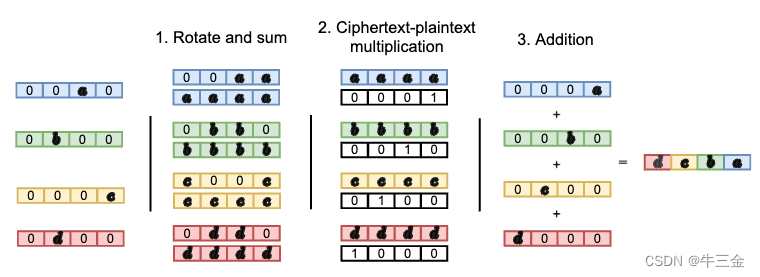
这里的a和d相加会出现碰撞,我们需要将其进行流转从而实现合并。做法,将数据向后密文流转一次然后和原本的密文相加,然后再流转再相见。为了加速,我们将第一次获得的相加结果,进行向后流转两个位置,然后相加,若数据更多的话所有流转都基于上一次进行,计算速度提升至logn。然后将所有的密文乘以明文唯“0”向量。最后密文相加。
B 完整的批量匿踪查询协议:



首先是需要注意的是n是明文槽数,N‘B为最大bucket开三次方,g为明文间隔。
首先将所有数据预处理生成多个DB,在上一个单匿踪查询方案中,我们说它打包的方式为间隔g个将DB’填满,这里一样间隔g个将数据填满,不过接下来需要做的是将数据流转一个位置,继续填充,会将整个DB‘填充完整,一共形成B/g-1个全数据DB’。然后同样将所有的维1向量进行填充获得请求密文数据。接下来使用算法3中的请求密文计算,会获得每间隔g个就有一个数据,最后将获得的结果使用算法6获得合并结果。
举例:
DB为[1,2,3,4,5,6,7,8],假如使用hash结果为[1,2,3][2,3,4][4,5,6],查询方查询为1,4,经过cuckoo hash为[1][4][null]。
数据处理:获得DB'=[1,2,3,2,3,5,3,4,6],Q‘=[1,0,0,0,0,1,0,0,0],然后DB‘·Q’=[1,0,0,0,0,4,0,0,0]。
然后算法6的做法为:经过45步获得[1,1,1,4,4,4,0,0,0],经过10、11步获得[1,4,0]。
参考文献:
[1] S. Angel, H. Chen, K. Laine, and S. T. V. Setty, “PIR with compressed
queries and amortized query processing,” in 2018 IEEE Symposium on
Security and Privacy. San Francisco, California, USA: IEEE Computer
Society, 2018, pp. 962–979.
[2]M. H. Mughees and L. Ren, "Vectorized Batch Private Information Retrieval," 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 2023, pp. 437-452, doi: 10.1109/SP46215.2023.10179329.
keywords: {Privacy;Protocols;Costs;Databases;Information retrieval;Computational efficiency;Servers;Homomorphic-Encryption;Private-information-retrieval;Private-data},
















 7485
7485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









