






为什么需要大模型来进行翻译
大语言模型在翻译一句话时添加了上下文(context)作为背景:特别是在读文献时,逐句翻译或者机翻,往往存在翻译不准确的问题。我至今还记得第一次看英文文献时,larva(幼蟹),被翻译成了幼龙,一开始百思不得其解。也许是《龙与地下城》的信息占的比较多吧。
在查看专业的英文文献、英文书籍,有双语对照往往是最好的,一方面不用反复复制翻译。而且,在全文基础上进行翻译,结果更加精准。
今天介绍的这款PDFmathTranslate是Github上目前最热门的翻译软件,已经有16.1k颗星了。
这次主要介绍交互式界面和命令行界面的使用方法。
简介
PDFMathTranslate是一款强大的开源PDF文档翻译工具,具有以下特点:
-
保留原始PDF排版样式:翻译后的文档会完整保持原文的格式、图片、公式等元素
-
支持双语对照:可以同时显示原文和译文,方便对比学习
-
数学公式处理:能够准确识别和保留数学公式,不会破坏公式的结构
-
开源免费:软件完全开源,用户可以免费使用和修改
这个工具特别适合需要阅读外文学术论文的学生和研究人员,可以帮助他们快速理解文献内容,同时保持专业术语和数学公式的准确性。

交互式界面流程
- 在github(PDFMathTranslate/docs/README_zh-CN.md at main · Byaidu/PDFMathTranslate)上找到安装方式,选择方法二,便携式安装,下载setup.bat
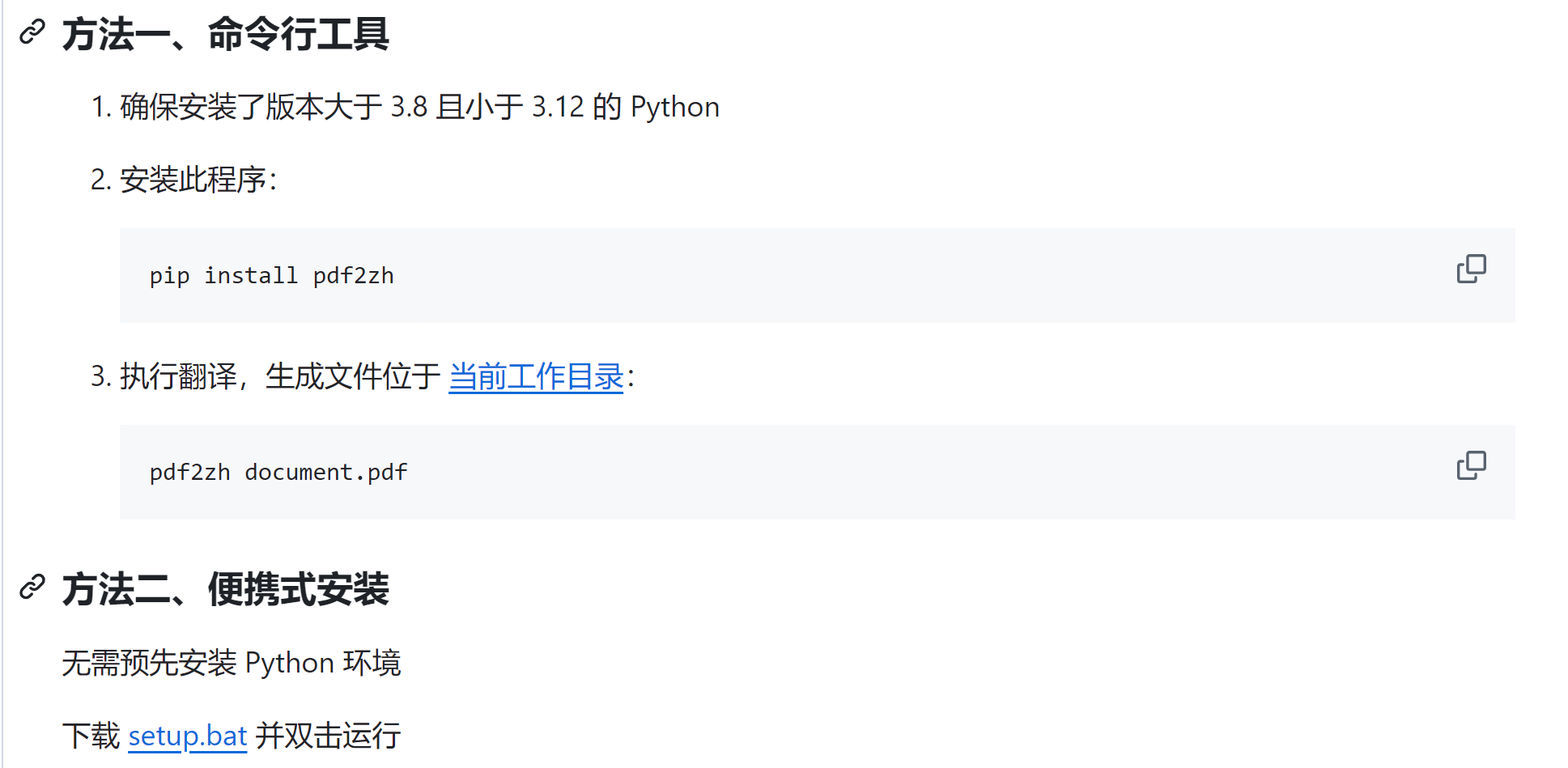
2. 点击这里的链接,会出现一个文本,复制下来。然后创建一个txt文件,将内容复制进去,再把.txt后缀改成.bat
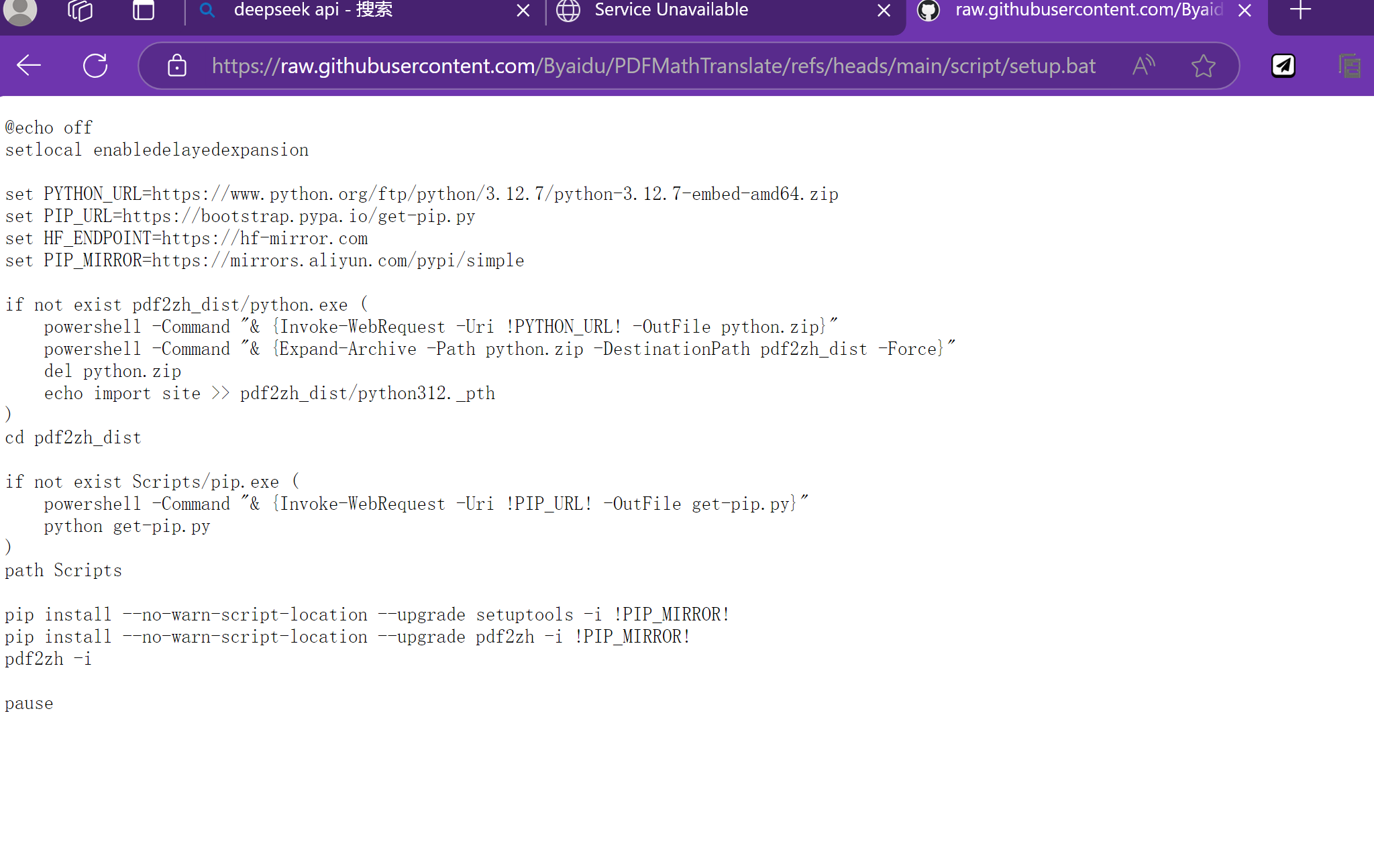
3. 双击bat文件

4. 打开软件后,点击"选择PDF文件"按钮导入需要翻译的PDF文档
- 选择翻译模型和API:推荐使用deepseek的api,性价比是最高的,而且对中文长文的支持度更高。但是这几天deepseek的api好像打开不了,可以等一等。
翻译完成后,软件会生成以下内容:
-
双语对照PDF:原文和译文并排显示
-
纯译文PDF:仅显示翻译后的内容
特别说明:
-
软件会自动识别和保留数学公式,无需担心公式被错误翻译
-
可以随时暂停和继续翻译过程
命令行流程
命令行的好处就是自定义程度高,可以自己编写脚本来简化很多流程。如果想一次性翻译十个英文文献,一个个手动就很麻烦,我写了一个python脚本可以用来快速处理,只需要输入文件夹路径,就可以自动翻译其中所有的pdf文件。
下面是使用命令行运行PDFMathTranslate的详细步骤:
-
首先,确保已安装Python 3.8或更高版本
-
安装PDFMathTranslate包:
pip install pdfmathtranslate
- 运行pdf2zh
全文翻译
pdf2zh example.pdf
部分翻译
pdf2zh example.pdf -p 1-3,5
- 使用python脚本一次性翻译一个文件夹下的所有pdf,创建一个tanslate_all.py文件,把下面的代码复制进去
import os
import subprocess
from pathlib import Path
import json
def get_folder_path():
while True:
folder_path = input("请输入要翻译的文件夹路径:").strip()
if os.path.isdir(folder_path):
return Path(folder_path)
else:
print("路径无效,请重新输入。")
def create_output_directory(folder: Path) -> Path:
output_dir = folder / "translated"
output_dir.mkdir(exist_ok=True)
return output_dir
def find_pdf_files(folder: Path):
return list(folder.glob("*.pdf"))
def translate_pdf(pdf_path: Path, output_dir: Path, pdf2zh_exe: Path, folder: Path, api_key: str):
output_path = output_dir / pdf_path.name.replace(".pdf", "-translated.pdf")
try:
# 复制当前环境变量并添加 ZHIPU_API_KEY
env = os.environ.copy()
env["ZHIPU_API_KEY"] = '<这里放你的智谱api>'
subprocess.run([
str(pdf2zh_exe),
str(pdf_path),
"-li", "en", # 源语言
"-lo", "zh", # 目标语言
"-s", "zhipu", # 翻译服务可选择其他的
"-t", "10", # 线程数量
"-o", str(output_dir), # 输出目录
], check=True, env=env)
print(f"已成功翻译:{pdf_path.name}")
except subprocess.CalledProcessError as e:
print(f"翻译失败:{pdf_path.name}\n错误信息:{e}")
def main():
# 设置 ZHIPU_API_KEY
os.environ["ZHIPU_API_KEY"] = "<这里存放你的智谱api>" # 在此处设置您的 API 密钥
# 设置 pdf2zh.exe 的绝对路径
pdf2zh_exe = Path(r"C:\Users\15860\AppData\Local\Packages\PythonSoftwareFoundation.python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\Scripts\pdf2zh.exe")
if not pdf2zh_exe.exists():
print(f"无法找到 pdf2zh.exe,请确认路径是否正确:{pdf2zh_exe}")
return
folder = get_folder_path()
output_dir = create_output_directory(folder)
pdf_files = find_pdf_files(folder)
if not pdf_files:
print("在指定的文件夹中未找到 PDF 文件。")
return
print(f"找到 {len(pdf_files)} 个 PDF 文件,开始翻译...")
api_key = os.getenv("ZHIPU_API_KEY") # 从环境变量获取 API 密钥
if not api_key:
print("未找到 ZHIPU_API_KEY,请设置环境变量后重试。")
return
for pdf in pdf_files:
translate_pdf(pdf, output_dir, pdf2zh_exe, folder, api_key) # 传递 API 密钥
print("所有翻译任务已完成。")
if __name__ == "__main__":
main()
- 运行
python translate_all.py
命令行版本的一些注意事项:
-
确保在运行脚本前已正确设置API密钥
-
可以通过修改代码来自定义翻译参数,如语言对、翻译服务等
-
建议先用小文件测试脚本是否正常工作


















 2518
2518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









