










Yuan2.0千亿大模型在通用服务器上的高效推理实现
一.引言
浪潮信息与Intel携手,在IPF大会上震撼发布AI通用服务器,单机即可驾驭千亿参数大模型,引领行业新潮流。现场演示中,NF8260G7服务器搭载yuan2.0-102B模型,在代码编写、逻辑推理等复杂任务中实时推理,效果卓越,备受瞩目。本文将深入剖析其高效实时推理机制,展现其前沿技术路径,带您领略科技的力量。

二.大模型推理部署难点
大模型推理常依赖GPU异构加速,但随其应用普及,构建高效、稳定、低成本基础设施成业界热点。AI通用服务器凭借低落地成本、高兼容度及稳定性,在大模型推理中展现出显著优势,成为业界新宠,为大规模应用提供强大支撑。
大模型推理挑战重重,其参数量庞大,需GPU显存存放全部权重及KV Cache,常占模型参数量2-3倍内存,部署千亿模型(100B)需高达200-300GB GPU显存,远超主流AI加速芯片。业界LLM架构由GPT向MOE演进,开源模型尺寸激增,千亿级参数模型渐成主流。如何应对这一挑战,实现高效部署,已成为行业亟待解决的问题。
大模型推理需高算力与带宽。预填充阶段一次性输入prompt,计算压力大;解码阶段每次生成1个token,访存比低,内存带宽压力大。实时推理要求计算设备既具高计算能力,又需高效数据搬运效率,确保存储单元与计算单元间数据传输迅速,满足千亿大模型的高效运行需求。
三.Yuan2.0模型特点
Yuan2.0(源2.0)是浪潮信息在2023年11月发布的新一代基础语言大模型。它包括Yuan2.0-102B、Yuan2.0-51B和Yuan2.0-2B三个模型。在模型架构上,Yuan2.0提出了一种基于本地化过滤的注意力机制(Localized Filtering-based Attention),用于捕捉输入序列的局部依赖关系。相对于传统的全局Attention机制,LFA在前向传播之前引入了两层一维卷积层,以考虑更多的输入信息,从而具有更强的时序性和局部性。另外Yuan2.0通过更多高质量的预训练数据和微调数据集来提升模型的理解能力。
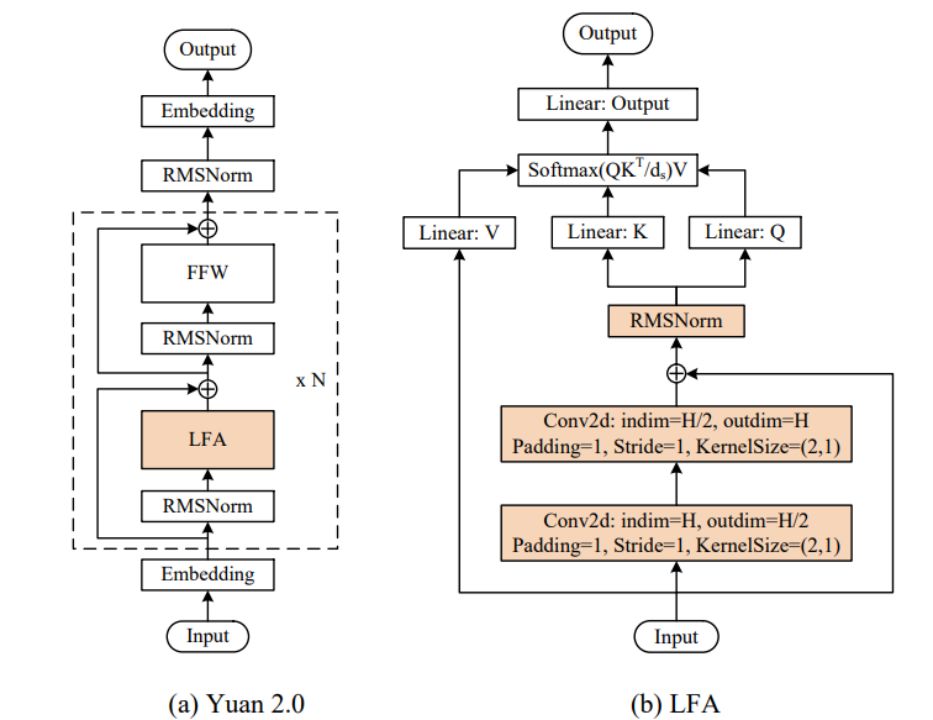 为了尽可能的加速yuan2.0-102B的推理计算效率,我们采用了张量并行(tensor parallel)策略来同时使用NF8260G7服务器中的4颗CPU。张量并行通过把yuan2.0-102B模型中的注意力层和前馈层的矩阵计算分别拆分到多个处理器,来同时使用4颗处理器来进行计算加速。但是,需要提到的是,张量并行策略因为对模型参数的切分粒度较细,会需要处理器在每次张量计算后进行数据同步。这些额外的数据同步,对处理器间的通信带宽,提出了较高的要求。
为了尽可能的加速yuan2.0-102B的推理计算效率,我们采用了张量并行(tensor parallel)策略来同时使用NF8260G7服务器中的4颗CPU。张量并行通过把yuan2.0-102B模型中的注意力层和前馈层的矩阵计算分别拆分到多个处理器,来同时使用4颗处理器来进行计算加速。但是,需要提到的是,张量并行策略因为对模型参数的切分粒度较细,会需要处理器在每次张量计算后进行数据同步。这些额外的数据同步,对处理器间的通信带宽,提出了较高的要求。
传统在使用多个基于PCIe互联的AI芯片进行张量并行时,通信占比往往会高达50%,也就是AI芯片有50%的时间都在等待数据传输,处于空闲状态,极大的影响了推理效率。相比之下,NF8260G7服务器中的4颗CPU采用了全链路UPI总线互连,通过全链路UPI互连有两个优势:1、全链路互连可以使得任意两个CPU的通信可以直接进行数据传输,2、UPI互连的传输速率高,传输速率高达16GT/s。远高于PCIe的通信带宽,从而保障了4颗处理器间高效的数据传输。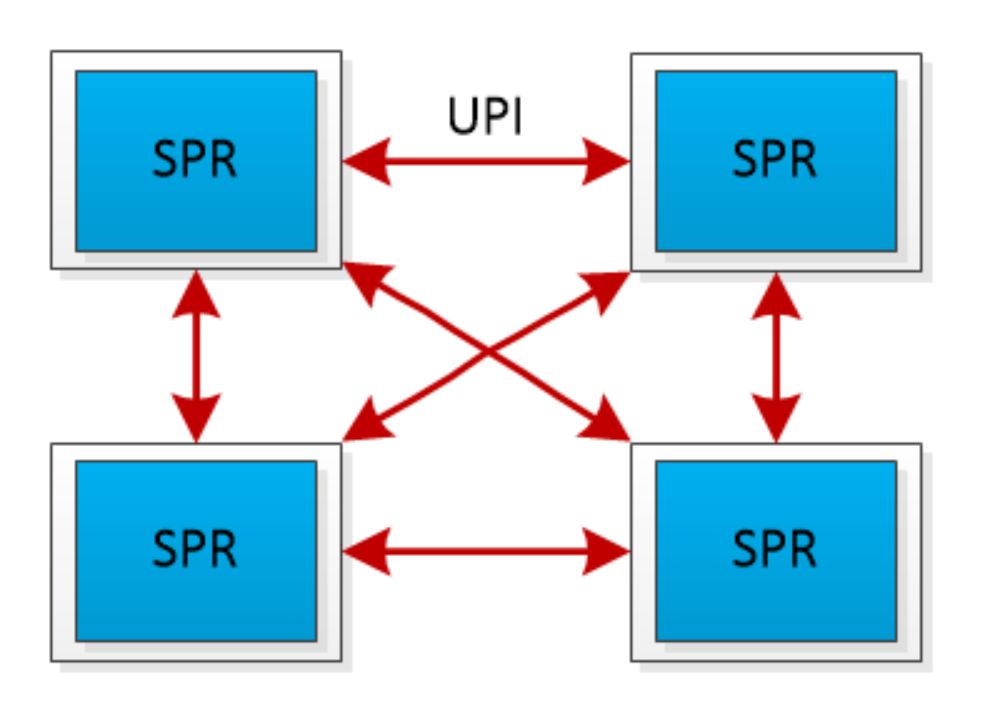
四.基于张量并行和NF4量化的模型部署策略
在此基础上,为了进一步加速yuan2.0-102B的推理效率,我们使用了NF4量化技术,来进一步提升推理的解码效率,从而达到实时推理的解码需求。NF4(4位NormalFloat)数据类型属于分位数量化,是一种信息论上对于正态分布数据来说最优的量化数据类型,确保每个量化区间中有相等数量的值来自输入张量。分位数量化通过估计输入张量的分位数来实现,由于LLM模型权重为具有零中心的正态分布,因此可以通过缩放标准差来适应我们的数据类型的范围,其实际量化得到的精度结果比4位整数和4位浮点数(整形和浮点型数据的量化数据间隔呈现平均分布和指数分布,对于描述呈现正态分布的模型权重来说分位数量化描述更精确)更好。
INT4数据类型(平均分布)和NF4数据类型(正态分布)对比图如下图所示: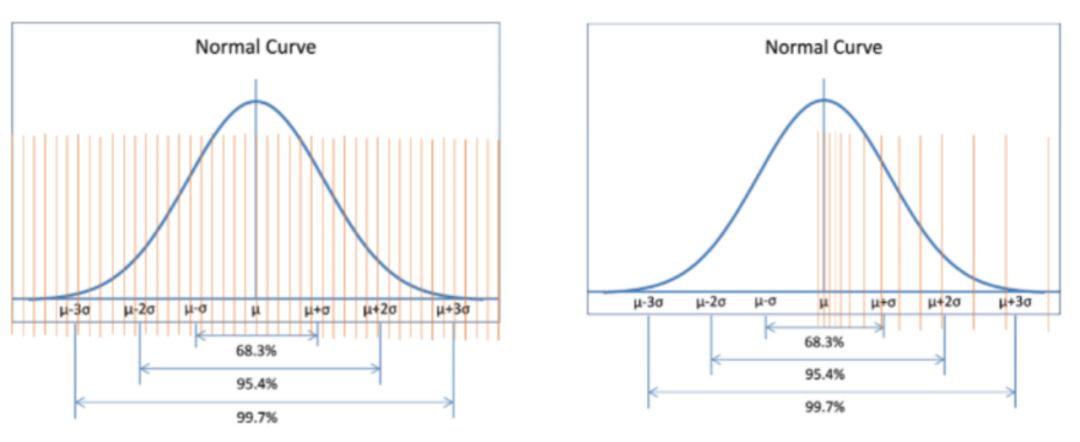 INT4数据类型与NF4数据类型对比
INT4数据类型与NF4数据类型对比
yuan2.0-102B在NF4基础上,运用嵌套量化技术,即Double Quant,来高效压缩模型权重。该技术对NF4量化后的参数进行二次量化,解决了NF4量化产生的大量scale参数导致的内存占用问题。对于千亿级模型,若以64参数为一block量化,其scale参数存储仅需额外极小的空间,显著提升了模型存储效率。
(100B/64)*4=6GB
计算结果为:存储需求总计1.57GB,包含(100B/64/256)*4与(100B/64)*1部分。
采用二次量化技术,block size设为256后,模型权重参数每个仅占4byte内存,CPU数据传输效率飙升4倍。这一创新显著降低了内存带宽对yuan2.0-102B推理解码效率的制约,实现了高效解码体验。
采用张量并行与NF4量化技术,我们在NF8260G7服务器上成功实现千亿大模型的实时推理。通过详细的profiling分析,我们准确评估了服务器在LLM推理中的算子和通信效率,展现了卓越的实时处理能力。具体结果如图所示。
分析显示,线性层运行时间占50%,卷积占20%,聚合通信占20%,其余计算占10%,关键优化点明确指向线性层与通信效率。
下面是yuan2.0-102B进行实时推理的几个例子。
源2.0千亿模型通用服务器推理,尽在哔哩哔哩,深度解析,技术前沿一网打尽
NF8260G7,2U4路高密度设计服务器,支持高达16TB内存容量,轻松应对千亿乃至万亿参数大模型推理需求。搭载4颗配备AMX(高级矩阵扩展)AI加速功能的英特尔至强处理器,单机FP16算力超300TFlops,远超异构加速方案,为您的大数据处理提供强大动力。
五.结论
总的来说,如何实现千亿大模型推理是需要进行硬件、软件、模型三个方面进行综合考量的结果。NF8260G7服务器拥有16TB大内存容量和300TFlops以上的FP16算力,能满足千亿大模型推理的内存需求。此外,服务器中的4颗CPU采用了全链路UPI总线互连,传输速率高达16GT/s,保障了高效的数据传输。
在此基础上,采用了张量并行策略和NF4量化技术,我们实现了yuan2.0-102B的高效实时推理。为业界构建千亿大模型的高效推理方案提供了新的选择。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-

















 716
716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











