






神经网络的损失函数(Loss Function)是用来衡量模型预测结果与真实值之间的差异或错误程度的函数。损失函数在神经网络的训练过程中起着至关重要的作用,它的选择应根据具体的问题和任务来确定。
神经网络的损失函数是什么?
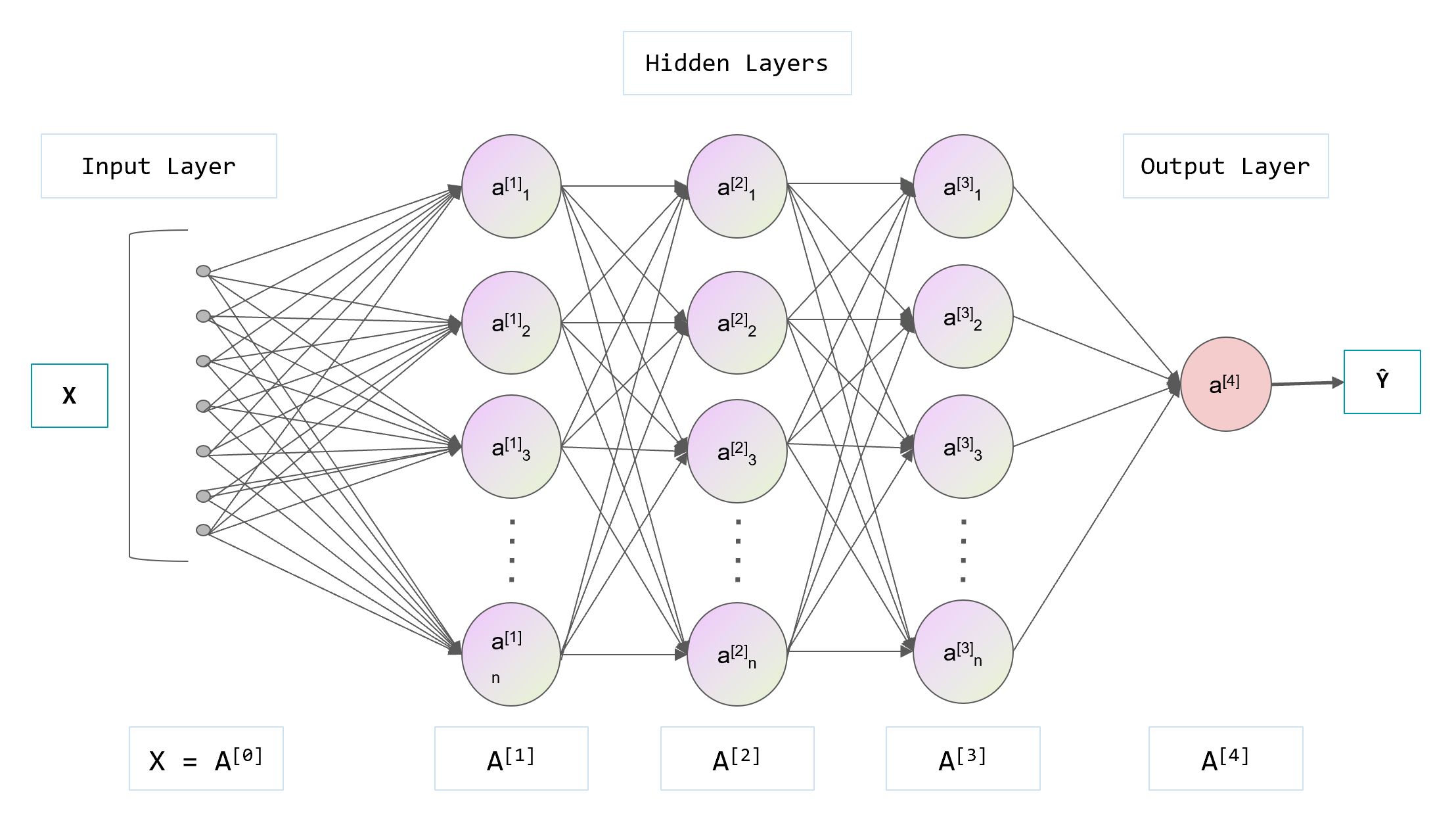
常见的神经网络损失函数包括:
-
均方误差(Mean Squared Error,MSE): MSE是回归问题中最常用的损失函数之一,它计算预测值与真实值之间的平方差的均值。适用于连续值的预测问题。
-
交叉熵损失(Cross-Entropy Loss): 交叉熵损失函数常用于分类问题,特别是多类别分类。它通过计算预测概率分布与真实标签之间的交叉熵来衡量模型的错误程度。
-
二分类交叉熵损失(Binary Cross-Entropy Loss): 适用于二分类问题,计算预测的二分类概率与真实标签之间的交叉熵。
-
多分类交叉熵损失(Categorical Cross-Entropy Loss): 适用于多分类问题,计算预测的分类概率分布与真实标签之间的交叉熵。
-
KL 散度损失(Kullback-Leibler Divergence Loss): KL 散度损失用于衡量两个概率分布之间的差异,常用于生成模型和无监督学习任务中。
-
Hinge 损失: 适用于支持向量机(SVM)和最大间隔分类器等模型,用于处理二分类问题。
如何选择适当的损失函数?

选择适当的损失函数应根据任务的特点和需求进行判断:
- 对于回归问题,均方误差通常是一个不错的选择,特别是当目标变量服从高斯分布时。
- 对于二分类问题,可以选择二分类交叉熵损失,它对模型的概率输出更加敏感。
- 对于多分类问题,多分类交叉熵损失是常见的选择,它适用于多个类别之间的分类问题。
- 对于生成模型和无监督学习任务,KL 散度损失可以用于度量概率分布之间的差异。
此外,还可以根据具体问题的特点,自定义损失函数。例如,根据任务需求加入正则化项,或设计特定的损失函数来处理异常值或不平衡数据等情况。
神经网络资料+60G人工智能学习籽料欢迎关注威 ❤公众号【咕泡AI】回复(123) 白嫖配套资料+60G入门进阶AI资源包+技术问题答疑+完整版视频 内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等 
在选择损失函数时,需要充分理解问题的背景和任务要求,并结合模型的特性和数据的特点进行判断,以获得更好的模型性能和训练效果。















 2145
2145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









