






YOLO(You Only Look Once)是一种高效的实时目标检测算法,它在训练过程中需要准备适当的数据集和相应的标注。本文将介绍YOLO算法的训练数据和标注方法,以及如何准备和处理数据集,为读者提供一个全面的指南。
YOLO的训练数据和标注方法是怎样的?如何准备和处理数据集?
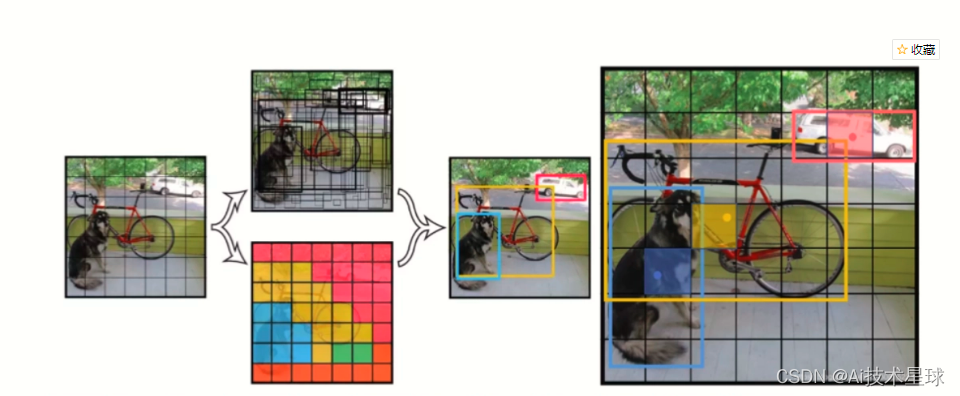


一、训练数据集的准备
- 数据收集:收集具有代表性的图像数据,涵盖目标类别的各种场景和角度。
- 数据划分:将数据集划分为训练集、验证集和测试集,通常按照比例划分,确保数据的独立性和可泛化性。
- 数据增强:对训练集进行数据增强操作,如旋转、缩放、平移、亮度调整等,增加数据的多样性和鲁棒性。
二、标注方法和格式
- 边界框标注:为每个目标对象标注边界框,通常使用矩形框表示,包括左上角和右下角的坐标。
- 类别标注:为每个目标对象分配相应的类别标签,标识对象所属的类别。
- 标注格式:常用的标注格式有YOLO标准格式和Pascal VOC格式,包括图像路径、边界框坐标和类别标签等信息。
三、数据集处理和预处理
- 图像加载:使用相应的库(如OpenCV)加载图像数据,并将其转换为模型可接受的格式(如张量)。
- 标注解析:解析标注文件,提取图像路径、边界框和类别信息,并将其与对应的图像进行关联。
- 数据增强:对图像和标注进行增强操作,如随机裁剪、旋转、翻转等,增加数据的多样性和泛化能力。
- 图像归一化:对图像进行归一化处理,将像素值缩放到一定范围内,以便网络模型更好地处理图像数据。
- 批处理和数据加载:将处理后的数据划分为批次,并使用适当的数据加载器加载批次数据以供训练。
-
感谢大家对文章的喜欢,欢迎关注威 ❤公众号【AI技术星球】回复(123) 白嫖YOLOv1-v8配套资料+60G入门进阶AI资源包+技术问题答疑+完整版视频 内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等
结论: 准备和处理数据集是进行目标检测模型训练的关键步骤,对于YOLO算法也不例外。本文介绍了YOLO训练数据集的准备、标注方法和数据集处理流程,帮助读者理解如何准备和处理数据以用于YOLO模型的训练。通过合理的数据集准备和标注,以及适当的数据处理和增强操作,可以提高模型的性能和泛化能力,从而实现更准确和稳定的目标检测结果。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









