







</h1>
<div class="clear"></div>
<div class="postBody">
yolo-idea
本文逐步介绍YOLO v1~v3的设计历程。
YOLOv1基本思想
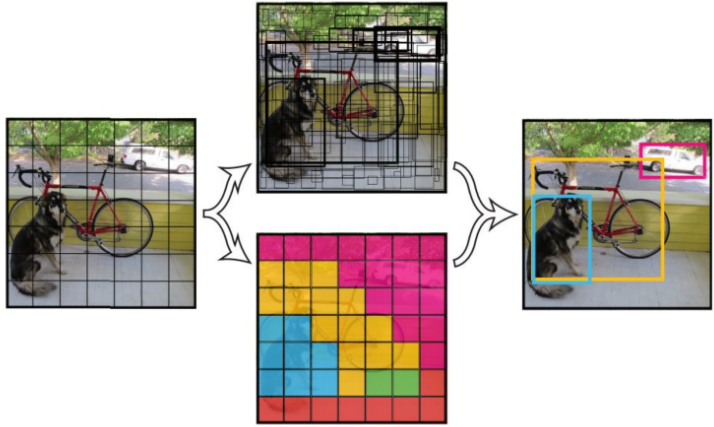
YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。

yolo-grid-predict
每个格子预测B个bounding box及其置信度(confidence score),以及C个类别概率。bbox信息(x,y,w,h)为物体的中心位置相对格子位置的偏移及宽度和高度,均被归一化.置信度反映是否包含物体以及包含物体情况下位置的准确性,定义为Pr(Object)×IOUtruthpred,其中Pr(Object)∈{0,1}Pr(Object)×IOUpredtruth,其中Pr(Object)∈{0,1}.
优缺点
优点
- 快速,pipline简单.
- 背景误检率低。
- 通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
但相比RCNN系列物体检测方法,YOLO具有以下缺点:
- 识别物体位置精准性差。
- 召回率低。在每个网格中预测固定数量的bbox这种约束方式减少了候选框的数量。
YOLO v.s. Faster R-CNN
- 统一网络:
YOLO没有显示求取region proposal的过程。Faster R-CNN中尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络.
相对于R-CNN系列的"看两眼"(候选框提取与分类,图示如下),YOLO只需要Look Once. - YOLO统一为一个回归问题
而R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
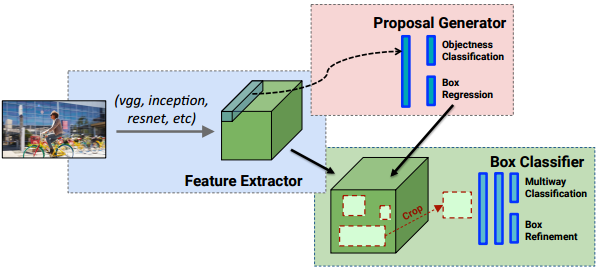
R-CNN pipline
Darknet 框架
Darknet 由 C 语言和 CUDA 实现, 对GPU显存利用效率较高(CPU速度差一些, 通过与SSD的Caffe程序对比发现存在CPU较慢,GPU较快的情况). Darknet 对第三方库的依赖较少,且仅使用了少量GNU linux平台C接口,因此很容易移植到其它平台,如Windows或嵌入式设备.
参考Windows 版 Darknet (YOLOv2) 移植, 代码在此.
region层:参数anchors指定kmeans计算出来的anchor box的长宽的绝对值(与网络输入大小相关),num参数为anchor box的数量,
另外还有bias_match,classes,coords等参数.在parser.c代码中的parse_region函数中解析这些参数,并保存在region_layer.num参数保存在l.n变量中;anchors保存在l.biases数组中.region_layer的前向传播中使用for(n = 0; n < l.n; ++n)这样的语句,因此,如果在配置文件中anchors的数量大于num时,仅使用前num个,小于时内存越界.
region层的输入和输出大小与前一层(1x1 conv)的输出大小和网络的输入大小相关.
Detection层: 坐标及类别结果输出层.
yolo层: 指定anchors等信息, 计算loss等. YOLOv3使用三个yolo层作为输出.
upsample层: 上采样层, 进行2倍上采样.
region层和Detection层均是YOLOv2模型所使用的层, upsample层和yolo层在YOLOv3中使用.
鉴于 Darknet 作者率性的代码风格, 将它作为我们自己的开发框架并非是一个好的选择. 可以在我们更为熟悉的Caffe等框架中复现YOLO网络. 这里有一份Caffe版YOLOv3实现(仅部署,不能训练), 另可参照其它框架的可训练代码.
参考
原文: https://www.cnblogs.com/makefile/p/YOLOv3.html ©
康行天下


18
0
<div class="clear"></div>
<div id="post_next_prev">
<a href="https://www.cnblogs.com/makefile/p/GAN.html" class="p_n_p_prefix">« </a> 上一篇: <a href="https://www.cnblogs.com/makefile/p/GAN.html" title="发布于 2018-03-23 11:30">生成式模型之 GAN</a>
<br>
<a href="https://www.cnblogs.com/makefile/p/metrics-mAP.html" class="p_n_p_prefix">» </a> 下一篇: <a href="https://www.cnblogs.com/makefile/p/metrics-mAP.html" title="发布于 2018-04-02 21:15">目标检测评价指标(mAP)</a>
</div><!--end: topics 文章、评论容器-->
评论列表
</div>
2018-03-27 15:31
<a id="a_comment_author_3934846" href="https://home.cnblogs.com/u/1350827/" target="_blank">jiahcen</a>
</div>
<div class="feedbackCon">
厉害了。。。
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#2楼
[楼主]
2018-03-27 15:33
<a id="a_comment_author_3934849" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ jiahcen
。。。我的国
https://pic.cnblogs.com/face/606386/20161018214555.png
。。。我的国
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2018-04-03 09:55
<a id="a_comment_author_3941024" href="https://home.cnblogs.com/u/1214055/" target="_blank">成了</a>
</div>
<div class="feedbackCon">
请问YOLOv3最后输出那些尺度的框?
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#4楼
[楼主]
2018-04-03 10:51
<a id="a_comment_author_3941096" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ 成了
应该是所有尺度的框合并后nms,输出score较高的框
https://pic.cnblogs.com/face/606386/20161018214555.png
应该是所有尺度的框合并后nms,输出score较高的框
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2018-07-27 15:19
<a id="a_comment_author_4030267" href="https://www.cnblogs.com/liuzhongfeng/" target="_blank">liurio</a>
</div>
<div class="feedbackCon">
总结的很好啊
https://pic.cnblogs.com/face/861394/20160413212251.png
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2018-10-10 14:22
<a id="a_comment_author_4085500" href="https://home.cnblogs.com/u/1434051/" target="_blank">JoeJo</a>
</div>
<div class="feedbackCon">
文章看过两次,之前是草草看过觉得图文配置特别好容易理解。
今天第二遍,发现内容很细致,很多细节都讲得很清楚,很棒的文章
今天第二遍,发现内容很细致,很多细节都讲得很清楚,很棒的文章
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2018-10-11 10:19
<a id="a_comment_author_4086348" href="https://home.cnblogs.com/u/1507720/" target="_blank">20181010</a>
</div>
<div class="feedbackCon">
很受用
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2018-11-07 15:26
<a id="a_comment_author_4108799" href="https://www.cnblogs.com/defineconst/" target="_blank">咸鱼翻身</a>
</div>
<div class="feedbackCon">
卫星影像使用YOLO V3,对原始文件需要拆分吗?
https://pic.cnblogs.com/face/u37018.jpg
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#9楼
[楼主]
2018-11-07 15:33
<a id="a_comment_author_4108810" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ 咸鱼翻身
如果图像大而目标小,是需要对图片进行划分成小图片的
https://pic.cnblogs.com/face/606386/20161018214555.png
如果图像大而目标小,是需要对图片进行划分成小图片的
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-03-10 01:12
<a id="a_comment_author_4197952" href="https://home.cnblogs.com/u/1360567/" target="_blank">馒头mjtb</a>
</div>
<div class="feedbackCon">
请问YOLOv3的3个Scale的检测图(13×13,26×26,52×52)是怎么检测物体的?
如果一张图片有一辆车和一个人,哪个检测图负责检测车?哪个检测图负责检测人?
如果一张图片有一辆车和一个人,哪个检测图负责检测车?哪个检测图负责检测人?
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-03-10 01:12
<a id="a_comment_author_4197953" href="https://home.cnblogs.com/u/1360567/" target="_blank">馒头mjtb</a>
</div>
<div class="feedbackCon">
I was wondering which one of the Three Detection Map(13*13, 26*26, 52*52) should responsible for predicting a object(i.e a Car) in a picture?
according to the labeled bonding box size of the car and the anchor size in the [yolo] layer?
If all the detection maps predict the car, how to combine the three output?
according to the labeled bonding box size of the car and the anchor size in the [yolo] layer?
If all the detection maps predict the car, how to combine the three output?
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#12楼
[楼主]
2019-03-10 20:03
<a id="a_comment_author_4198372" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ 馒头mjtb
这里不同尺度的特征图都检测用来检测所有的类别,没有对类别按大小区分,而是对anchor按大小划分到不同的特征,类似FPN与SSD。
https://pic.cnblogs.com/face/606386/20161018214555.png
这里不同尺度的特征图都检测用来检测所有的类别,没有对类别按大小区分,而是对anchor按大小划分到不同的特征,类似FPN与SSD。
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-03-10 20:14
<a id="a_comment_author_4198376" href="https://home.cnblogs.com/u/1360567/" target="_blank">馒头mjtb</a>
</div>
<div class="feedbackCon">
@ 康行天下
13×13的检测图分配大的anchor,小分辨率的特征图语义信息强;52×52的特征图分配小的anhor,大分辨率的特征图,位置信息强,但是我不明白13×13的检测特征图怎么和52×52的检测特征图合作啊?
方便详细一点的解释吗,举一个例子可以吧
13×13的检测图分配大的anchor,小分辨率的特征图语义信息强;52×52的特征图分配小的anhor,大分辨率的特征图,位置信息强,但是我不明白13×13的检测特征图怎么和52×52的检测特征图合作啊?
方便详细一点的解释吗,举一个例子可以吧
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#14楼
[楼主]
2019-03-10 20:20
<a id="a_comment_author_4198383" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ 馒头mjtb
在anchor分配之后,小目标就由大特征图上进行学习产生了,大目标在小特征图上,这就是一种分工合作啊。
https://pic.cnblogs.com/face/606386/20161018214555.png
在anchor分配之后,小目标就由大特征图上进行学习产生了,大目标在小特征图上,这就是一种分工合作啊。
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-03-10 20:35
<a id="a_comment_author_4198389" href="https://home.cnblogs.com/u/1360567/" target="_blank">馒头mjtb</a>
</div>
<div class="feedbackCon">
@ 康行天下
这样理解对吧:在anchor分配之后,小的目标也可以会被小的特征图学习,可能学习起来比较慢,possibility也会很小,可能都达不到0.25的阈值;大目标大的检测图学习也一样
这样理解对吧:在anchor分配之后,小的目标也可以会被小的特征图学习,可能学习起来比较慢,possibility也会很小,可能都达不到0.25的阈值;大目标大的检测图学习也一样
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#16楼
[楼主]
2019-03-10 20:42
<a id="a_comment_author_4198391" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ 馒头mjtb
嗯,对
https://pic.cnblogs.com/face/606386/20161018214555.png
嗯,对
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-04-17 19:12
<a id="a_comment_author_4233704" href="https://home.cnblogs.com/u/1586532/" target="_blank">Reminding</a>
</div>
<div class="feedbackCon">
博主你好,能不能用下你的图片,做ppt使用
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#18楼
[楼主]
2019-04-17 19:15
<a id="a_comment_author_4233705" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ Reminding
可以,图片也不全是我的
https://pic.cnblogs.com/face/606386/20161018214555.png
可以,图片也不全是我的
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-04-17 19:15
<a id="a_comment_author_4233708" href="https://home.cnblogs.com/u/1586532/" target="_blank">Reminding</a>
</div>
<div class="feedbackCon">
@ 康行天下
谢谢!
谢谢!
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-04-17 20:20
<a id="a_comment_author_4233766" href="https://home.cnblogs.com/u/1586532/" target="_blank">Reminding</a>
</div>
<div class="feedbackCon">
博主你好,还有其他问题请教,不知道方不方便加个微信或qq
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-07-22 18:30
<a id="a_comment_author_4306400" href="https://home.cnblogs.com/u/962771/" target="_blank">水翼lv</a>
</div>
<div class="feedbackCon">
写得很棒~加油
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#22楼
[楼主]
2019-07-24 09:00
<a id="a_comment_author_4307527" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ 水翼lv
谢谢!
https://pic.cnblogs.com/face/606386/20161018214555.png
谢谢!
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-07-25 17:49
<a id="a_comment_author_4308998" href="https://home.cnblogs.com/u/1301932/" target="_blank">唐康</a>
</div>
<div class="feedbackCon">
感觉是最棒的YOLO解读文章了~ 配合着darknet项目源代码和配置文件看的,理解得很透彻。
感谢作者!
感谢作者!
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#24楼
[楼主]
2019-07-30 11:14
<a id="a_comment_author_4312214" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ 唐康
过誉了!
https://pic.cnblogs.com/face/606386/20161018214555.png
过誉了!
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-08-23 15:22
<a id="a_comment_author_4335028" href="https://www.cnblogs.com/sdu20112013/" target="_blank">core!</a>
</div>
<div class="feedbackCon">
算loss的时候confidence score 的groud-truth是怎么算的 某个目标的中心落在了某个cell 相应的confidence的真值就是1 没落在真值就是0?
https://pic.cnblogs.com/face/583030/20181201135834.png
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
2019-08-23 15:47
<a id="a_comment_author_4335072" href="https://www.cnblogs.com/sdu20112013/" target="_blank">core!</a>
</div>
<div class="feedbackCon">
若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用𝜆𝜆𝜆𝜆𝜆𝜆=0.5修正iouErr。
这里博主能不能详细解释一下为什么会变相放大包含物体的grid的confidence loss的影响? 对没有目标的grid使用了更低的权重(0.5)以后,不更使得包含物体的grid的confidence loss影响更大了吗
https://pic.cnblogs.com/face/583030/20181201135834.png
这里博主能不能详细解释一下为什么会变相放大包含物体的grid的confidence loss的影响? 对没有目标的grid使用了更低的权重(0.5)以后,不更使得包含物体的grid的confidence loss影响更大了吗
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#27楼
[楼主]
2019-09-12 17:09
<a id="a_comment_author_4353582" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ sdu20112013
引用
算loss的时候confidence score 的groud-truth是怎么算的 某个目标的中心落在了某个cell 相应的confidence的真值就是1 没落在真值就是0?
我理解的是这样的,只有中心点所在的cell的值为1,其他为0
https://pic.cnblogs.com/face/606386/20161018214555.png
引用
算loss的时候confidence score 的groud-truth是怎么算的 某个目标的中心落在了某个cell 相应的confidence的真值就是1 没落在真值就是0?
我理解的是这样的,只有中心点所在的cell的值为1,其他为0
</div>
</div>
<div class="feedbackItem">
<div class="feedbackListSubtitle">
<div class="feedbackManage">
</div>
#28楼
[楼主]
4353607
2019/9/12 下午5:23:22
2019-09-12 17:23
<a id="a_comment_author_4353607" href="https://www.cnblogs.com/makefile/" target="_blank">康行天下</a>
</div>
<div class="feedbackCon">
@ sdu20112013
引用
若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用𝜆𝜆𝜆𝜆𝜆𝜆=0.5修正iouErr。
这里博主能不能详细解释一下为什么会变相放大包含物体的grid的confidence loss的影响? 对没有目标的grid使用了更低的权重(0.5)以后,不更使得包含物体的grid的confidence loss影响更大了吗
可以理解成样本不平衡问题,不含目标中心的格子数远多于含目标中心的格子数,这样即使不含目标中心的格子的损失很小,积少成多也会盖过含目标中心的格子的损失值的影响,优化时更应该关注含目标中心的格子带来的损失。另可以参考FocalLoss的思想。
https://pic.cnblogs.com/face/606386/20161018214555.png
引用
若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用𝜆𝜆𝜆𝜆𝜆𝜆=0.5修正iouErr。
这里博主能不能详细解释一下为什么会变相放大包含物体的grid的confidence loss的影响? 对没有目标的grid使用了更低的权重(0.5)以后,不更使得包含物体的grid的confidence loss影响更大了吗
可以理解成样本不平衡问题,不含目标中心的格子数远多于含目标中心的格子数,这样即使不含目标中心的格子的损失很小,积少成多也会盖过含目标中心的格子的损失值的影响,优化时更应该关注含目标中心的格子带来的损失。另可以参考FocalLoss的思想。
</div>
</div>















 2059
2059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









