







文章目录
一、HDFS工作机制
首先客户端创建任务,然后由资源管理器会把请求发往
nn节点(namenode),之后nn将会进行分配,比如说分配多少个block、复制几份等,然后nn将会把block分配的节点的地址回传给客户端,之后客户端会以数据包(流)的形式从第一个block往后面的数据节点上开始发送,开始存,同时也会把这个数据列表发往datanode节点,datanode节点将会把这个数据列表传递给其它的datanode,值得一提的是hadoop具备机架感应技术,能够自动感知哪些datanode位于同一机架中,这为数据最终的存储提供了一定的依据。
总结来说,nn上其实维护了两个列表:有关dn的列表、有关block的列表
HDFS属于Master与Slave结构。一个集群中只有一个NameNode,可以有多个DataNode。
HDFS存储机制保存了多个副本,当写入1T文件时,我们需要3T的存储,3T的网络流量带宽;系统提供容错机制,副本丢失或宕机可自动恢复,保证系统高可用性。
HDFS默认会将文件分割成block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,会导致内存的负担很重。
HDFS采用的是一次写入多次读取的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。
漫画形象解读链接:https://blog.csdn.net/hudiefenmu/article/details/37655491.
https://blog.csdn.net/zghsr1001/article/details/89926021.

HDFS容错机制:
- 节点失败监测机制:DN每隔3秒向NN发送心跳信号,10分钟收不到,认为DN宕机。
- 通信故障监测机制:只要发送了数据,接收方就会返回确认码。
- 数据错误监测机制:在传输数据时,同时会发送总和校验码。
参考链接:https://blog.csdn.net/xo_zhang/article/details/103581624?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242.
二、yarn资源管理器配置
工作原理描述:客户端运行一个任务、应用,将请求发送给rm,之后rm会到nm上,nm会把节点上拥有的资源汇报给rm,之后会在am上运行一个应用管理器,这个应用管理器会监控整个job的运行状态,之后会向rm注册一个地址,之后客户端可以直接连接am来获取整个job的进度。am应用管理器中是用java编写的代码,它会根据Job的具体情况来决定以怎样的方式来运行job,或者说要申请哪些资源来运行job。
am与nm之间不可以直接进行交互,所有的资源调度都要来自于rm。当申请的应用挂掉之后,nm可以实现job的启停,当整个job完成之后,nm会向rm申请注销资源。job的运行机制类似于容器

1.编辑配置文件
etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>

etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>

vim hadoop-env.sh %为mapred添加环境变量

2.命令行启动、网页访问测试
sbin/start-yarn.sh %启动yarn
sbin/stop-yarn.sh %关闭yarn
ResourceManager - http://localhost:8088/ %网页访问通过8088端口


三、Hadoop+zookeeper高可用
1.开启第五台虚拟机,并先配置好nfs,挂载相关目录



2.server1、2、3、4上初始操作

注意:删除临时文件在每个节点中都要操作

server2、3、4上:
[hadoop@server2 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server3 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server4 hadoop]$ bin/hdfs --daemon start journalnode
3.搭建zookeeper集群
安装 JDK
安装 zookeeper
tar zxf zookeeper-3.4.9.tar.gz
编辑 zoo.cfg 文件:
cp zoo_sample.cfg zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zookeeper
clientPort=2181server.1=172.25.0.2:2888:3888
server.2=172.25.0.3:2888:3888
server.3=172.25.0.4:2888:3888


各节点配置文件相同,并且需要在
/tmp/zookeeper 目录中创建 myid文件,写入一个唯一的数字,取值范围在 1-255。比如:172.25.0.2 节点的 myid 文件写入数字“1”,此数字与配置文件中的定义保持一致



在各节点启动服务:
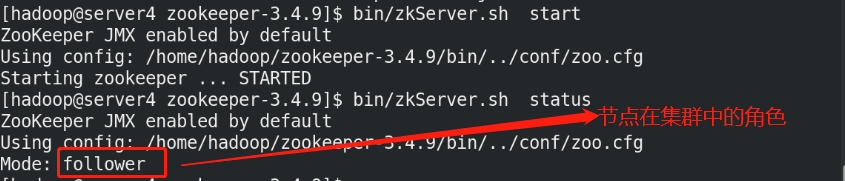
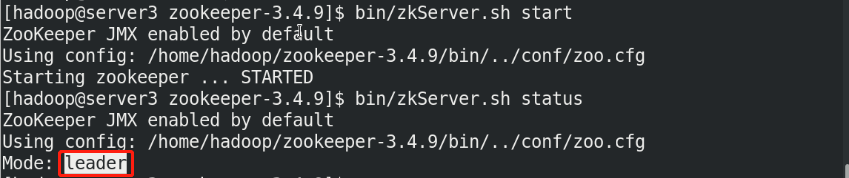
bin/zkServer.sh start
bin/zkServer.sh status



4.Hadoop配置
[hadoop@server1 hadoop]$ vim core-site.xml
[hadoop@server1 hadoop]$ vim hdfs-site.xml
[hadoop@server1 hadoop]$ bin/hdfs namenode -format %重新初始化
[hadoop@server1 hadoop]$ ls /tmp/ %初始化完成后/tmp目录中产生临时文件
hadoop-hadoop hadoop-hadoop-namenode.pid hsperfdata_hadoop
[hadoop@server1 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.1.5:/tmp %复制初始化后产生的文件到server5相关目录中保存server1和server5具有相同的配置




在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
sbin/hadoop-daemon.sh start journalnode
[hadoop@server2 ~]$ jps
1493 JournalNode
1222 QuorumPeerMain
1594 Jps

格式化 zookeeper (只需在server1上执行即可)
$ bin/hdfs zkfc -formatZK (注意大小写)
启动 hdfs 集群(只需在server1上执行即可)
$ sbin/start-dfs.sh



查看各节点状态:
[hadoop@server1 hadoop]$ jps
1431 NameNode
1739 DFSZKFailoverController
2013 Jps
[hadoop@server5 ~]$ jps
1191 NameNode
1293 DFSZKFailoverController
1856 Jps
[hadoop@server2 ~]$ jps
1493 JournalNode
1222 QuorumPeerMain
1400 DataNode
1594 Jps
[hadoop@server3 ~]$ jps
1578 Jps
1176 QuorumPeerMain
1329 DataNode
1422 JournalNode
[hadoop@server4 ~]$ jps
1441 Jps
1153 QuorumPeerMain
1239 DataNode
1332 JournalNod
进入zk集群查看数据写入相关信息:




5.访问测试与故障切换
访问测试:


server1往hdfs中上传数据时:

故障切换:






6.在上述高可用平台中加入ResourceManger服务实现yarn的高可用
编辑yarn-site.xml文件:
<configuration>
<!-- 配置可以在 nodemanager 上运行 mapreduce 程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 激活 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property><!-- 指定 RM 的集群 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<!-- 定义 RM 的节点-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.0.1</value>
</property>
<!-- 指定 RM2 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.0.5</value>
</property>
<!-- 激活 RM 自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置 RM 状态信息存储方式,有 MemStore 和 ZKStore-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置为 zookeeper 存储时,指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.0.2:2181,172.25.0.3:2181,172.25.0.4:2181</value>
</property>
</configuration>

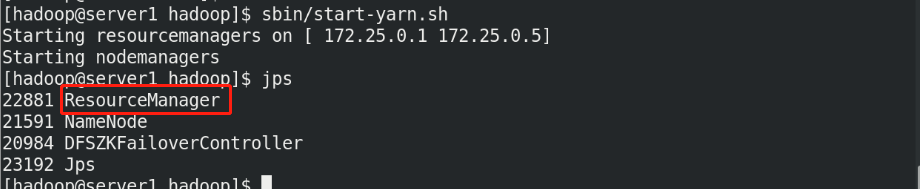
启动 yarn 服务
sbin/start-yarn.sh
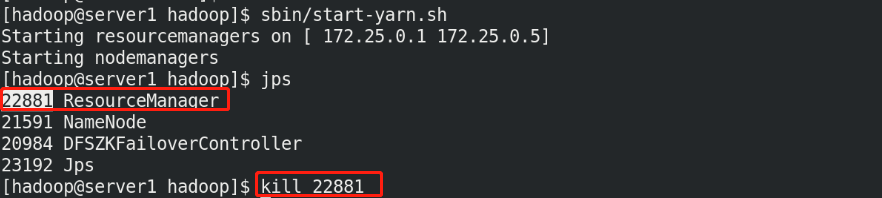
[hadoop@server1 hadoop]$ jps
6559 Jps
2163 NameNode
1739 DFSZKFailoverController5127 ResourceManager




测试yarn故障切换:




7.Hbase(hdfs非关系型数据库)分布式部署
hbase 配置
tar zxf hbase-1.2.4-bin.tar.gz
vim hbase-env.sh
export JAVA_HOME=/home/hadoop/java %指定 jdk
export HBASE_MANAGES_ZK=false %默认值是true,hbase在启动时自动开启zookeeper,如需自己维护zookeeper集群需设置为false
export HADOOP_HOME=/home/hadoop/hadoop %指定hadoop目录,否则hbase
无法识别 hdfs 集群配置


vim hbase-site.xml
<configuration>
<!-- 指定 region server 的共享目录,用来持久化 HBase。这里指定的 HDFS 地址
是要跟 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致。 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbase</value>
</property>
<!-- 启用 hbase 分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- Zookeeper 集群的地址列表,用逗号分割。默认是 localhost,是给伪分布式用
的。要修改才能在完全分布式的情况下使用。 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.25.0.2,172.25.0.3,172.25.0.4</value>
</property
cat regionservers %指定node节点
172.25.0.3
172.25.0.4
172.25.0.2


启动 hbase
主节点运行:
$ bin/start-hbase.sh
[hadoop@server1 hbase]$ jps
6559 Jps
2163 NameNode
1739 DFSZKFailoverController
5127 ResourceManager
1963 HMaster
备节点运行:
[hadoop@server5 hbase]$ bin/hbase-daemon.sh start master
1191 NameNode
3298 Jps
1293 DFSZKFailoverController
2757 ResourceManager
1620 HMaster
HBase Master 默认端口时 16000,还有个 web 界面默认在 Master 的 16010 端口
上,HBase RegionServers 会默认绑定 16020 端口,在端口 16030 上有一个展示
信息的界面




















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









