









在上一篇博文中,我们讲述了使用链地址法解决冲突的方法。这里我们介绍另一种方式:开地址法解决冲突。
基本思想:当关键码key的哈希地址H0 = hash(key)出现冲突时,以H0为基础,产生另一个哈希地址H1 ,如果H1仍然冲突,再以H0
为基础,产生另一个哈希地址H2 ,…,直到找出一个不冲突的哈希地址Hi ,将相应元素存入其中。根据增量序列的取值方式不同,相应的再散列方式也不同。主要有以下四种:
线性探测再散列
二次探测再散列
伪随机探测再散列
双散列法
(一)线性探测再散列

理解起来很简单,就是如果使用哈希函数映射的位置已经有数据,那么就依次顺序的向后查找,直到有一个位置还没有数据,将其放入。或者表已经满了。注意:表元素个数/表长<=1是基本要求(也就是 装填因子 )。
堆积现象
定义:用线性探测法处理冲突时,当表中i,i+1,i+2个位置上都有数据时,下一个散列地址如果是i,i+1,i+2和i+3都会要求填入i+3的位置,多个第一个散列地址不同的记录争夺同一个后继散列地址。
若散列函数不好、或装填因子a 过大,都会使堆积现象加剧。
我们将链地址法的代码稍加改动,status 保存状态,有EMPTY, DELETED, ACTIVE,删除的时候只是逻辑删除,即将状态置为DELETED,当插入新的key 时,只要不是ACTIVE 的位置都是可以放入,如果是DELETED位置,需要将原来元素先释放free掉,再插入。common.h
#ifndef _COMMON_H_
#define _COMMON_H_
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
} \
while (0)
#endif#ifndef _HASH_H_
#define _HASH_H_
typedef struct hash hash_t;
typedef unsigned int (*hashfunc_t)(unsigned int, void *);
hash_t *hash_alloc(unsigned int buckets, hashfunc_t hash_func);
void hash_free(hash_t *hash);
void *hash_lookup_entry(hash_t *hash, void *key, unsigned int key_size);
void hash_add_entry(hash_t *hash, void *key, unsigned int key_size,
void *value, unsigned int value_size);
void hash_free_entry(hash_t *hash, void *key, unsigned int key_size);
#endif /* _HASH_H_ */hash.c
#include "hash.h"
#include "common.h"
#include <assert.h>
typedef enum entry_status
{
EMPTY,
ACTIVE,
DELETED
} entry_status_t;
typedef struct hash_node
{
enum entry_status status;
void *key;
void *value;
} hash_node_t;
struct hash
{
unsigned int buckets;
hashfunc_t hash_func;
hash_node_t *nodes;
};
unsigned int hash_get_bucket(hash_t *hash, void *key);
hash_node_t *hash_get_node_by_key(hash_t *hash, void *key, unsigned int key_size);
hash_t *hash_alloc(unsigned int buckets, hashfunc_t hash_func)
{
hash_t *hash = (hash_t *)malloc(sizeof(hash_t));
//assert(hash != NULL);
hash->buckets = buckets;
hash->hash_func = hash_func;
int size = buckets * sizeof(hash_node_t);
hash->nodes = (hash_node_t *)malloc(size);
memset(hash->nodes, 0, size);
printf("The hash table has allocate.\n");
return hash;
}
void hash_free(hash_t *hash)
{
unsigned int buckets = hash->buckets;
int i;
for (i = 0; i < buckets; i++)
{
if (hash->nodes[i].status != EMPTY)
{
free(hash->nodes[i].key);
free(hash->nodes[i].value);
}
}
free(hash->nodes);
free(hash);
printf("The hash table has free.\n");
}
void *hash_lookup_entry(hash_t *hash, void *key, unsigned int key_size)
{
hash_node_t *node = hash_get_node_by_key(hash, key, key_size);
if (node == NULL)
{
return NULL;
}
return node->value;
}
void hash_add_entry(hash_t *hash, void *key, unsigned int key_size,
void *value, unsigned int value_size)
{
if (hash_lookup_entry(hash, key, key_size))
{
fprintf(stderr, "duplicate hash key\n");
return;
}
unsigned int bucket = hash_get_bucket(hash, key);
unsigned int i = bucket;
// 找到的位置已经有人存活,向下探测
while (hash->nodes[i].status == ACTIVE)
{
i = (i + 1) % hash->buckets;
if (i == bucket)
{
// 没找到,并且表满
return;
}
}
hash->nodes[i].status = ACTIVE;
if (hash->nodes[i].key) //释放原来被逻辑删除的项的内存
{
free(hash->nodes[i].key);
}
hash->nodes[i].key = malloc(key_size);
memcpy(hash->nodes[i].key, key, key_size);
if (hash->nodes[i].value) //释放原来被逻辑删除的项的内存
{
free(hash->nodes[i].value);
}
hash->nodes[i].value = malloc(value_size);
memcpy(hash->nodes[i].value, value, value_size);
}
void hash_free_entry(hash_t *hash, void *key, unsigned int key_size)
{
hash_node_t *node = hash_get_node_by_key(hash, key, key_size);
if (node == NULL)
return;
// 逻辑删除,置标志位
node->status = DELETED;
}
unsigned int hash_get_bucket(hash_t *hash, void *key)
{
// 返回哈希地址
unsigned int bucket = hash->hash_func(hash->buckets, key);
if (bucket >= hash->buckets)
{
fprintf(stderr, "bad bucket lookup\n");
exit(EXIT_FAILURE);
}
return bucket;
}
hash_node_t *hash_get_node_by_key(hash_t *hash, void *key, unsigned int key_size)
{
unsigned int bucket = hash_get_bucket(hash, key);
unsigned int i = bucket;
while (hash->nodes[i].status != EMPTY && memcmp(key, hash->nodes[i].key, key_size) != 0)
{
i = (i + 1) % hash->buckets;
if (i == bucket) // 探测了一圈
{
// 没找到,并且表满
return NULL;
}
}
// 比对正确,还得确认是否还存活
if (hash->nodes[i].status == ACTIVE)
{
return &(hash->nodes[i]);
}
// 如果运行到这里,说明i为空位或已被删除
return NULL;
}
#include "hash.h"
#include "common.h"
typedef struct stu
{
char sno[5];
char name[32];
int age;
} stu_t;
typedef struct stu2
{
int sno;
char name[32];
int age;
} stu2_t;
unsigned int hash_str(unsigned int buckets, void *key)
{
char *sno = (char *)key;
unsigned int index = 0;
while (*sno)
{
index = *sno + 4 * index;
sno++;
}
return index % buckets;
}
unsigned int hash_int(unsigned int buckets, void *key)
{
int *sno = (int *)key;
return (*sno) % buckets;
}
int main(void)
{
stu2_t stu_arr[] =
{
{ 1234, "AAAA", 20 },
{ 4568, "BBBB", 23 },
{ 6729, "AAAA", 19 }
};
hash_t *hash = hash_alloc(256, hash_int);
int size = sizeof(stu_arr) / sizeof(stu_arr[0]);
int i;
for (i = 0; i < size; i++)
{
hash_add_entry(hash, &(stu_arr[i].sno), sizeof(stu_arr[i].sno),
&stu_arr[i], sizeof(stu_arr[i]));
}
int sno = 4568;
stu2_t *s = (stu2_t *)hash_lookup_entry(hash, &sno, sizeof(sno));
if (s)
{
printf("%d %s %d\n", s->sno, s->name, s->age);
}
else
{
printf("not found\n");
}
sno = 1234;
hash_free_entry(hash, &sno, sizeof(sno));
s = (stu2_t *)hash_lookup_entry(hash, &sno, sizeof(sno));
if (s)
{
printf("%d %s %d\n", s->sno, s->name, s->age);
}
else
{
printf("not found\n");
}
hash_free(hash);
return 0;
}The hash table has allocate.
4568 BBBB 23
not found
The hash table has free.
(二)二次探测再散列
为改善“堆积”问题,减少为完成搜索所需的平均探查次数,可使用二次探测法。

可以证明:当表的长度>buckets为质数并且表的装填因子不超过0.5的时候,新的表项一定可以插入,而且任意一个位置不会被探查两次。
具体代码实现,跟前面讲过的线性探测再散列 差不多,只是探测的方法不同,但使用的数据结构也有点不一样。此外还实现了开裂处理(也就是表的长度要扩充一倍,然后取比他大的最小的一个质数),如果装载因子 a > 1/2; 则建立新表,将旧表内容拷贝过去,所以hash_t 结构体需要再保存一个size 成员,同样的原因,为了将旧表内容拷贝过去,hash_node_t 结构体需要再保存 *key 和 *value 的size。
hash.c
#include "hash.h"
#include "common.h"
#include <assert.h>
typedef enum entry_status
{
EMPTY,
ACTIVE,
DELETED
} entry_status_t;
typedef struct hash_node
{
enum entry_status status;
void *key;
unsigned int key_size; //在拷贝进新的哈希表时有用
void *value;
unsigned int value_size; //在拷贝进新的哈希表时有用
} hash_node_t;
struct hash
{
unsigned int buckets;
unsigned int size; //累加,如果size > buckets / 2 ,则需要开裂建立新表
hashfunc_t hash_func;
hash_node_t *nodes;
};
unsigned int next_prime(unsigned int n);
int is_prime(unsigned int n);
unsigned int hash_get_bucket(hash_t *hash, void *key);
hash_node_t *hash_get_node_by_key(hash_t *hash, void *key, unsigned int key_size);
hash_t *hash_alloc(unsigned int buckets, hashfunc_t hash_func)
{
hash_t *hash = (hash_t *)malloc(sizeof(hash_t));
//assert(hash != NULL);
hash->buckets = buckets;
hash->hash_func = hash_func;
int size = buckets * sizeof(hash_node_t);
hash->nodes = (hash_node_t *)malloc(size);
memset(hash->nodes, 0, size);
printf("The hash table has allocate.\n");
return hash;
}
void hash_free(hash_t *hash)
{
unsigned int buckets = hash->buckets;
int i;
for (i = 0; i < buckets; i++)
{
if (hash->nodes[i].status != EMPTY)
{
free(hash->nodes[i].key);
free(hash->nodes[i].value);
}
}
free(hash->nodes);
printf("The hash table has free.\n");
}
void *hash_lookup_entry(hash_t *hash, void *key, unsigned int key_size)
{
hash_node_t *node = hash_get_node_by_key(hash, key, key_size);
if (node == NULL)
{
return NULL;
}
return node->value;
}
void hash_add_entry(hash_t *hash, void *key, unsigned int key_size,
void *value, unsigned int value_size)
{
if (hash_lookup_entry(hash, key, key_size))
{
fprintf(stderr, "duplicate hash key\n");
return;
}
unsigned int bucket = hash_get_bucket(hash, key);
unsigned int i = bucket;
unsigned int j = i;
int k = 1;
int odd = 1;
while (hash->nodes[i].status == ACTIVE)
{
if (odd)
{
i = j + k * k;
odd = 0;
// i % hash->buckets;
while (i >= hash->buckets)
{
i -= hash->buckets;
}
}
else
{
i = j - k * k;
odd = 1;
while (i < 0)
{
i += hash->buckets;
}
++k;
}
}
hash->nodes[i].status = ACTIVE;
if (hash->nodes[i].key) 释放原来被逻辑删除的项的内存
{
free(hash->nodes[i].key);
}
hash->nodes[i].key = malloc(key_size);
hash->nodes[i].key_size = key_size; //保存key_size;
memcpy(hash->nodes[i].key, key, key_size);
if (hash->nodes[i].value) //释放原来被逻辑删除的项的内存
{
free(hash->nodes[i].value);
}
hash->nodes[i].value = malloc(value_size);
hash->nodes[i].value_size = value_size; //保存value_size;
memcpy(hash->nodes[i].value, value, value_size);
if (++(hash->size) < hash->buckets / 2)
return;
//在搜索时可以不考虑表装满的情况;
//但在插入时必须确保表的装填因子不超过0.5。
//如果超出,必须将表长度扩充一倍,进行表的分裂。
unsigned int old_buckets = hash->buckets;
hash->buckets = next_prime(2 * old_buckets);
hash_node_t *p = hash->nodes;
unsigned int size;
hash->size = 0; //从0 开始计算
size = sizeof(hash_node_t) * hash->buckets;
hash->nodes = (hash_node_t *)malloc(size);
memset(hash->nodes, 0, size);
for (i = 0; i < old_buckets; i++)
{
if (p[i].status == ACTIVE)
{
hash_add_entry(hash, p[i].key, p[i].key_size, p[i].value, p[i].value_size);
}
}
for (i = 0; i < old_buckets; i++)
{
// active or deleted
if (p[i].key)
{
free(p[i].key);
}
if (p[i].value)
{
free(p[i].value);
}
}
free(p); //释放旧表
}
void hash_free_entry(hash_t *hash, void *key, unsigned int key_size)
{
hash_node_t *node = hash_get_node_by_key(hash, key, key_size);
if (node == NULL)
return;
// 逻辑删除
node->status = DELETED;
}
unsigned int hash_get_bucket(hash_t *hash, void *key)
{
unsigned int bucket = hash->hash_func(hash->buckets, key);
if (bucket >= hash->buckets)
{
fprintf(stderr, "bad bucket lookup\n");
exit(EXIT_FAILURE);
}
return bucket;
}
hash_node_t *hash_get_node_by_key(hash_t *hash, void *key, unsigned int key_size)
{
unsigned int bucket = hash_get_bucket(hash, key);
unsigned int i = 1;
unsigned int pos = bucket;
int odd = 1;
unsigned int tmp = pos;
while (hash->nodes[pos].status != EMPTY && memcmp(key, hash->nodes[pos].key, key_size) != 0)
{
if (odd)
{
pos = tmp + i * i;
odd = 0;
// pos % hash->buckets;
while (pos >= hash->buckets)
{
pos -= hash->buckets;
}
}
else
{
pos = tmp - i * i;
odd = 1;
while (pos < 0)
{
pos += hash->buckets;
}
i++;
}
}
if (hash->nodes[pos].status == ACTIVE)
{
return &(hash->nodes[pos]);
}
// 如果运行到这里,说明pos为空位或者被逻辑删除
// 可以证明,当表的长度hash->buckets为质数且表的装填因子不超过0.5时,
// 新的表项 x 一定能够插入,而且任何一个位置不会被探查两次。
// 因此,只要表中至少有一半空的,就不会有表满问题。
return NULL;
}
unsigned int next_prime(unsigned int n)
{
// 偶数不是质数
if (n % 2 == 0)
{
n++;
}
for (; !is_prime(n); n += 2); // 不是质数,继续求
return n;
}
int is_prime(unsigned int n)
{
unsigned int i;
for (i = 3; i * i <= n; i += 2)
{
if (n % i == 0)
{
// 不是,返回0
return 0;
}
}
// 是,返回1
return 1;
}

(四)双散列法

下面是一定数据下各种方式的性能分析:
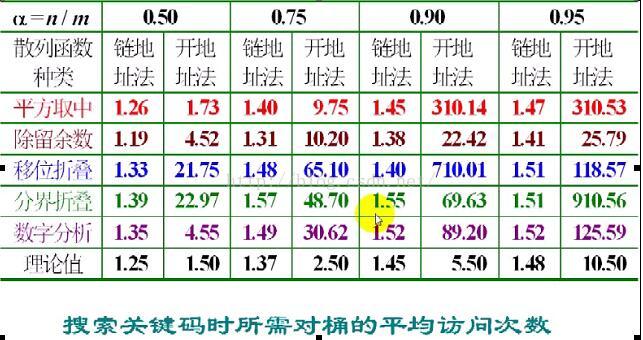
我们可以得出一般性结论:
处理冲突的方法最好采用链地址法,哈希函数使用除留余数法(其中哈希函数最好与关键码的特征关联性强一些)性能最佳。














 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









