







1 多项式扩展的作用
在线性回归中,多项式扩展是种比较常见的技术,可以通过增加特征的数量和多项式项的次数来提高模型的拟合能力。
举个例子,多项式扩展可以将一个包含 n 个特征的样本向量 x 扩展为一个包含 k 个特征的样本向量,其中 k 可以是 n 的任意多项式。例如,如果我们使用二次多项式扩展,可以将样本向量[x1, x2]扩展为一个包含原始特征和交叉项的新特征向量,例如 [x1, x2, x1^2, x2^2, x1*x2]。这些新特征可以捕捉到更丰富的特征组合和非线性关系,从而提高模型的拟合能力。
在多项式扩展后,我们可以使用线性回归模型来拟合扩展后的数据,并计算模型的拟合误差来评估模型的性能。通常,随着多项式项的增加,模型的拟合误差会降低,但同时也可能过度拟合训练数据,并在新数据上表现较差。
因此,在使用多项式扩展时需要注意平衡模型的拟合能力和泛化能力,并使用正则化等技术来避免过度拟合。
2 多项式扩展的函数
在Python中,可以使用 Scikit-learn 库中的 PolynomialFeatures 类来进行多项式扩展。
PolynomialFeatures 类可以将原始特征矩阵 X 转换为包含多项式特征的新特征矩阵。在转换过程中,PolynomialFeatures 可以指定扩展的次数,也就是多项式的最高次数。例如,如果指定次数为 2,PolynomialFeatures 将原始特征矩阵 X 扩展为包含所有一次项、二次项和交叉项的新特征矩阵。
2.1 接收参数
PolynomialFeatures用于创建一个多项式扩展类,其接收参数为:
- degree:指定多项式的最高次数。默认为 2。
- interaction_only:布尔值,表示是否仅包含交叉项。如果将其设置为 True,则仅包含原始特征之间的交叉项,而不包括原始特征本身(比如 x 2 x^{2} x2这种)。默认为 False。
- include_bias:布尔值,表示是否包含常数项。如果将其设置为 True,则在扩展特征矩阵中包含常数项,即所有元素都为 1 的一列。默认为 True。
创建类后,fit_transform 方法用于将原始特征矩阵 X 转换为多项式扩展后的新特征矩阵 X_poly。该函数的接收参数为原始数据,即:
X_poly = poly.fit_transform(X)
这里的fit_transform函数实际为fit函数+transform函数。当我们执行预测时,单独使用transform函数即可(见2.2中的例子)。
作为sklearn中的fit函数,该函数同样可以接收y,只不过y在被函数接收后不会进行任何计算。
2.2 多项式扩展示例
这里提供一个简单的二项式扩展的例子。
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
# 创建一些虚拟数据
X = np.array([[1, 2], [3, 4], [5, 6]])
# 定义二次多项式扩展器
poly = PolynomialFeatures(degree=2)
# 进行二次多项式扩展
X_poly = poly.fit_transform(X)
# 打印扩展后的特征矩阵
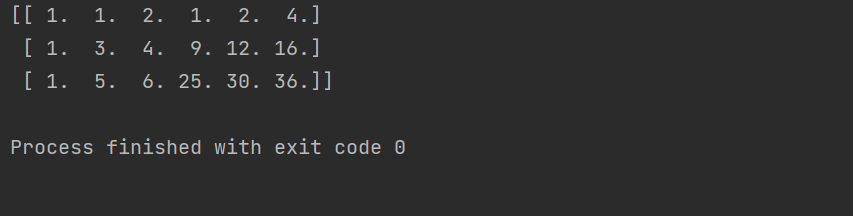
print(X_poly)
在上面的代码中,我们首先创建了一个包含 3 个样本和 2 个特征的虚拟数据集 X。然后,我们创建了一个 PolynomialFeatures 对象,并将其次数设置为 2。接下来,我们使用 fit_transform 方法将 X 扩展为一个包含所有一次项、二次项和交叉项的新特征矩阵 X_poly。最后,我们打印出扩展后的特征矩阵 X_poly,结果如下:
3 多项式扩展的完整实例
此处以波士顿房价数据集为例。该数据集目前可以直接从sklearn.datasets数据集中导出。导出是会有未来版本警告,即未来的版本由于伦理问题会删除该数据集,目前大家直接忽视警告即可。
完整代码如下:
# 从Scikit-learn库中导入波士顿房价数据集
from sklearn.datasets import load_boston
# 导入所需的类和函数
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
# 提取特征和目标变量
X = boston.data # 特征矩阵
y = boston.target # 目标变量(房价)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=66)
# 多项式扩展
poly = PolynomialFeatures(degree=2) # 创建一个2次多项式特征扩展器
X_train_poly = poly.fit_transform(X_train) # 对训练集进行多项式扩展
X_test_poly = poly.transform(X_test) # 对测试集进行多项式扩展
# 拟合多项式回归模型
model = LinearRegression() # 创建一个线性回归模型
model.fit(X_train_poly, y_train) # 在扩展后的训练集上拟合线性回归模型
# 在测试集上进行预测并计算MSE
y_pred = model.predict(X_test_poly) # 对扩展后的测试集进行预测
mse = mean_squared_error(y_test, y_pred) # 计算MSE
# 打印MSE
print(mse)
代码中的讲解全部放倒了注释之中,大家理解起来应该没有障碍。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











