






第一部分:认识RAG
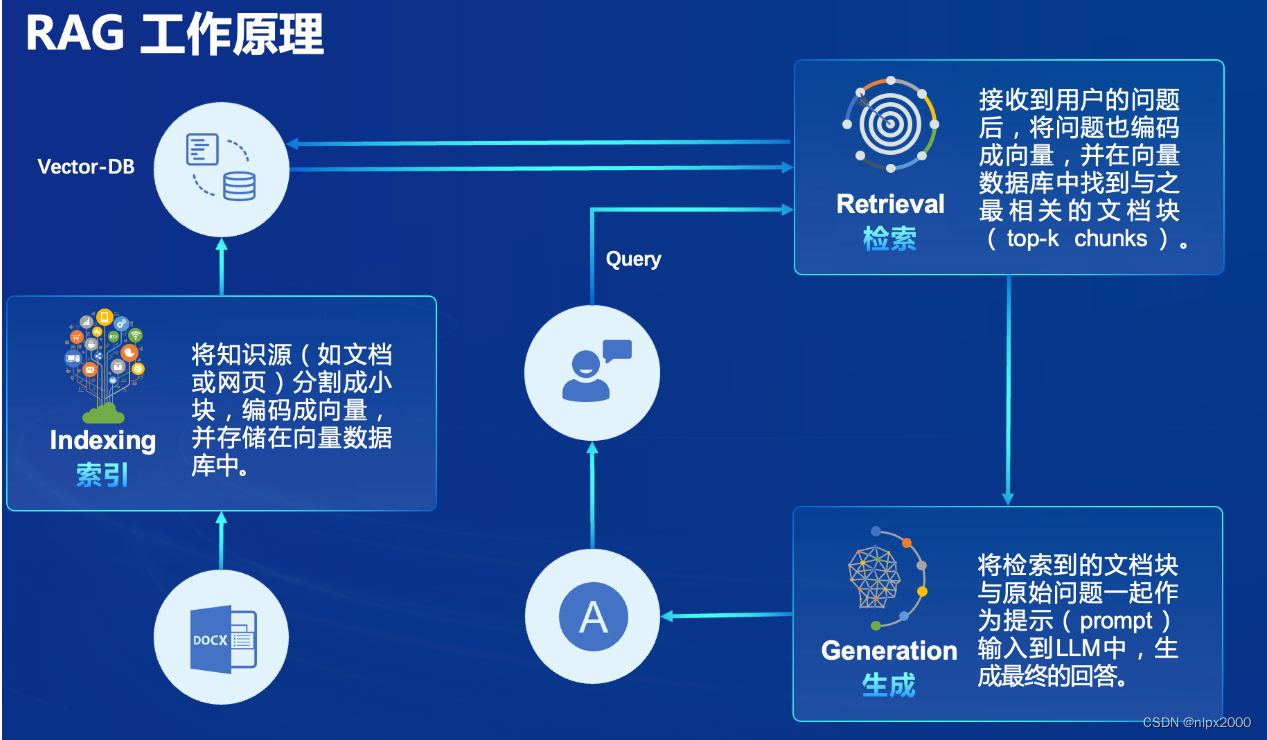
RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,结合外部知识库生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。
第二部分:大神茴香豆
茴香豆应用了 RAG 技术,可以快速、高效的搭建自己的知识领域助手。一张对比图让你清楚茴香豆的意义。ternLM2-Chat-7B 训练数据库中并没有收录到它的相关信息。左图中关于 huixiangdou 的 3 轮问答均未给出准确的答案。右图未对 InternLM2-Chat-7B 进行任何增训的情况下,通过 RAG 技术实现的新增知识问答。后面经过作业实践,更清晰了解他的面目及强悍的性质。茴香豆配置文件有着丰富的功能,可以根据业务需求调整 Prompt,配置多模态,agent、打造独有的茴香豆知识助手。

第三部分:理论学习实践
通过RAG技术概述、原理,RAG与微调的关系、向量数据库的作用、流程实列、发展进程、常见优化方法、评估和测试等多个维度、角度了解认识RAG。RAG技术具体应用茴香豆,介绍带你进入茴香豆的起源,当前场景应用的难点,具体场景的应用,茴香豆的多方面核心特性,运用架构,构建步骤方法,应用中的工作流与多来源检索、混合大模型、多重评分拒答、多种手段、确保回答合规的完整工作流,更深一步的了解熟悉茴香豆的特点以及在实际应用中的作用。

学习视频请戳:茴香豆:搭建你的 RAG 智能助理_哔哩哔哩_bilibili茴香豆:零代码搭建你的 RAG 智能助理1、RAG 基础知识介绍2、茴香豆介绍3、茴香豆搭建知识库实战文档地址:https://github.com/InternLM/Tutorial/blob/camp2/huixiangdou/readme.md还没有报名的同学戳此链接报名哟:https://www.wjx.cn/vm/tUX8dEV.aspx?udsid=240962觉得不错,欢迎 Star, 视频播放量 6165、弹幕量 1、点赞数 114、投硬币枚数 56、收藏人数 168、转发人数 38, 视频作者 OpenMMLab, 作者简介 构建国际领先的计算机视觉开源算法平台 | 小助手:OpenMMLabwx 微信公众号同名,相关视频:大模型时代必学!吴恩达大佬出的【langchain+RAG】教程可太适合学习了!中英字幕,13讲全!—大模型、吴恩达大模型教程,OpenCompass 大模型评测实战,一次搞懂RAG评估,三个角度LangChain,LlamaIndex,RAGAS,吹爆!这可能是导师都不讲的Chatgpt论文写作指导教程,哈工大博士手把手带你亲历论文从选题到投稿完整版,还搞不定一篇论文你来打我!,LMDeploy 量化部署 LLM-VLM 实践,【全748集】字节大佬终于把 AI大模型(LLM)讲清楚了!通俗易懂,2024最新内部版,学完即就业!AGI商业化落地创业营,一门非常落地的AI大模型创业课!!,「通过增强PDF结构识别,革新检索增强生成技术(RAG)」系列讲解视频——第二期:两种PDF解析和分块方法的对比,Lagent & AgentLego 智能体应用搭建,🔥 从零开始学习 RAG|5️⃣ 重排序上下文,【全748集】字节大佬终于把 AI大模型(LLM)讲清楚了!通俗易懂,2024最新内部版,学完即就业!AGI商业化落地创业营,一门非常落地的AI大模型创业课![]() https://www.bilibili.com/video/BV1QA4m1F7t4/学习茴香豆部署群聊助手请戳:零编程玩转大模型,学习茴香豆部署群聊助手_哔哩哔哩_bilibili“茴香豆”是一个基于 LLM 的领域知识助手。特点:应对群聊这类复杂场景,解答用户问题的同时,不会消息泛滥提出一套解答技术问题的算法 pipeline部署成本低,只需要 LLM 模型满足 4 个 trait 即可解答大部分用户问题,见技术报告 arxiv2401.08772, 视频播放量 2133、弹幕量 0、点赞数 39、投硬币枚数 26、收藏人数 44、转发人数 10, 视频作者 巅峰大会长, 作者简介 ,相关视频:大模型时代必学!吴恩达大佬出的【langchain+RAG】教程可太适合学习了!中英字幕,13讲全!—大模型、吴恩达大模型教程,20分钟打造基于大模型的交互式对话应用 无需本地部署、无硬件要求,零基础即可上手学习全球领先的中英双语大模型!,openmmlab 硬件模型库简介,llama3这么火,我把llama3微调、量化、部署、做下游应用、配置技能、知识库检索等都讲明白了,草履虫都能学会系列!—llama3、大模型,大模型全栈总览,「通过增强PDF结构识别,革新检索增强生成技术(RAG)」系列讲解视频——第一期:介绍检索增强生成RAG,最新开源大语言模型GLM-4模型详细教程—环境配置+模型微调+模型部署+效果展示,「通过增强PDF结构识别,革新检索增强生成技术(RAG)」系列讲解视频——第三期:PDF识别对RAG回答质量影响的定量评估,最新Qwen2大模型环境配置+LoRA模型微调+模型部署详细教程!真实案例对比GLM4效果展示!,一次搞懂RAG评估,三个角度LangChain,LlamaIndex,RAGAS
https://www.bilibili.com/video/BV1QA4m1F7t4/学习茴香豆部署群聊助手请戳:零编程玩转大模型,学习茴香豆部署群聊助手_哔哩哔哩_bilibili“茴香豆”是一个基于 LLM 的领域知识助手。特点:应对群聊这类复杂场景,解答用户问题的同时,不会消息泛滥提出一套解答技术问题的算法 pipeline部署成本低,只需要 LLM 模型满足 4 个 trait 即可解答大部分用户问题,见技术报告 arxiv2401.08772, 视频播放量 2133、弹幕量 0、点赞数 39、投硬币枚数 26、收藏人数 44、转发人数 10, 视频作者 巅峰大会长, 作者简介 ,相关视频:大模型时代必学!吴恩达大佬出的【langchain+RAG】教程可太适合学习了!中英字幕,13讲全!—大模型、吴恩达大模型教程,20分钟打造基于大模型的交互式对话应用 无需本地部署、无硬件要求,零基础即可上手学习全球领先的中英双语大模型!,openmmlab 硬件模型库简介,llama3这么火,我把llama3微调、量化、部署、做下游应用、配置技能、知识库检索等都讲明白了,草履虫都能学会系列!—llama3、大模型,大模型全栈总览,「通过增强PDF结构识别,革新检索增强生成技术(RAG)」系列讲解视频——第一期:介绍检索增强生成RAG,最新开源大语言模型GLM-4模型详细教程—环境配置+模型微调+模型部署+效果展示,「通过增强PDF结构识别,革新检索增强生成技术(RAG)」系列讲解视频——第三期:PDF识别对RAG回答质量影响的定量评估,最新Qwen2大模型环境配置+LoRA模型微调+模型部署详细教程!真实案例对比GLM4效果展示!,一次搞懂RAG评估,三个角度LangChain,LlamaIndex,RAGAS![]() https://www.bilibili.com/video/BV1S2421N7mn
https://www.bilibili.com/video/BV1S2421N7mn
第四部分:作业说明
本次基础作业与进阶作业均在InternLM Studio开发环境,OpenXLab浦源 - 应用中心完成。
基础大模型:internlm2-chat-7b
BCE向量模型:bce-embedding-base_v1
bce-reranker-base_v1
茴香豆:huixiangdou
第五部分:基础作业
进行作业前,带你先了解下web版本茴香豆基本服务结构。
整个服务分 前后端 和 算法 两部分:
- 中间用 redis queue 通信,可以视做消息总线
- 后端接受所有业务侧消息,例如微信、飞书、浏览器等
- 算法无状态,只关心算法相关的任务。可分布式扩展以应对高吞吐需求

一、在线茴香豆Web版中创建自己领域的知识回答助手
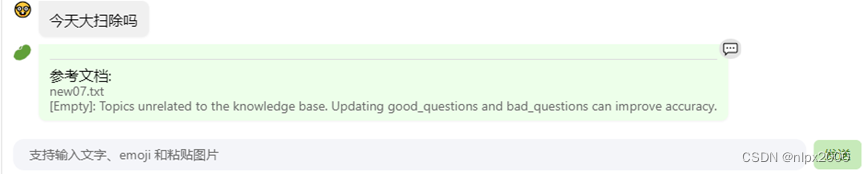
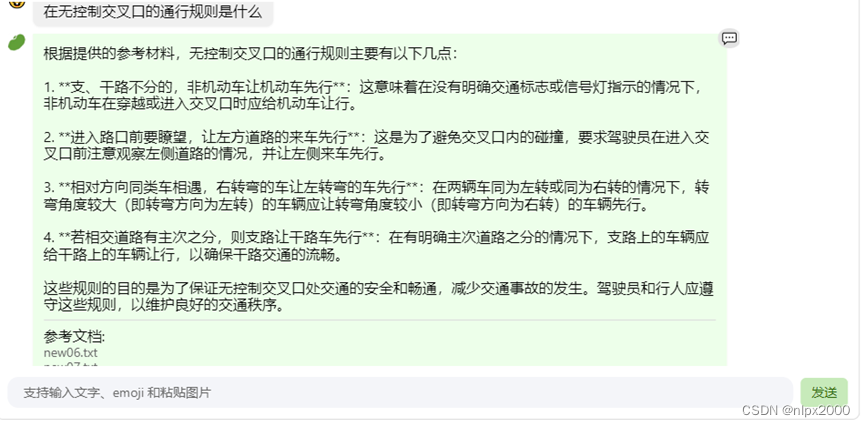
在OpenXLab浦源 - 应用中心地址Web版创建自己领域知识回答助手,首先注册用户知识库,用户知识库名称随意,密码根据自己实际填写,不用填写各种信息,点击“前往”按钮,进入道茴香豆web页面,会看到知识库已经创建完成,为了完成搭建自己的领域知识库,准备好自己领域知识文档,支持txt、word、ppt、pdf、excel、html等格式,点击“查看或者上传”按钮,在对话框中添加自己的知识文档,确认上传后,可以在聊天测试区域中查询知识问题,茴香豆根据问题查找提供上传的文档作为参考材料,生成相应的回答,可以设置正反例来控制与领域知识无关的问题与回答。当问题格式有误或者不是问题格式时,茴香豆所给出的回答给予提示:“[Empty]: query is not a question”。RAG技术在茴香豆知识助手的应用,体现了领域知识快速获取,不需要对知识训练,确定回答的问题利用基础模型提取关键词,在知识库中检索相似的句子,综合问题和检索到的句子生成答案,能够准确识别与问题相关的回答。We版提供了简单易用的配置等工具,可以快速地实现部署自己的领域知识回答助手,集成微信或者飞书群聊见进阶作业章节。
1.登录页面

2.注册用户登录,名称随意

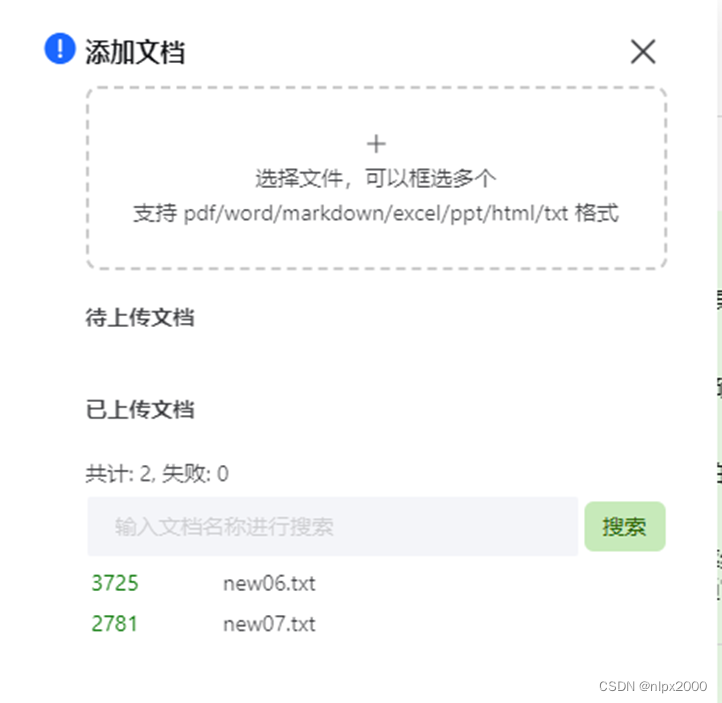
3.上传文档构建自己的交通安全知识库
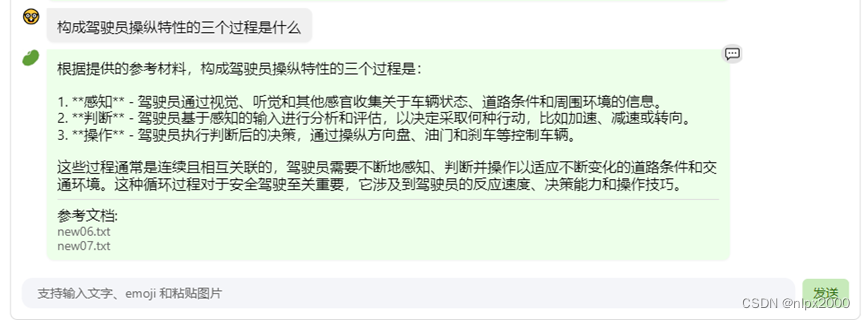
4.对话


二、服务器部署茴香豆Web版
1.部署redis

2.设置环境变量

3.编译前端&运行后端服务
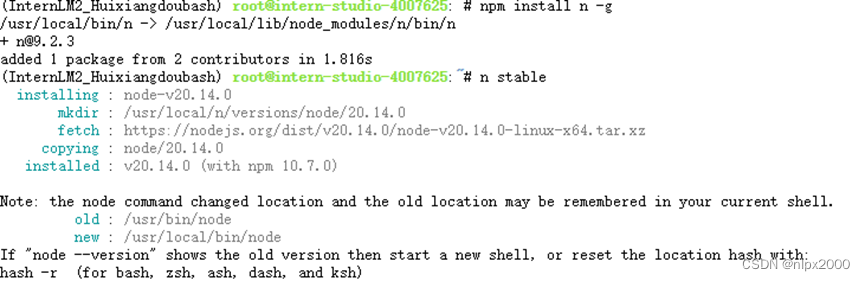
编译项目
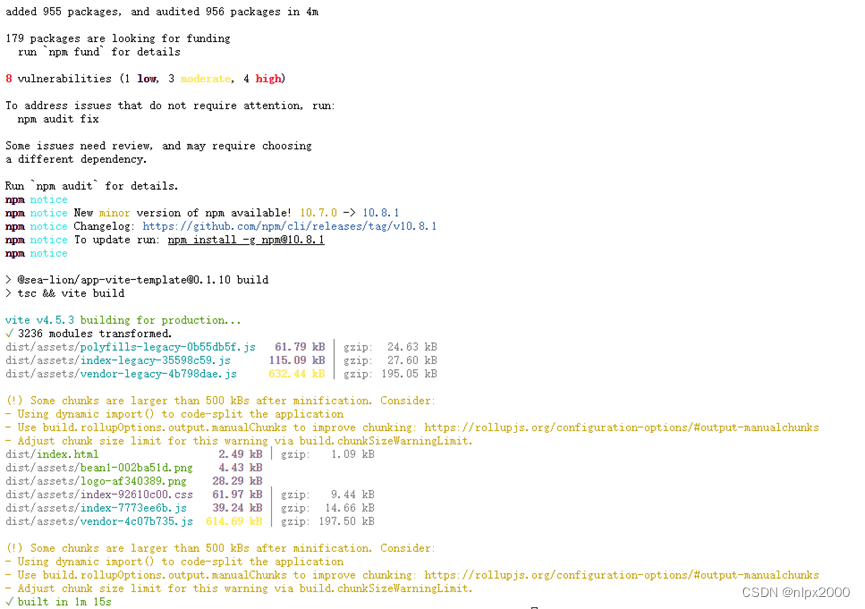
安装依赖

运行后端
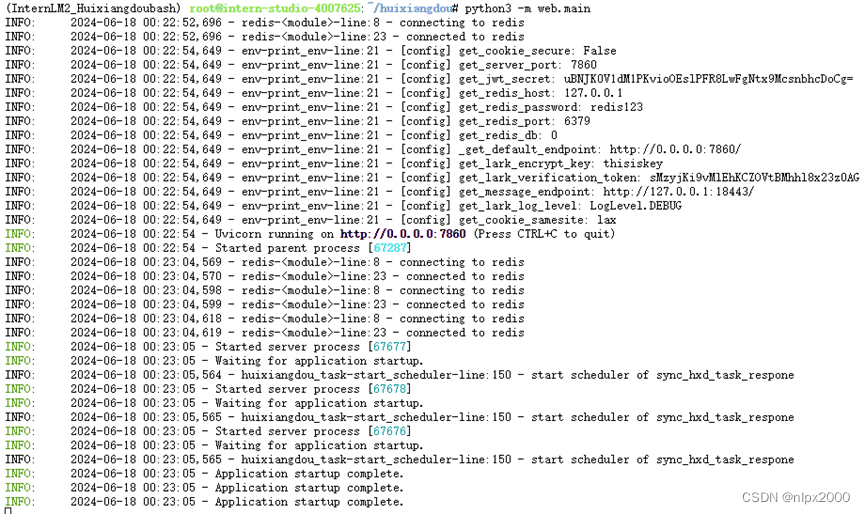
4.运行算法
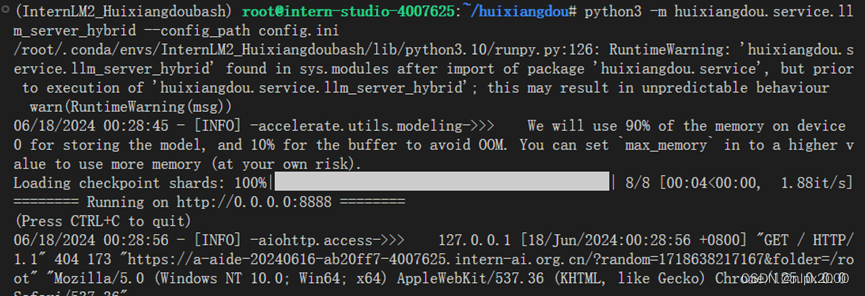
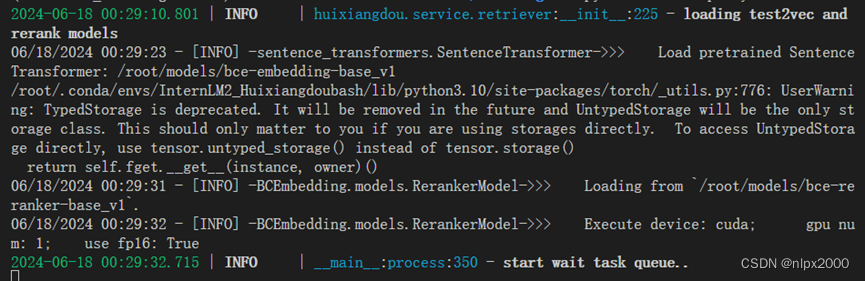
5.测试打开服务器,创建知识库测试效果

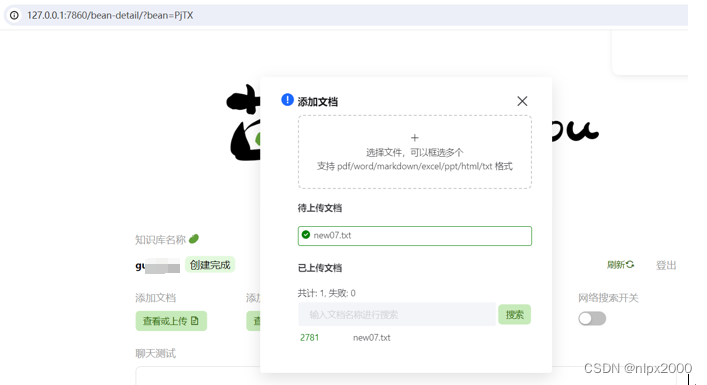


三、InternLM Studio上部署茴香豆技术助手
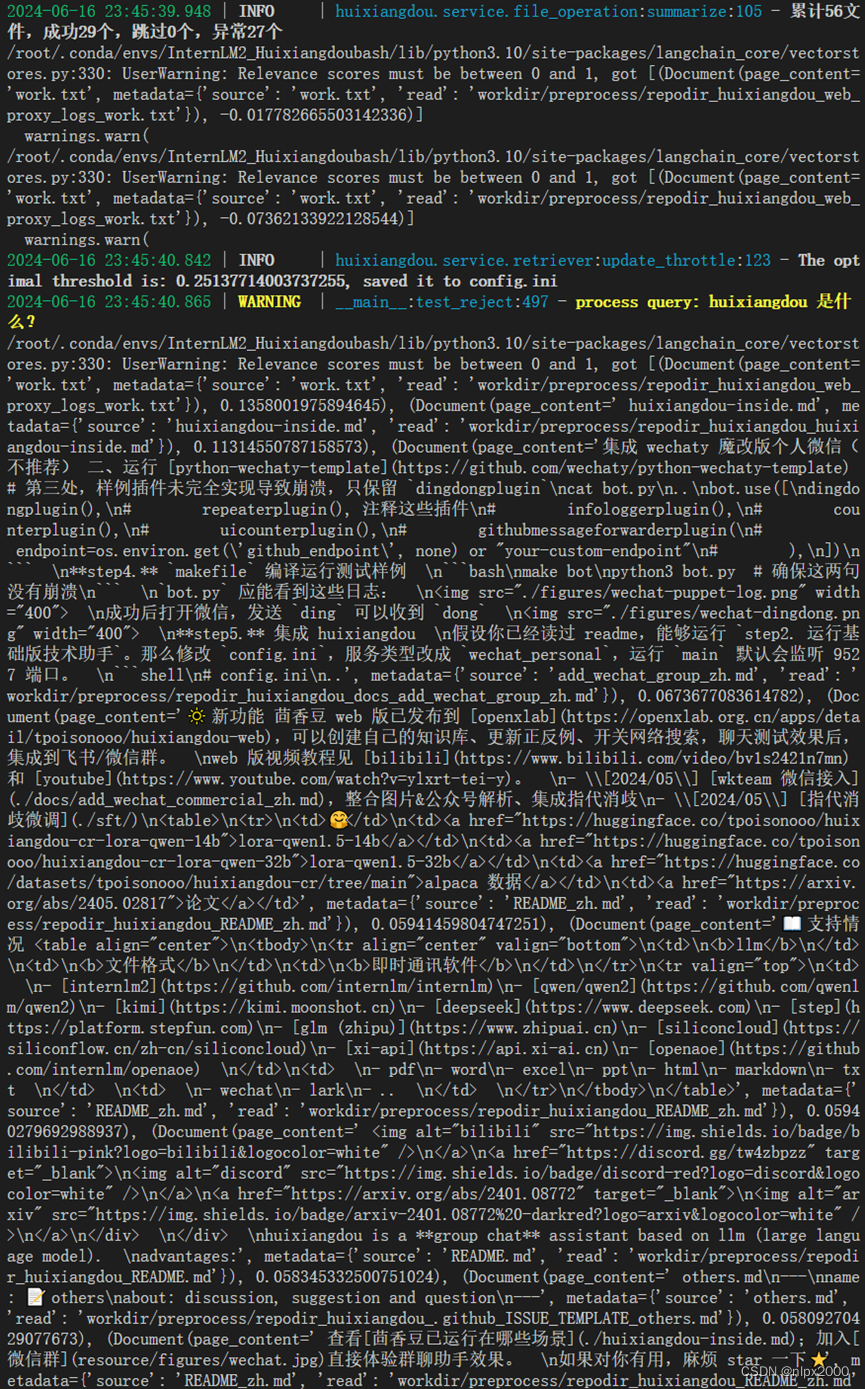
这节学习作业至关重要,不仅了解RAG在茴香豆中技术应用,而且了解实际应用部署中的技术细节,打通整个流程的讲解让你熟悉RAG实际应用的方法与方案。配置基础环境与其他学习章节基本相同,向量库采用bce-embedding-base基本模型,大模型采用internlm2-chat-7b模型,学习做过程使用软链接方式,实际工程应用中部署在云端或者本地,也可以对大模型进行微调以适应工程行业。茴香豆clone安装前,一定要安装依赖库,依赖库库安装不全的在创建知识库时报错。使用茴香豆搭建RAG助手修改config.ini配置文件后,一定要检查配置文件配置项修改是否注释的已经注释,在在创建知识库时报错。创建知识库添加接受问题列表修改good_questions.json文件与决绝问题列表修改bad_questions.json文件,切记检查文件修改是否正确,行中包含非法字符,创建 RAG 检索过程中使用的向量数据库时报错,报错信息见截图部分说明。新增知识以向量数据库的形式存储在 workdir 文件夹下,检索过程中,茴香豆会将输入问题与两个列表中的问题在向量空间进行相似性比较,判断是否应该回答,避免聊天过程中泛滥问答,通过命令sed修改main.py文件填入拒接受问题和接受问题进行测试效果。
1.配置基本环境

2.下载基础文件

3.下载安装茴香豆
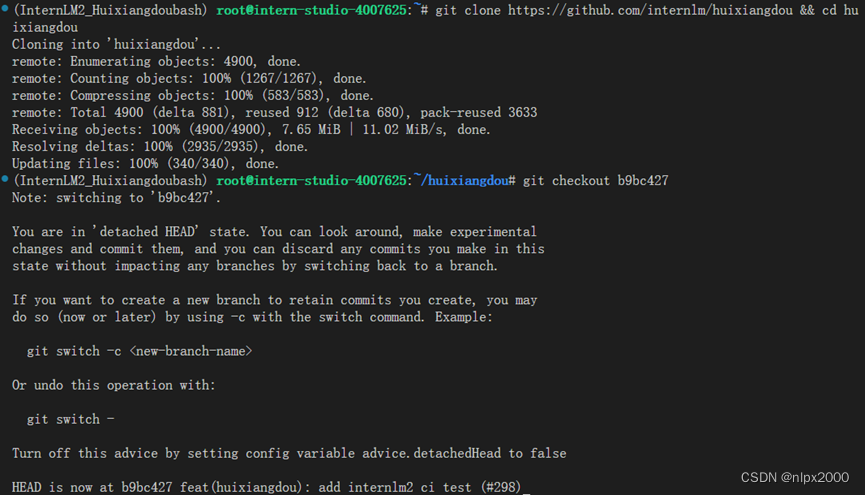
4.使用茴香豆搭建RAG助手
4.1修改配置文件
注意检查/root/huixiangdou/config.ini文件,执行sed -i '29s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini命令时,原有local_llm_path配置可能没有注释在运行创建 RAG 检索过程中使用的向量数据库时报错。

4.2创建知识库
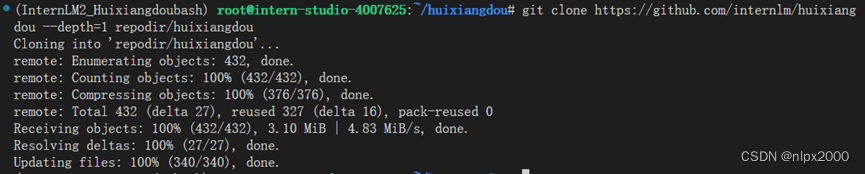
增加茴香豆相关的问题到接受问题示例中和再创建一个测试用的问询列表,用来测试拒答流程是否起效.
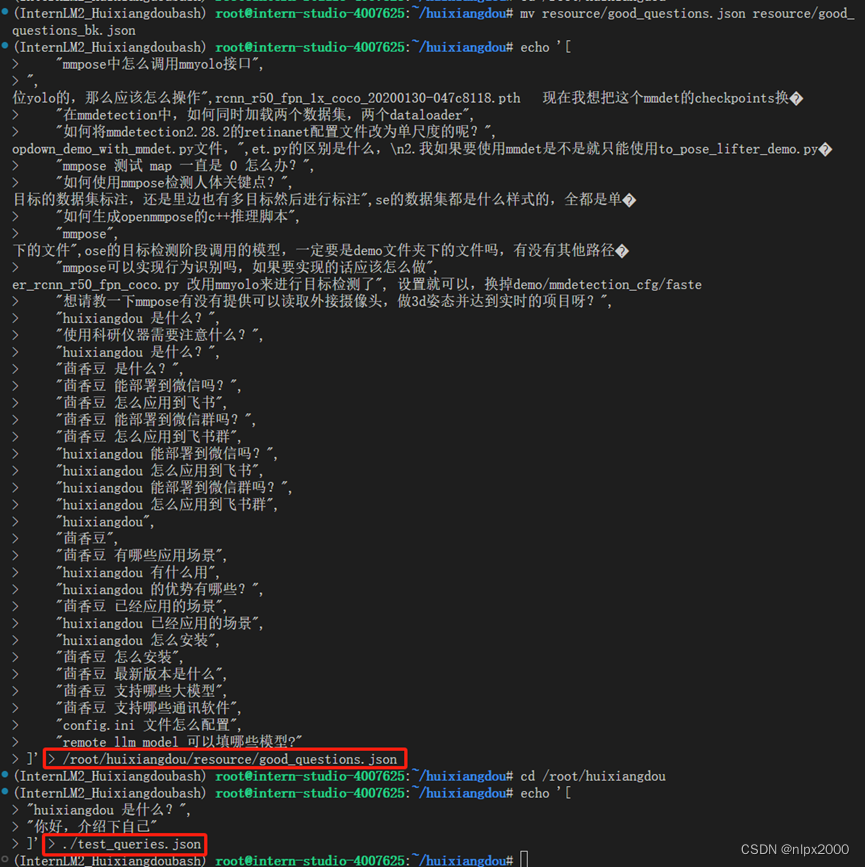
创建 RAG 检索过程中使用的向量数据库,注意检查/root/huixiangdou/resource/good_questions.json文件,文件中有行只有一个逗号或者其他字符,如:“,创建RAG 检索过程中使用的向量数据库失败提示:json.decoder.JSONDecodeError: Invalid control character at: line 3 column 3 (char 31)。
拒答流程已经生效
![]()

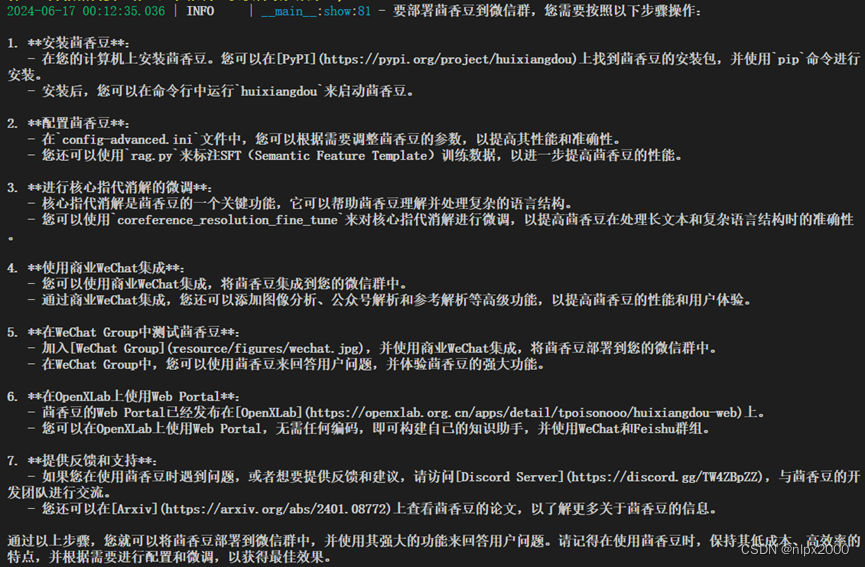
4.3运行茴香豆知识助手

第六部分:进阶作业
因环境及器材限制,本次进阶作业只集成飞书群聊,机器人集成均在飞书开放平台操作配置申请。微信有机会在进行集成。
一、茴香豆Web版飞书个人工作助手
茴香豆Web版部署不在这详述,参见基础作业:服务器部署茴香豆Web版,本节作业主要是搭建茴香豆Web版技术助手在交通安全垂直领域的回答助手,在Web版零开发集成飞书功能。
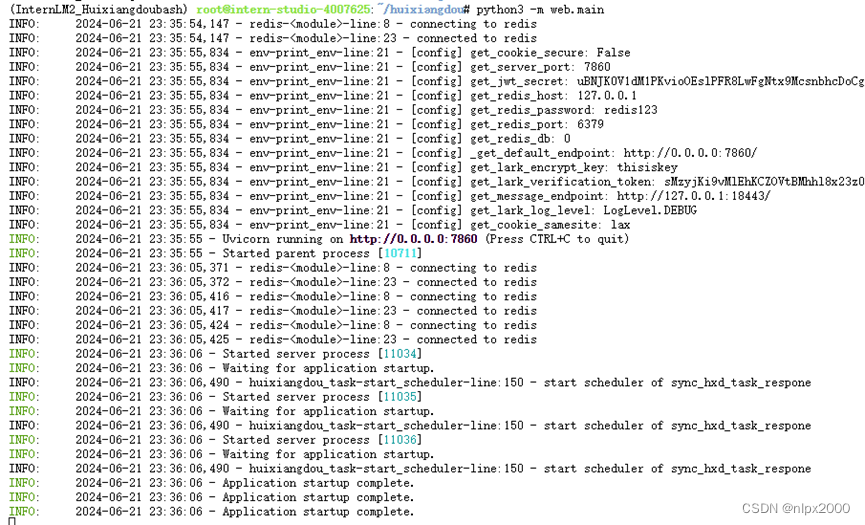
1.运行后端
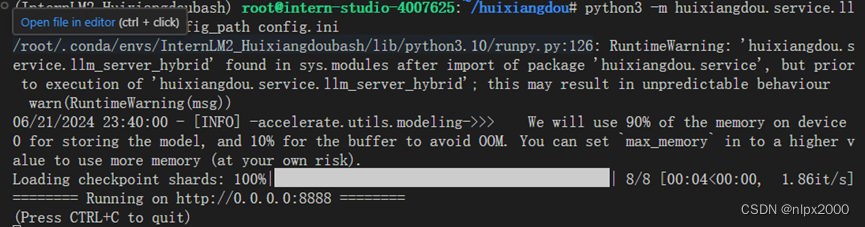
2.运行LLM hybrid proxy
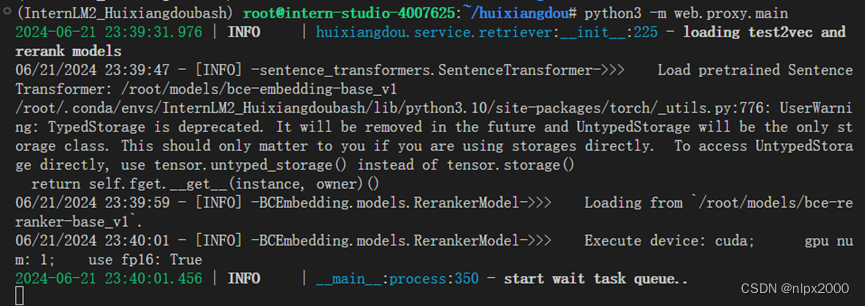
3.运行监听服务
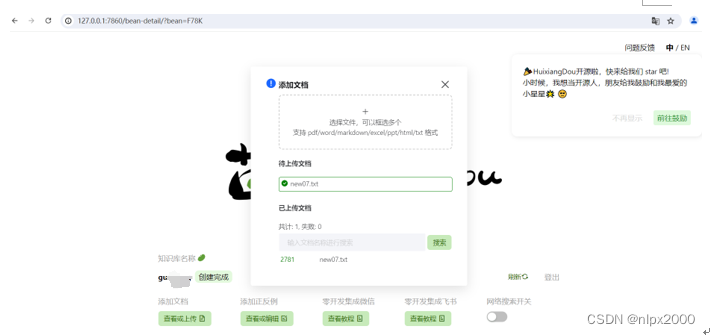
4.登录茴香豆Web版并上传文档
5.配置飞书
飞书添加应用能力

茴香豆集成飞书添加飞书应用能力凭证

飞书事件与回调填写加密策略,加密信息在茴香豆Web版点击集成飞书按钮查看
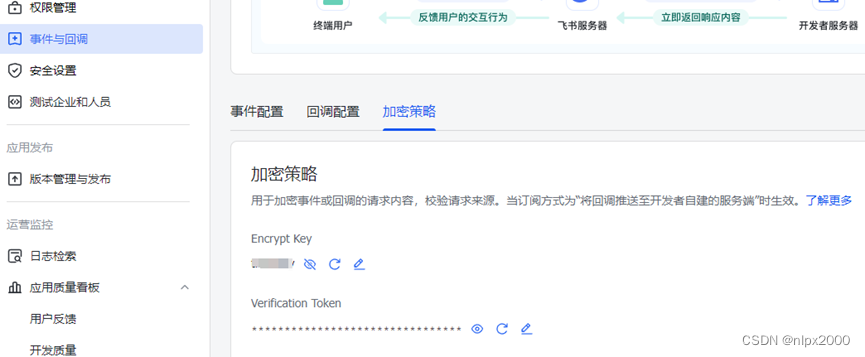
其余步骤设置参见在线茴香豆Web版飞书个人工作助手部分作业,两者区别在凭证、回调地址、Suffix不一样,回调地址需要设置为公网地址,并且映射代理内部地址端口,在系统.bashrc中添加export HUIXIANGDOU_MESSAGE_ENDPOINT=http://xxx.xxx.xxx.xxx:port环境变量,飞书配置茴香豆回调地址事件时会校验该回调地址有效性。其余操作步骤基本一样。
二、在线茴香豆Web版飞书个人工作助手
1.登录在线Web地址
登录自己的领域知识回答助手

2.配置飞书
飞书添加应用能力

3.茴香豆集成飞书添加飞书应用能力凭证

4.飞书事件与回调填写加密策略
加密信息在茴香豆Web版点击集成飞书按钮查看.

5.配置回调地址与添加事件
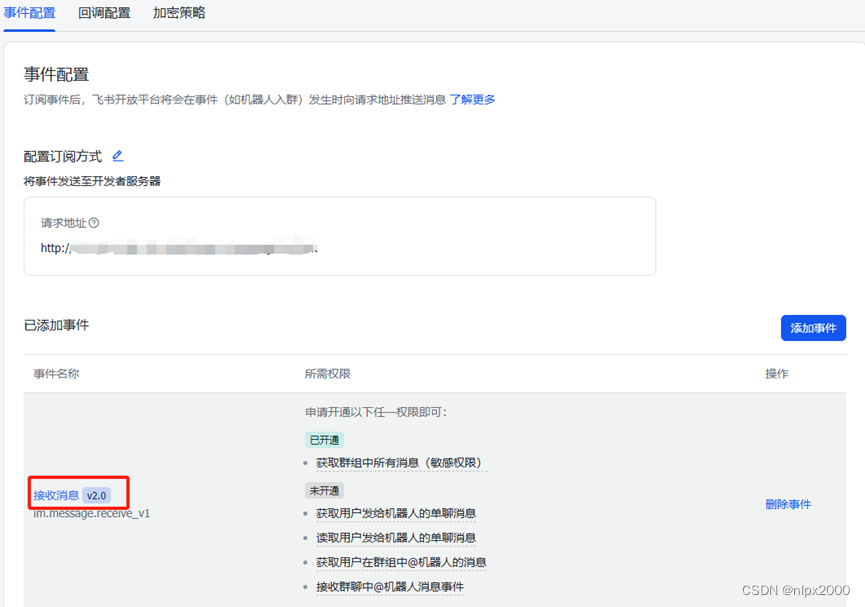
6.开通机器人权限

7.发布应用
8.飞书建群组添加机器人

9.飞书群组机器人聊天
网页版飞书
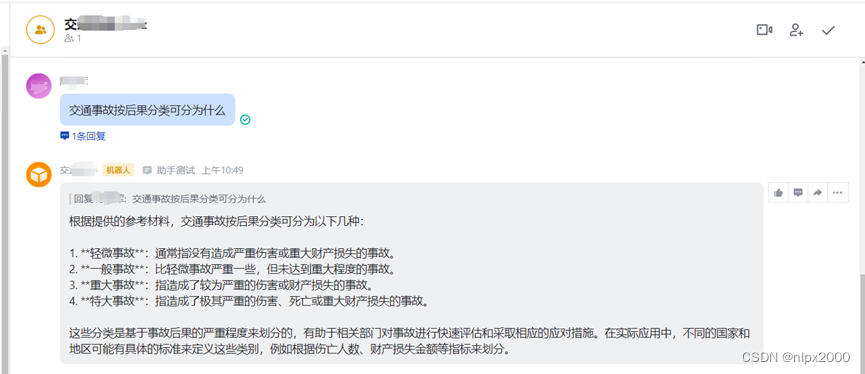
移动端聊天
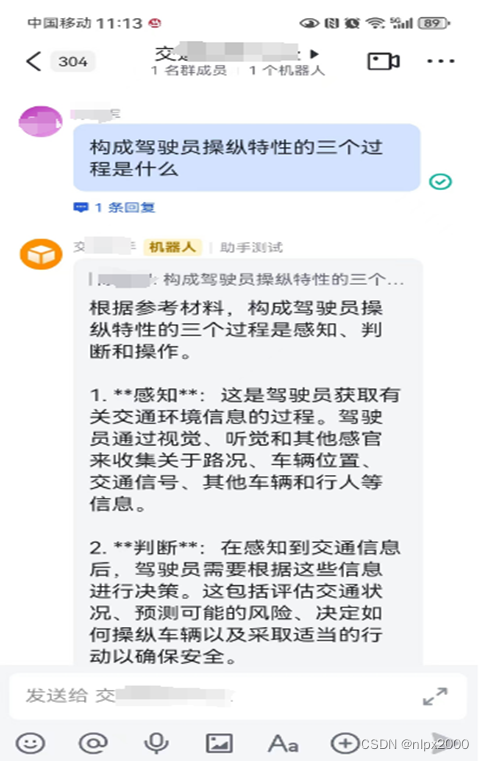
三、茴香豆进阶
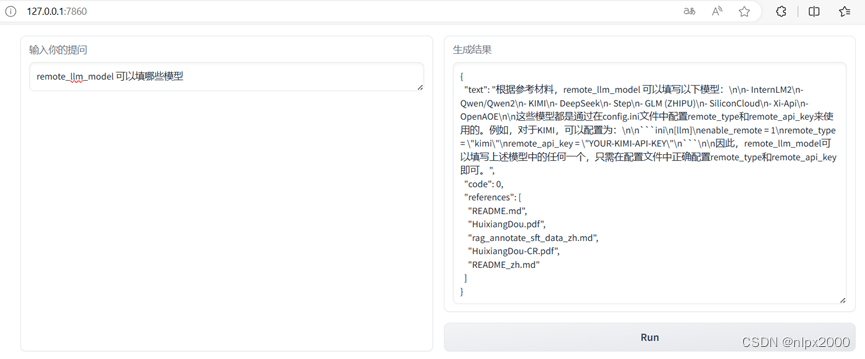
茴香豆并非单纯的 RAG 功能实现,而是一个专门针对群聊优化的知识助手,茴香豆除了可以从本地向量数据库中检索内容进行回答,也可以加入网络的搜索结果,生成回答。除了可以使用本地大模型,还可以轻松的调用云端模型 API。目前,茴香豆已经支持 Kimi,GPT-4,Deepseek 和 GLM 等常见大模型API,因本人网络原因不能配置网络搜索,下面简单介绍使用远程模型、利用Gradio搭建网页Demo。本次进阶作业不包含配置文件调整调整 Prompt,修改 good_questions.json文件,应用其他 NLP 技术提高个人工作助手的表现,有时间另发该方法。

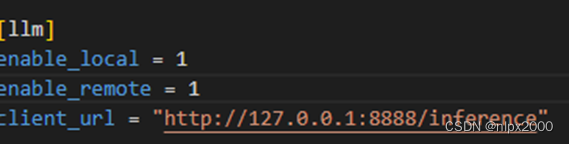
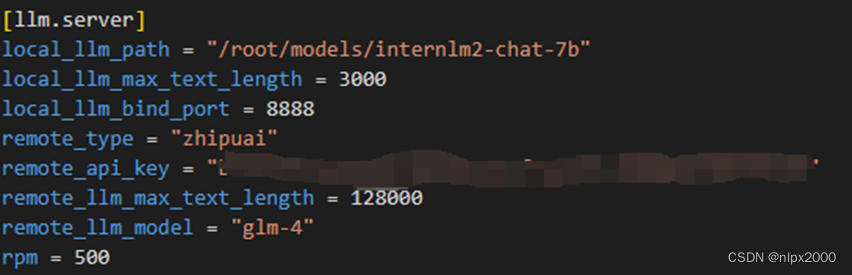
1.修改配置文件
同时开启 local 和remote 模型,或者只使用远端模型,茴香豆将采用混合模型的方法,使用api远程调用GLM模型。填写GLM调用API key、模型类型等参数。
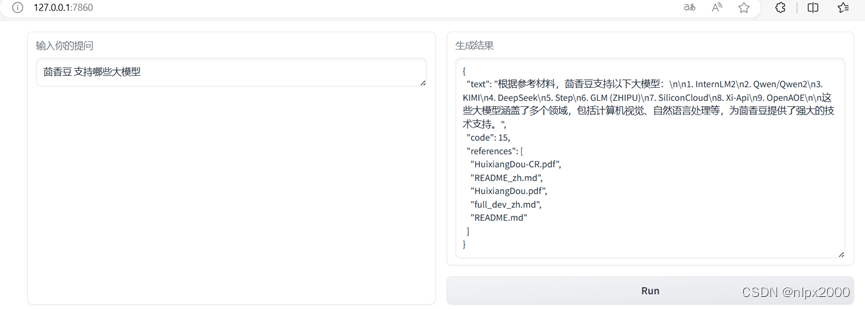
2.安装Gradio,运行脚本

2.网页demo对话
















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









