







 本文记录了一位开发者如何使用Java代码从阿里云OSS下载并解压大日志文件,然后进行搜索关键字的全过程。首先,通过OSS工具类下载并解压bz2压缩文件,然后使用LinkedList代替ArrayList以减少内存开销,最后改进为逐行读取文件进行关键字匹配,避免内存溢出。整个过程从繁琐的手动操作进化到完全自动化,提高了效率。
本文记录了一位开发者如何使用Java代码从阿里云OSS下载并解压大日志文件,然后进行搜索关键字的全过程。首先,通过OSS工具类下载并解压bz2压缩文件,然后使用LinkedList代替ArrayList以减少内存开销,最后改进为逐行读取文件进行关键字匹配,避免内存溢出。整个过程从繁琐的手动操作进化到完全自动化,提高了效率。
今天在公司遇到了一个问题,需要找一条MQ消息的日志记录,遇到了一些问题,所以把解决问题的思路记下来,分享给大家
中间用到了
- 阿里OSS
- bz2解压
- JavaIO流
- Java集合数组
1.0版,下载,解压,运行测试类完成搜索日志任务
思路;
需求是找一条日志,一条3个月之前的日志,Kibana查找日志设置的最长是2个月,服务器上有10天的日志,超过日期的,备份到阿里云的OSS上。由于生产上有4台MQ服务器,需要下载4次到本机。
- 第一步从OSS上把指定天的日志下载下来,文件是后缀bz2的压缩文件
- 将用360软件将压缩文件解压缩
- 使用notepad++打开日志,(⊙﹏⊙),notepad++居然打不开,看了下日志文件有500多mb
- 考虑用代码,每次读取一行,正好之前写了一个工具类,可以把文件的每行读到List数组内,然后在遍历数组,匹配关键字
代码如下:
IOUtil工具类
package com.guohua.yunwei.util;
import org.springframework.core.io.ClassPathResource;
import java.io.*;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class IOUtil {
public static List<String> readByLine(String path) throws IOException {
return IOUtil.readByLine(new File(path));
}
public static List<String> readByLine(File file) throws IOException {
List<String> list = new ArrayList<>();
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
String str = "";
fis = new FileInputStream(file);
isr = new InputStreamReader(fis,"UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
list.add(str.trim());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
br.close();
isr.close();
fis.close();
}
return list;
}
public static List<String> readByLine(InputStream fis) throws IOException {
List<String> list = new ArrayList<>();
InputStreamReader isr = null;
BufferedReader br = null;
try {
String str = "";
isr = new InputStreamReader(fis,"UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
list.add(str.trim());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
br.close();
isr.close();
fis.close();
}
return list;
}
/**
* 读取项目内Resources文件夹下的文件
* @param path
* @return
* @throws IOException
*/
public static String readByResources(String path) throws IOException {
ClassPathResource classPathResource = new ClassPathResource(path);
StringBuffer sb = new StringBuffer();
InputStream is=null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
String str = "";
is = classPathResource.getInputStream();
isr = new InputStreamReader(is);
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
sb.append(str);
sb.append("\r\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
br.close();
isr.close();
is.close();
}
return sb.toString();
}
public static String writer(String path, String str) throws IOException {
FileOutputStream fos = null;
OutputStreamWriter osw = null;
BufferedWriter bw = null;
try {
fos = new FileOutputStream(path,true);
osw = new OutputStreamWriter(fos);
bw = new BufferedWriter(osw);
bw.write(str);
} catch (Exception e) {
e.printStackTrace();
return path + "写入失败";
} finally {
bw.close();
osw.close();
fos.close();
}
return path + "写入成功!";
}
public static String writer(String path, List<String> list) throws IOException {
FileOutputStream fos = null;
OutputStreamWriter osw = null;
BufferedWriter bw = null;
try {
fos = new FileOutputStream(path);
osw = new OutputStreamWriter(fos);
bw = new BufferedWriter(osw);
for (String str : list) {
bw.write(str);
//换行
bw.newLine();
}
bw.flush();
} catch (Exception e) {
e.printStackTrace();
return path + "写入失败";
} finally {
bw.close();
osw.close();
fos.close();
}
return path + "写入成功!";
}
}
测试类代码
package com.guohua.yunwei;
import com.guohua.yunwei.util.IOUtil;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import java.io.*;
import java.util.List;
/**
* @author yuanfeng_lhyd
* @date 2021/8/9 18:16
*/
public class logSerchTest {
@Before
public void before(){
System.out.println("开始测试了============================");
}
@After
public void after(){
System.out.println("测试跑完了============================");
}
@Test
public void test()throws Exception{
/**
压缩包提前从oss上下载并解压,把文件读取到Java的list数组当中,list的每个元素就是日志的一行
然后进行每行关键字匹配,匹配到了,打印控制台输出,并跳出循环
*/
String path="D:/log/wls.log.20210413";
List<String> list = IOUtil.readByLine(path);
for (int i = 0; i < list.size(); i++) {
System.out.println(i);
if(list.get(i).contains("topic=gh_ebiz_claim_mq_claimInfo")&&
list.get(i).contains("claimNode\":\"14")&&
list.get(i).contains("882890206759XXXX")){
System.out.println(list.get(i));
break;
}
}
}
}
问题:由于需要从oss上下载,然后解压,跑测试类,重复进行,感觉超级繁琐,看下能否填写一个oss地址,程序自动下载解压,查询?答案应该是可以,我们先分析下步骤。
2.0版,超进化,只跑测试类,就可以完成搜索日志任务
步骤:
- 第一步,当然是用Java代码从OSS上把日志下载下来,正好有写好的OSS工具类
- 第二步,解压下载的bz2文件,这个要写,等会要百度下
- 第三步接1.0,读文件到List数组,然后遍历每一行
bz2全称为BZIP2,搜了下,需要org.apache.commons.compress类进行解析,用这个类名进行百度,可以知道,这个类属于Apache Commons Compress项目,可以从官网下在jar包
我使用的是maven的方式,真香,哈哈
打开https://mvnrepository.com/,maven仓库,查询Apache Commons Compress项目
点进去,我选的是最新版,1.2.1,可以看到Maven坐标如下
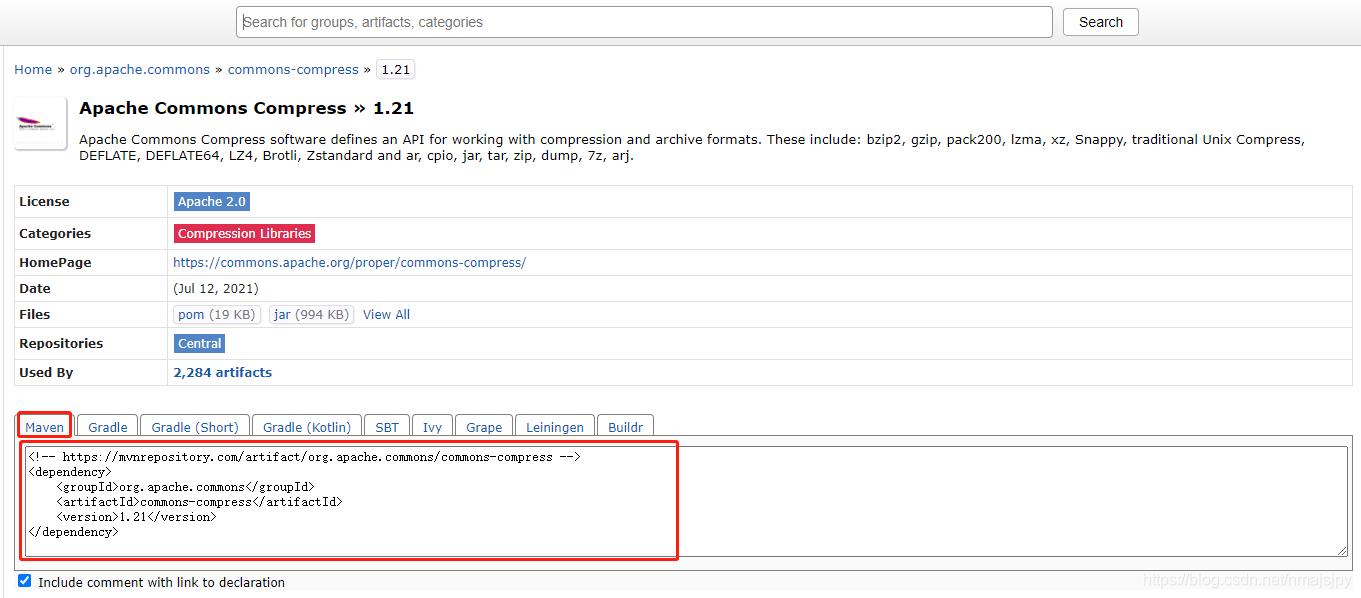
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
直接加到项目中的pom.xml文件中
项目中的介绍
Apache Commons Compress software defines an API for working with compression and archive formats.
These include: bzip2, gzip, pack200, lzma, xz, Snappy, traditional Unix Compress, DEFLATE,
DEFLATE64, LZ4, Brotli, Zstandard and ar, cpio, jar, tar, zip, dump, 7z, arj.
百度翻译了下,这包看起来功能贼强大
Apache Commons Compress软件定义了一个用于处理压缩和归档格式的API。这些包括:bzip2、gzip、pack200、
lzma、xz、Snappy、传统Unix压缩、DEFLATE、DEFLATE64、LZ4、Brotli、Zstandard和ar、cpio、jar、tar、zip、
dump、7z、arj。
我们只用到了一行代码,bz2解压关键代码:
//bis是一个InputStream流
BZip2CompressorInputStream bzip2IS = new BZip2CompressorInputStream(bis);
连接阿里OSS的sdk包,也是maven坐标
<!-- 阿里oss -->
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>2.6.0</version>
</dependency>
下面是OSS工具类:
真正的登录信息隐藏掉了,哈哈
package com.guohua.yunwei.util;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import com.aliyun.oss.ClientConfiguration;
import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSSClient;
import com.aliyun.oss.OSSException;
import com.aliyun.oss.common.utils.BinaryUtil;
import com.aliyun.oss.model.DownloadFileRequest;
import com.aliyun.oss.model.ListObjectsRequest;
import com.aliyun.oss.model.OSSObject;
import com.aliyun.oss.model.OSSObjectSummary;
import com.aliyun.oss.model.ObjectListing;
import com.aliyun.oss.model.ObjectMetadata;
import com.aliyun.oss.model.PutObjectResult;
import com.guohua.yunwei.config.FileConfig;
@Component
public class OssFileClient {
private Logger logger = LoggerFactory.getLogger(getClass());
private OSSClient ossClient;
public OssFileClient () {
FileConfig config = new FileConfig();
//OSS地址
config.setServerAddress("http://xx.xx.xx.xx/oss");
//用户ID
config.setAccessKeyId("userIDxxx");
//密码
config.setSecretAccessKey("passwordXXX");
config.setClientType("oss");
ClientConfiguration conf = new ClientConfiguration();
conf.setIdleConnectionTime(config.getIdleConnectionTime());
conf.setConnectionTimeout(config.getConnectionTimeout());
conf.setConnectionRequestTimeout(config.getConnectionRequestTimeout());
conf.setRequestTimeout(config.getRequestTimeout());
ossClient = new OSSClient(config.getServerAddress(), config.getAccessKeyId(), config.getSecretAccessKey(), conf);
logger.info("ossClient---" + config.getServerAddress() + "连接成功!...");
}
public boolean uploadFile(byte[] data, String fileSpace,
String targetFilePath) {
// 上传参数
ObjectMetadata meta = new ObjectMetadata();
// 设置上传文件长度
meta.setContentLength(data.length);
// 设置上传MD5校验
String md5 = BinaryUtil.toBase64String(BinaryUtil.calculateMd5(data));
meta.setContentMD5(md5);
// 设置上传内容类型
InputStream is = new ByteArrayInputStream(data);
try {
PutObjectResult res = ossClient.putObject(fileSpace, targetFilePath, is, meta);
System.out.println("update successful! ETag:" + res.getETag());
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message: " + oe.getErrorCode());
System.out.println("Error Code: " + oe.getErrorCode());
System.out.println("Request ID: " + oe.getRequestId());
System.out.println("Host ID: " + oe.getHostId());
return false;
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message: " + ce.getMessage());
return false;
}
return true;
}
public boolean downloadFile(String fileSpace, String filePath,
String downloadFilePath) {
try {
DownloadFileRequest downloadFileRequest = new DownloadFileRequest(fileSpace, filePath);
// Sets the local file to download to
downloadFileRequest.setDownloadFile(downloadFilePath);
// Sets the concurrent task thread count 5. By default it's 1.
downloadFileRequest.setTaskNum(5);
// Sets the part size, by default it's 100K.
downloadFileRequest.setPartSize(1024 * 1024 * 1);
// Enable checkpoint. By default it's false.
downloadFileRequest.setEnableCheckpoint(true);
ossClient.downloadFile(downloadFileRequest);
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message: " + oe.getErrorCode());
System.out.println("Error Code: " + oe.getErrorCode());
System.out.println("Request ID: " + oe.getRequestId());
System.out.println("Host ID: " + oe.getHostId());
return false;
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message: " + ce.getMessage());
} catch (Throwable e) {
e.printStackTrace();
return false;
}
return true;
}
public byte[] getFileByte(String fileSpace, String filePath) {
try{
OSSObject ossObject = ossClient.getObject(fileSpace, filePath);
InputStream is = ossObject.getObjectContent();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buf = new byte[1024];
int len = -1;
while ((len = is.read(buf)) != -1) {
baos.write(buf, 0, len);
}
return baos.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public List<String> getFileList(String fileSpace, String folderPath) {
List<String> fileList = new ArrayList<String>();
ObjectListing objectListing = null;
List<OSSObjectSummary> sums = null;
String nextMarker = folderPath;
do {
objectListing = ossClient.listObjects(new ListObjectsRequest(
fileSpace).withMarker(nextMarker).withMaxKeys(
50));
sums = objectListing.getObjectSummaries();
for (OSSObjectSummary s : sums) {
if (!s.getKey().startsWith(folderPath)) {
return fileList;
} else {
fileList.add(s.getKey());
}
}
nextMarker = objectListing.getNextMarker();
} while (objectListing.isTruncated());
return fileList;
}
public boolean existFile(String fileSpace, String filePath) {
return ossClient.doesObjectExist(fileSpace, filePath);
}
public void shutdown() {
if (ossClient != null) {
ossClient.shutdown();
}
logger.info("file client is already shutdown");
}
}
看到OSS工具类中有直接将文件读取成流的方法,看到这个方法,我有一个大胆的想法。嘿嘿嘿
oss工具类可以将oss上的文件以bety[]数组的形式读取,结果可以是一个bety数组输入流,然后这个比特数组输入流,可以传给BZIP2工具解压,返回值是bz2的解压输入流,这个IO工具里面,方法参数有一个以输入流的方式的入参,大家都是InputStream,很好很强大,都串起来了,根本不用下载文件到本地,代码又省了好多步骤。妙啊!!!
代码实现如下:
package com.guohua.yunwei;
import com.guohua.yunwei.util.IOUtil;
import com.guohua.yunwei.util.OssFileClient;
import org.apache.commons.compress.compressors.bzip2.BZip2CompressorInputStream;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.test.context.web.WebAppConfiguration;
import java.io.*;
import java.util.List;
/**
* @author yuanfeng_lhyd
* @date 2021/8/9 18:16
*/
@RunWith(SpringRunner.class)
@SpringBootTest
@WebAppConfiguration
public class logSerchTest {
@Autowired
public OssFileClient ossFileClient;
@Before
public void before(){
System.out.println("开始测试了============================");
}
@After
public void after(){
System.out.println("测试跑完了============================");
}
@Test
public void test()throws Exception{
//oss上的路径
String filePath="serverLog/third/XX.XXX.X.XXX/2021/202104/wls.log.20210413.bz2";
InputStream bis=new ByteArrayInputStream(ossFileClient.getFileByte("hd2-server-log", filePath));
System.out.println("开始解压=====================");
BZip2CompressorInputStream bZip2IS = new BZip2CompressorInputStream(bis);
System.out.println("开始查询");
List<String> list = IOUtil.readByLine(bZip2IS);
for (int i = 0; i < list.size(); i++) {
System.out.println(i);
if(list.get(i).contains("topic=gh_ebiz_claim_mq_claimInfo")&&
list.get(i).contains("claimNode\":\"14")&&
list.get(i).contains("882890206759XXXX")){
System.out.println(list.get(i));
break;
}
}
bZip2IS.close();
bis.close();
}
}
然而,想像很美好,结果很残酷,运行测试类,运行了一会,直接内存溢出了。
不信邪,调大JVM虚拟机内存,再次启动运行,继续爆炸,继续加,继续爆炸。。。。。。
开始分析,为啥会内存溢出,看是再次回顾代码
点开IOUtil工具类,看到读取文件到List中的List是ArrayList
会不会是ArrayList的锅,这玩意会自动扩容,百度了下,ArrayList自动扩容
Java1.7ArrayList无参构造方法初始长度默认10,
数组内元素的个数加1,看是否等于或大于数组长度,等于或大于数组长度,处罚扩容
ArrayList在第一次插入元素add()时分配10(默认)个对象空间。假如有20个数据需要添加,那么会在第11个数据的时候(原始数组容量存满时),按照1.5倍增长;之后扩容会按照1.5倍增长(10、15、22、、、)
Java1.8

看了下文件的大小,此时,读取的文件的大小是1G左右
ArrayList的最大容量是2的31次方减1,应该是一个很大的数字
21 4748 3648-1,大概21亿行,才会爆炸。应该大概也许不是它,应为这个数太大了
但是,ArrayList的扩容机制,让他很浪费内存,我们的需求只是遍历,不是查询,用不到下标,使用
LinkedList足够了,他底层使用的是链表,增删快,查询略慢,不过无所谓,我们只遍历
IOUtil工具类修改如下:
package com.guohua.yunwei.util;
import org.springframework.core.io.ClassPathResource;
import java.io.*;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class IOUtil {
public static List<String> readByLine(String path) throws IOException {
return IOUtil.readByLine(new File(path));
}
public static List<String> readByLine(File file) throws IOException {
List<String> list = new LinkedList<>();
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
String str = "";
String str1 = "";
fis = new FileInputStream(file);
isr = new InputStreamReader(fis,"UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
list.add(str.trim());
}
System.out.println(str1);
} catch (Exception e) {
e.printStackTrace();
} finally {
br.close();
isr.close();
fis.close();
}
return list;
}
public static List<String> readByLine(InputStream fis) throws IOException {
List<String> list = new LinkedList<>();
InputStreamReader isr = null;
BufferedReader br = null;
try {
String str = "";
String str1 = "";
isr = new InputStreamReader(fis,"UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
list.add(str.trim());
}
System.out.println(str1);
} catch (Exception e) {
e.printStackTrace();
} finally {
br.close();
isr.close();
fis.close();
}
return list;
}
/**
* 读取项目内Resources文件夹下的文件
* @param path
* @return
* @throws IOException
*/
public static String readByResources(String path) throws IOException {
ClassPathResource classPathResource = new ClassPathResource(path);
StringBuffer sb = new StringBuffer();
InputStream is=null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
String str = "";
is = classPathResource.getInputStream();
isr = new InputStreamReader(is);
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
sb.append(str);
sb.append("\r\n");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
br.close();
isr.close();
is.close();
}
return sb.toString();
}
public static String writer(String path, String str) throws IOException {
FileOutputStream fos = null;
OutputStreamWriter osw = null;
BufferedWriter bw = null;
try {
fos = new FileOutputStream(path,true);
osw = new OutputStreamWriter(fos);
bw = new BufferedWriter(osw);
bw.write(str);
} catch (Exception e) {
e.printStackTrace();
return path + "写入失败";
} finally {
bw.close();
osw.close();
fos.close();
}
return path + "写入成功!";
}
public static String writer(String path, List<String> list) throws IOException {
FileOutputStream fos = null;
OutputStreamWriter osw = null;
BufferedWriter bw = null;
try {
fos = new FileOutputStream(path);
osw = new OutputStreamWriter(fos);
bw = new BufferedWriter(osw);
for (String str : list) {
bw.write(str);
bw.newLine();//换行
}
bw.flush();
} catch (Exception e) {
e.printStackTrace();
return path + "写入失败";
} finally {
bw.close();
osw.close();
fos.close();
}
return path + "写入成功!";
}
}
优化了一个点,再跑下试试,依旧还是内存溢出,继续爆炸。。。。。。
继续分析,我是需要每行对比关键字,我为什么要把文件读到List数组中在进行每行的关键字对比,这不相当于我把整个文件都读到内存中了,不爆炸才怪。我真傻,真的
3.0版,究极进化,文件每次只读取一行进行关键字匹配
代码如下:
package com.guohua.yunwei;
import com.guohua.yunwei.util.IOUtil;
import com.guohua.yunwei.util.OssFileClient;
import org.apache.commons.compress.compressors.bzip2.BZip2CompressorInputStream;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.test.context.web.WebAppConfiguration;
import java.io.*;
import java.util.List;
import java.util.Scanner;
/**
* @author yuanfeng_lhyd
* @date 2021/8/9 18:16
*/
@RunWith(SpringRunner.class)
@SpringBootTest
@WebAppConfiguration
public class logSerchTest {
@Autowired
public OssFileClient ossFileClient;
@Before
public void before(){
System.out.println("开始测试了============================");
}
@After
public void after(){
System.out.println("测试跑完了============================");
}
@Test
public void test()throws Exception{
String filePath="serverLog/third/XX.XXX.X.XXX/2021/202104/wls.log.20210413.bz2";
InputStream bis=new ByteArrayInputStream(ossFileClient.getFileByte("hd2-server-log", filePath));
System.out.println("开始解压=====================");
BZip2CompressorInputStream bZip2IS = new BZip2CompressorInputStream(bis);
System.out.println("开始查询");
String line="";
Scanner sc=new Scanner(bZip2IS,"UTF-8");
while (sc.hasNextLine()){
line=sc.nextLine();
System.out.println("查找中...");
if(line.contains("topic=gh_ebiz_claim_mq_claimInfo")&&
line.contains("claimNode\":\"14")&&
line.contains("882890206759XXXX")){
System.out.println(line);
break;
}
}
bZip2IS.close();
bis.close();
}
}
到此,顺利解决了内存溢出的问题,一次读取一行进项匹配,实现方法也可以用IOUtil类中的BufferedReader类的方法readLine()方法实现,这个是用Scanner 类实现的,是不是很眼熟这个类
没错,就是刚开始学习Java的时候用到的那个类。
总结体会
- 如果只是遍历,可以使用LinkedList代替ArrayList,减少内存开销
- 内存就是比硬盘速度快,SSD都不行,测试了下和1.0版本方法做对比,1.0版本的大部分时间浪费到了下载和解压,再读取的步骤,通过3.0版本代码的运行时的对比,可以看到,解压的速度也很快,大部分时间是把数据从内存写道硬盘上。
- 我之前错怪CUP了,解压文件原来以为是cpu不给力,结果硬盘的IO才是瓶颈。
- 所以编程要减少IO的消耗,真是太对了,可以减少程序的运行时间,提高程序的反应速度。
- 读取大型文件时,采用一行一行读的办法,不要采用整个文件一下读到内存的方法,妈妈再也不用怕我读文件内存溢出了

















 3546
3546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









