






二维卷积神经网络的工作方式
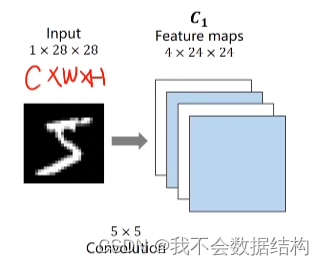
输入的图像是1×28×28的张量,三个分量分别为C,H,W(通道,宽度,高度)

经过一个卷积层,要保留该图像的空间特征(这里通过卷积把这个图片变成4×24×24的)这里先别管是怎么卷的,下面会说。经过卷积的图像之后,通道,大小都变化了
接着做一个2×2的下采样
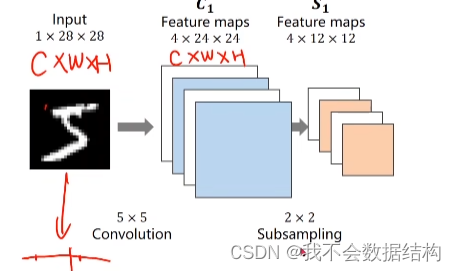
这里Feature maps又变化了,变成4×12×12
注意到使用下采样,通道数不变,图像宽,高不变
使用下采样的目的是减少数据量
我们的目的是要通过一系列的维度和大小上的变化,把1×28×28的这样一个张量转化成10×1的一个向量,想要达到这个目的,就需要做多次的卷积和下采样
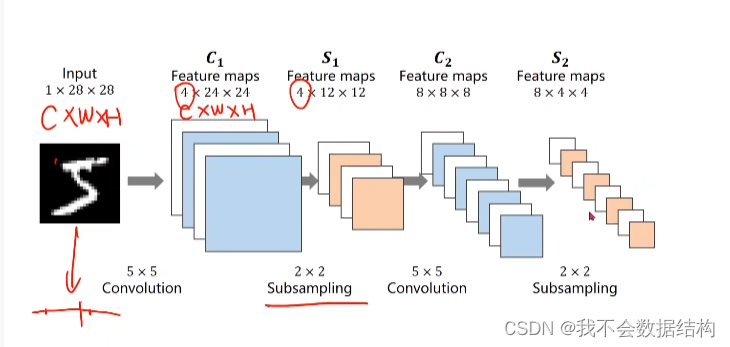
最后,我们想要把这个8×4×4的一个张量变成一个一维的向量
按照某种顺序把8×4×4的一个张量变成了最右侧的那个东西
接下来再使用一个全连接层 ,把绿色的那一堆向量变换成我们想要的形状
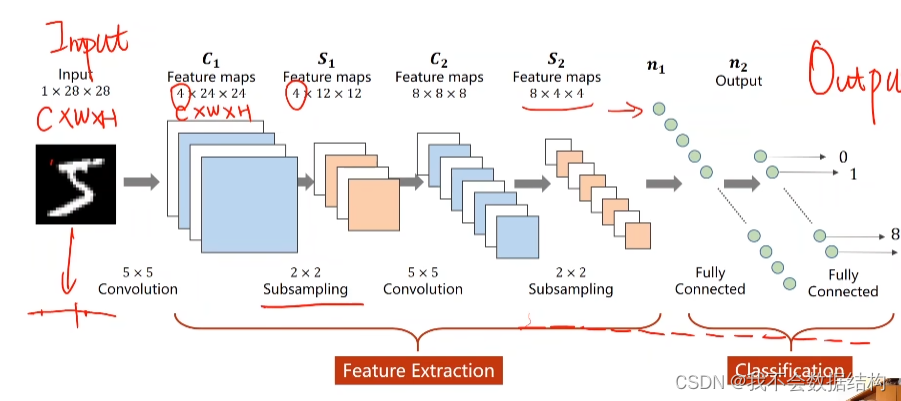
前面的卷积和下采样称为特征提取器
通过卷积运算,来提取某种特征
后面的那些称为分类器
卷积是怎么工作的
图像有红绿蓝三个通道(R,G,B)
输入图像的RGB称为Input Channel
W,H为宽度和高度
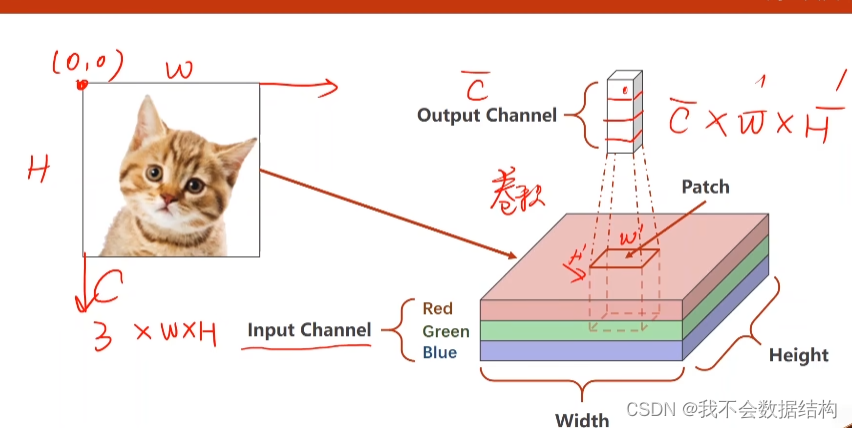
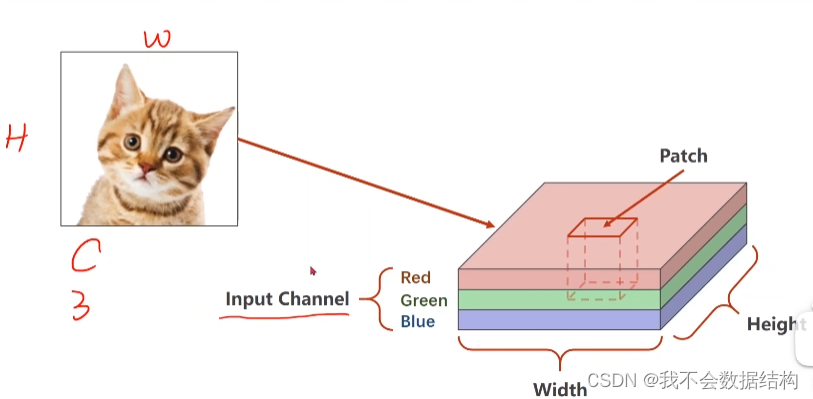 在进行卷积之前,会取Patch这样的一个小块,每一个通道会取w‘,h’,所以Patch为3×w‘×h’ 的张量
在进行卷积之前,会取Patch这样的一个小块,每一个通道会取w‘,h’,所以Patch为3×w‘×h’ 的张量
然后在这个Patch上做卷积 ,在这个卷积里面,C,W,H都会变大概过程是Patch会遍历图像,然后对每一个Patch进行卷积运算,最后会的到一个输出的结果,然后把他们拼到一起
卷积的通道数称为输出通道数,每一个通道需要一个卷积核,也就是说:输入通道=卷积核的通道数
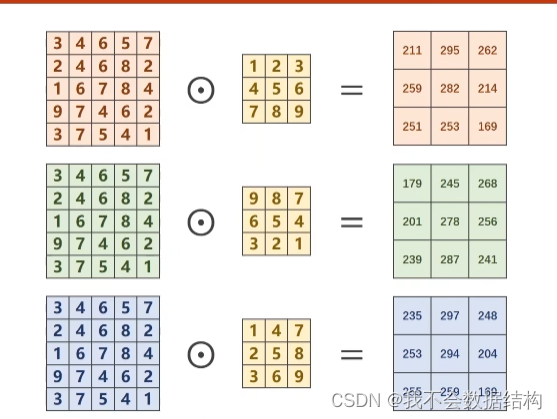
下面来说说是怎么计算的
假设坐标原点如图所示:
对R(红色层):1*3+2*4+3*6+4*2+5*4+6*6+1*7+8*6+7*9=211
其他的类似
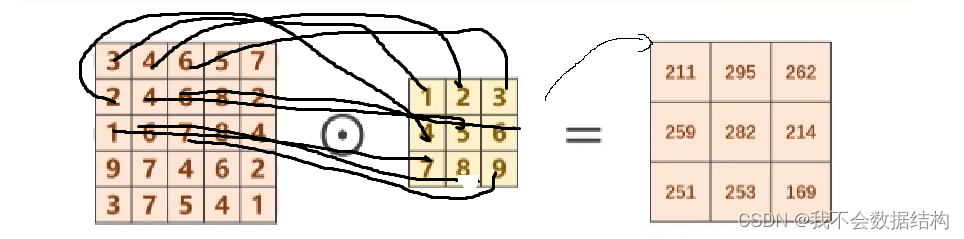
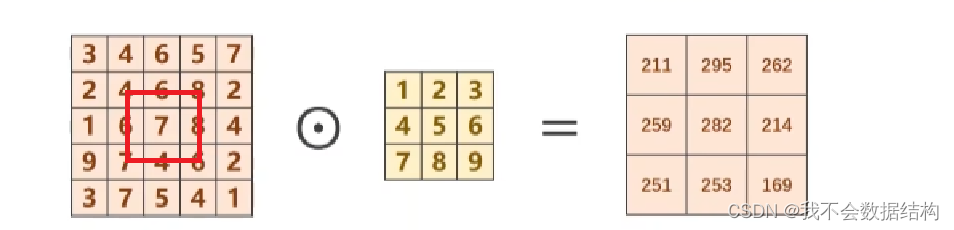
卷积核实在红色的圈里面进行遍历的,刚开始的位置是数字4,后面在遍历过程中计算得到的值
对G,B层进行同样的操作之后有类似的结果,把的到的卷积结果加起来
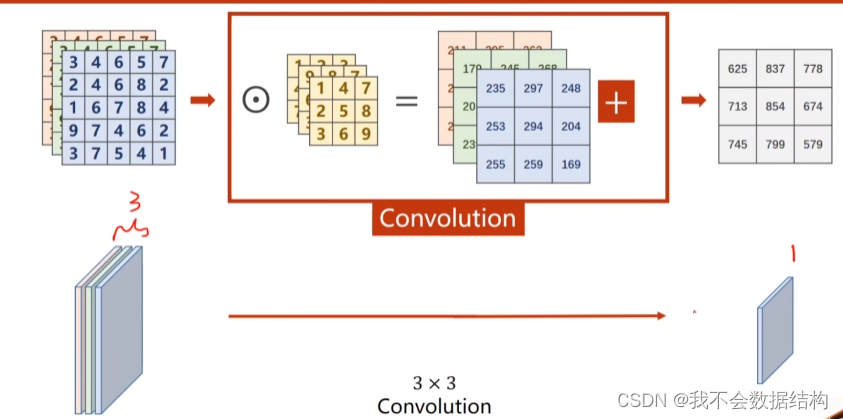
在经过了上面的卷积运算之后,得到的通道只有一个
怎么实现拼接的:

卷积核的通道数量和输入通道数量是一样的
卷积核的总数和输出通道是一样的
卷积核的大小自己定
最后把m个卷积核拼成4维的张量

下采样
下采样用的是MaxPooling的一种方式
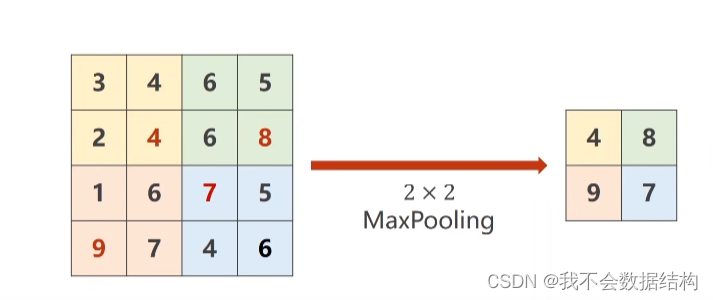
stride=2,把这个4×4的图像分成四块,找每一块的最大值,把最大值拼成新的输出
模型
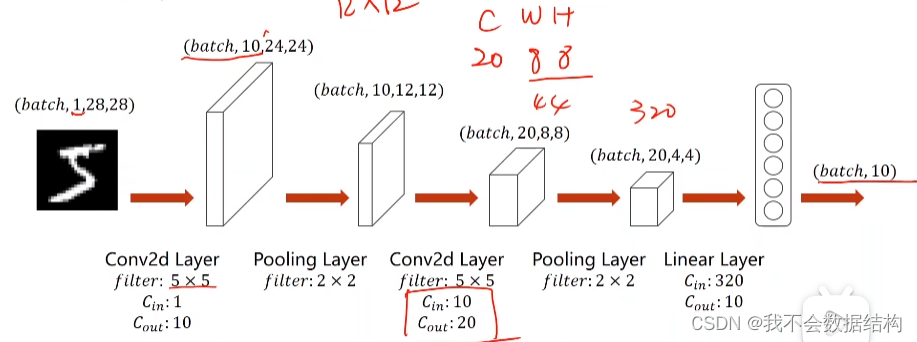
经过上面的分析,我们的模型设计成这样子,需要进行两次卷积,两次池化
代码
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
##这里别偷懒matplotlib一定要加.pyplot,要不然会报错导包
from torchvision import datasets:这里有我们要的数据集MNIST
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
上面是构建数据集的过程
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]):
这里定义了一个图像变换序列,用于数据预处理:
transforms.ToTensor(): 将PIL图像或NumPy数组转换为PyTorch张量,并且会自动将像素值从0-255的整数范围缩放到0.0-1.0的浮点数范围。
transforms.Normalize((0.1307,), (0.3081,)) ]): 对图像进行标准化。这里的参数分别是每个通道的均值和标准差。由于MNIST数据集是灰度图像(单通道),所以均值和标准差都是一个值。上面的那几个数字一般是这么算的:output[channel] = (input[channel] - mean[channel]) / std[channel],那两个数是针对MNIST已经算好的
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5): 定义第一个卷积层,输入通道数为1,输出通道数为10,卷积核大小为5x5,第二个一样。
self.pooling = torch.nn.MaxPool2d(2):定义最大池化层,池化窗口大小为2x2。
self.fc = torch.nn.Linear(320, 10): 定义全连接层,输入特征数为320,输出特征数为10。
batch_size = x.size(0):获取输入数据 x 的批次大小。
x = F.relu(self.pooling(self.conv1(x))):将输入数据 x 通过第一个卷积层 conv1,然后应用最大池化层 pooling,最后应用ReLU激活函数。
x = x.view(batch_size, -1): 将卷积层输出的特征图展平,以便输入到全连接层。-1 表示该维度的大小由PyTorch自动计算,这里计算的结果是320。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)开显卡加速
torch.cuda.is_available(): 这个函数检查CUDA(即GPU加速的PyTorch)是否可用。如果系统上安装了CUDA支持的GPU,并且PyTorch被正确配置为使用GPU,那么这个函数会返回True;否则返回False。
cuda:0: 这表示第一个可用的CUDA设备(即GPU)。在大多数系统上,如果你有一个GPU,它通常是第一个(索引为0)CUDA设备。
这行代码是如果CUDA可用(即你有GPU并且PyTorch可以访问它),则将device设置为cuda:0(即使用第一个GPU)。如果CUDA不可用(例如,你没有GPU,或者PyTorch没有被配置为使用GPU),则将device设置为cpu(即使用CPU)。
model.to(device):这行代码的作用是将model(一个PyTorch神经网络模型)移动到先前定义的device上。这确保了模型的权重和计算都在正确的设备上进行。如果device是cuda:0,那么模型会被移动到GPU上;如果device是cpu,那么模型会被移动到CPU上。
一定要把模型和数据放到同一块显卡上(谁阔的搞这么多显卡玩啊0.0)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.1,momentum=0.5)
上面是构造损失函数和迭代器
criterion = torch.nn.CrossEntropyLoss():创建了一个交叉熵损失(CrossEntropyLoss)对象,它通常用于分类任务
momentum=0.5:是一个加速SGD在相关方向上移动,并抑制振荡的参数。它可以帮助加速SGD在相关方向上的收敛,并减少收敛过程中的振荡。
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
return correct/total
上面定义了训练和损失函数,这里把他们打包成了一个函数,有助于后面代码量减少(好像监督学习经常这么干)
inputs, target = data: 从数据加载器中获取输入和标签。
inputs, target = inputs.to(device), target.to(device): 将数据和标签移动到之前定义的设备(CPU或GPU)上。
optimizer.zero_grad(): 清除之前的梯度(如果存在的话),在每次迭代开始时调用,以确保不会累积之前的梯度。
outputs = model(inputs): 前向传播,通过模型得到输出。
loss = criterion(outputs, target): 计算损失。
loss.backward(): 反向传播,计算梯度。
optimizer.step(): 根据梯度更新模型参数。
running_loss += loss.item(): 累积损失。
每300个批次打印一次当前平均损失。
torch.no_grad():确保在测试过程中不进行梯度计算
遍历 test_loader 中的每一个批次数据:
images, labels = images.to(device), labels.to(device): 将图像和标签移动到指定的设备。
outputs = model(images): 通过模型得到输出。
_, predicted = torch.max(outputs.data, dim=1): 获取预测结果,即输出中每个样本的最大概率对应的类别索引。
correct += (predicted == labels).sum().item(): 计算正确预测的数量。
准确率是通过比较预测结果和真实标签来计算的。
if __name__=='__main__':
for epoch in range(10):
train(epoch)
if epoch % 10 == 9:
test()上面是开始训练,一定要加if __name__=='__main__': 不然会报错
如果要打印准确度曲线的话:
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list,acc_list)
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()完整代码:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
# flatten data from (n,1,28,28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # -1 此处自动算出的是320
# print("x.shape",x.shape)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
return correct/total
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list,acc_list)
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()
参考文献[手动狗头]:
PyTorch 深度学习实践 第4讲; 传送门:PyTorch 深度学习实践 第4讲_.grad.data-CSDN博客
PyTorch学习(九)--用CNN模型识别手写数字数据集MNIST;传送门:PyTorch学习(九)--用CNN模型识别手写数字数据集MNIST_基于pytorch的minst手写数字识别cnn-CSDN博客
《PyTorch深度学习实践》完结合集中的P10;合订本传送门:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
强力推荐bilibili的up主刘二大人;传送门:刘二大人的个人空间-刘二大人个人主页-哔哩哔哩视频
我的一些疑惑
1.话说卷积神经网络的这个卷积和数学上的卷积有什么关系,学了这么长时间了感觉一点联系没有
2.如何给卷积核选择合适的权重?















 3276
3276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









