






数据集
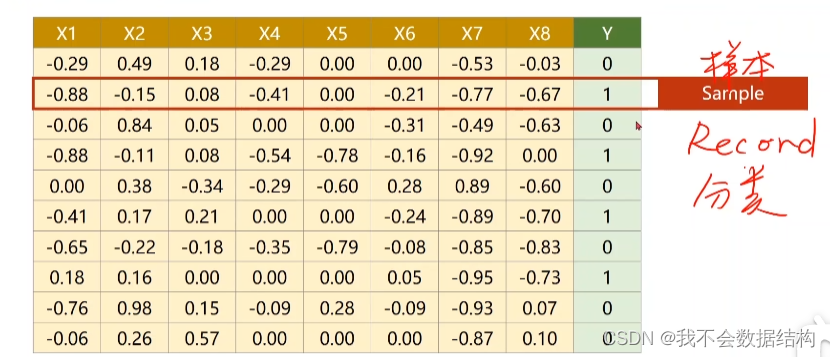
我们把数据的行称为样本,列称为特征
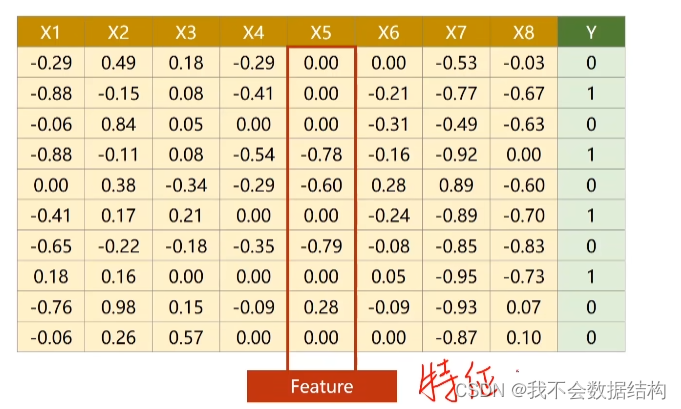
我们把这个数据集分为两个部分,输入x,输入y
x1-x8是糖尿病人的一些情况,y是一年之后会不会病情加重
模型
模型的由原来的
变成:
把里面的求和写成矩阵的形式:

总的来说最后式子长这样:

其中
我们习惯把第i个样本的计算记作
z1-zn 都要去计算
再把他们拼到一起,写成矩阵的形式

在pytorch中提供的函数都支持向量化计算
比如:
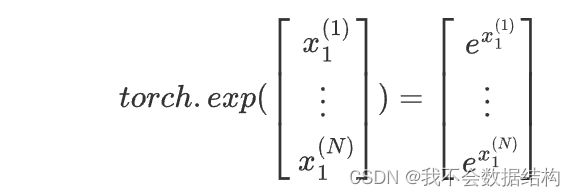
我们把z1-zn看成一个向量
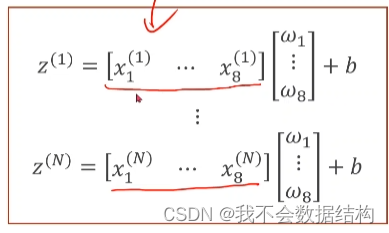
可以把他改写成两个矩阵相乘的形式

把这些数据转化成向量之后可以用硬件的并行计算能力加速计算,拿for循环计算就算了吧
考察一下数据的维度:
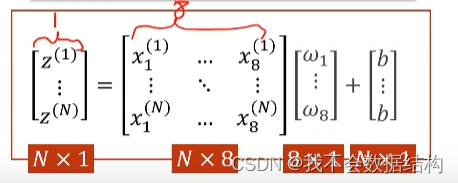
构造模型
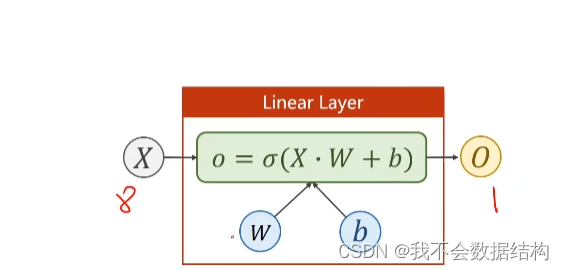
输入是8维,输出是1维的
把矩阵看成是一种线性的空间变换的函数

把一个8维的向量变换成为2维的
但是空间变换不一定是线性的,我们希望用多个线性变换曾,通过调整权重,把他们组合起来,去模拟一种非线性的空间变换
所以,这里我们是要找从8维到1维的非线性空间变换
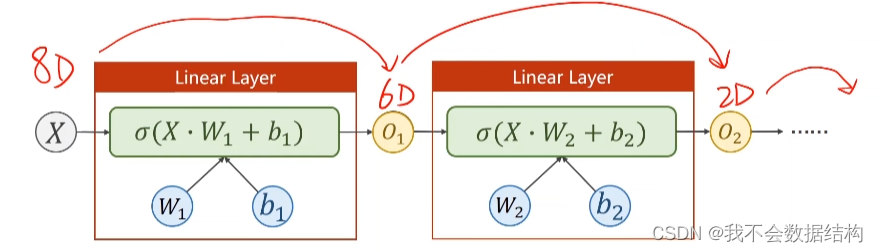
一般来说,中间的层数越多,神经元个数越多,学习能力越强,但是会把数据的噪声学习进去,我们要保留的是数据本身的一种规律
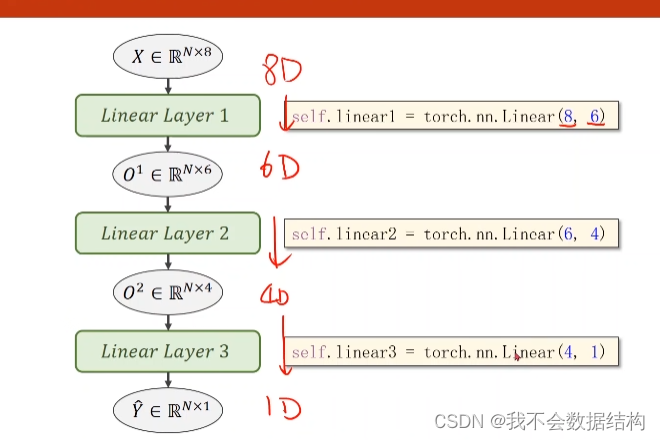
代码
构建数据集:
xy=pd.read_csv(r"C:\Users\Administrator\Desktop\diabetes.csv")
x_data=torch.from_numpy(np.array(xy.iloc[:, :-1])).float()
y_data=torch.from_numpy(np.array(xy.iloc[:,[-1]])).float()
print(x_data)
print(x_data.shape)
print(y_data)
print(y_data.shape)
这里可以打印出来看看x,y是长什么样子的
xy = pd.read_csv(r"C:\Users\Administrator\Desktop\diabetes.csv"):里面写文件路径,这里一定要在前面加r,因为可以避免在Windows路径中的反斜杠\被解释为转义字符。
np.array(...)`: 这部分将选定的DataFrame转换为NumPy数组。
torch.from_numpy(...)`: 这部分将NumPy数组转换为PyTorch张量。
.float()`: 最后,将张量数据类型转换为浮点数(通常是`torch.float32`)
pd.read_csv读入,数据类型是DataFrame,要先把DataFrame转成NumPy数组再转成PyTorch张量
x_data是选择除了最后一列的所有列
y_data是最后一列
构造模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 2)
self.linear4 = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x)) # y hat
x = self.sigmoid(self.linear4(x)) # y hat
return x
model = Model()
损失
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
训练过程
epoch_list = []
loss_list = []
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
打印损失曲线
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show(完整版:
import numpy as np
import torch
import matplotlib.pyplot as plt
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epoch_list = []
loss_list = []
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()学习感悟环节
像sigmoid,softmax这种激活函数的导数有个特点,就是他们求导可以用自身表示出来
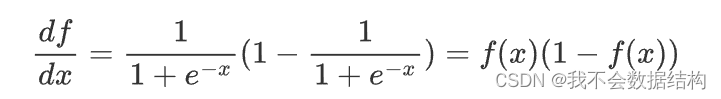
不知道这么设计有什么考虑
如果前面的隐藏层用relu激活函数最后一层用sigmoid会发生什么?(正向优化还是方向优化?)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1=torch.nn.Linear(8,6)
self.linear2=torch.nn.Linear(6,4)
self.linear3=torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
self.relu=torch.nn.ReLU()
def forward(self,x):
x=self.relu(self.linear1(x))
x=self.relu(self.linear2(x))
x=self.sigmoid(self.linear3(x))
return x
model=Model()还有一点疑问,就是如何不通过绘制曲线的方式判断模型到底是过拟合还是拟合不足???
剩下的想起来再补充
参考文献(doge):
PyTorch 深度学习实践 第7讲;传送门:PyTorch 深度学习实践 第7讲_layer_weight.shape-CSDN博客
《PyTorch深度学习实践》完结合集;传送门:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
本文使用的数据集在课程里面,需要的请移步b站课程















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









