







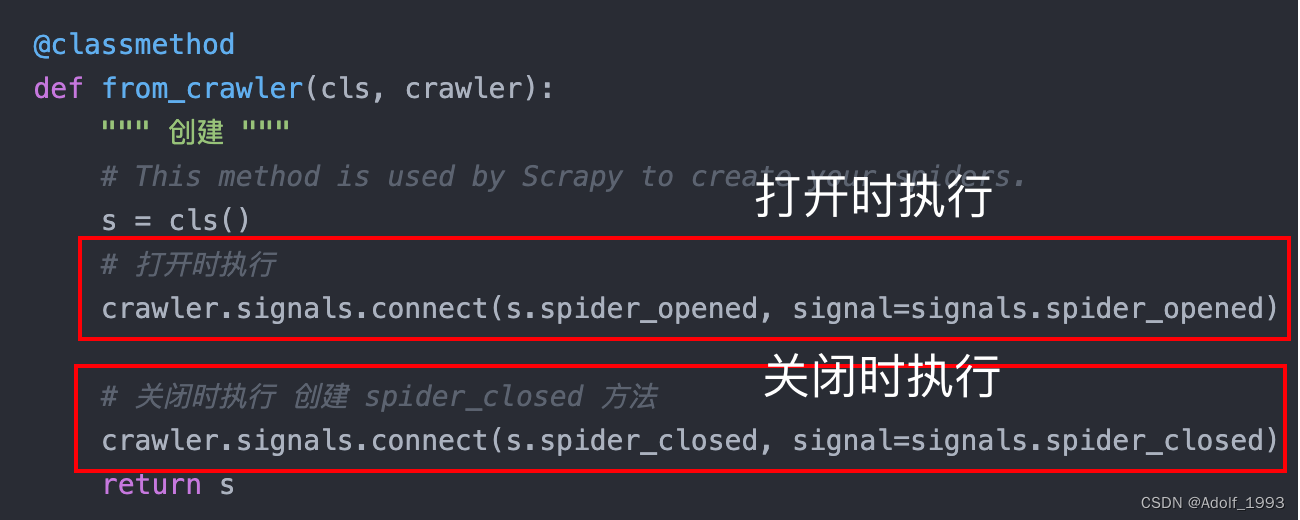
1. 在spider_opened方法中创建浏览器 在spider_closed方法中关闭浏览器
# middlewares.py
class BossproDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
""" 创建 """
# This method is used by Scrapy to create your spiders.
s = cls()
# 打开时执行
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
# 关闭时执行 创建 spider_closed 方法
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s
def process_request(self, request, spider):
""" 处理请求 """
if "zhipin" in request.url:
# 发起请求
self.web.get(request.url)
# 随机延迟时间
time.sleep(random.randint(1, 10))
# 获取源码
page_source = self.web.page_source
# 返回 HtmlResponse对象
return HtmlResponse( # 封装HtmlResponse对象
url=request.url,
body=page_source,
request=request,
encoding="utf-8"
)
else:
return None
def process_response(self, request, response, spider):
""" 处理返回 """
return response
def process_exception(self, request, exception, spider):
""" 处理异常 """
pass
def spider_opened(self, spider):
""" 爬虫打开 """
options = ChromeOptions()
# options.add_argument('--headless') # 启用无头浏览器
options.add_argument('--disable-gpu')
options.add_experimental_option('detach', True) # 不自动关闭浏览
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 浏览器驱动
ser = Service(executable_path='/Users/adolf/Downloads/chromedriver-mac-x64/chromedriver')
# 创建浏览器对象
self.web = Chrome(options=options, service=ser)
def spider_closed(self, spider):
""" 爬虫关闭 """
time.sleep(3)
self.web.quit()



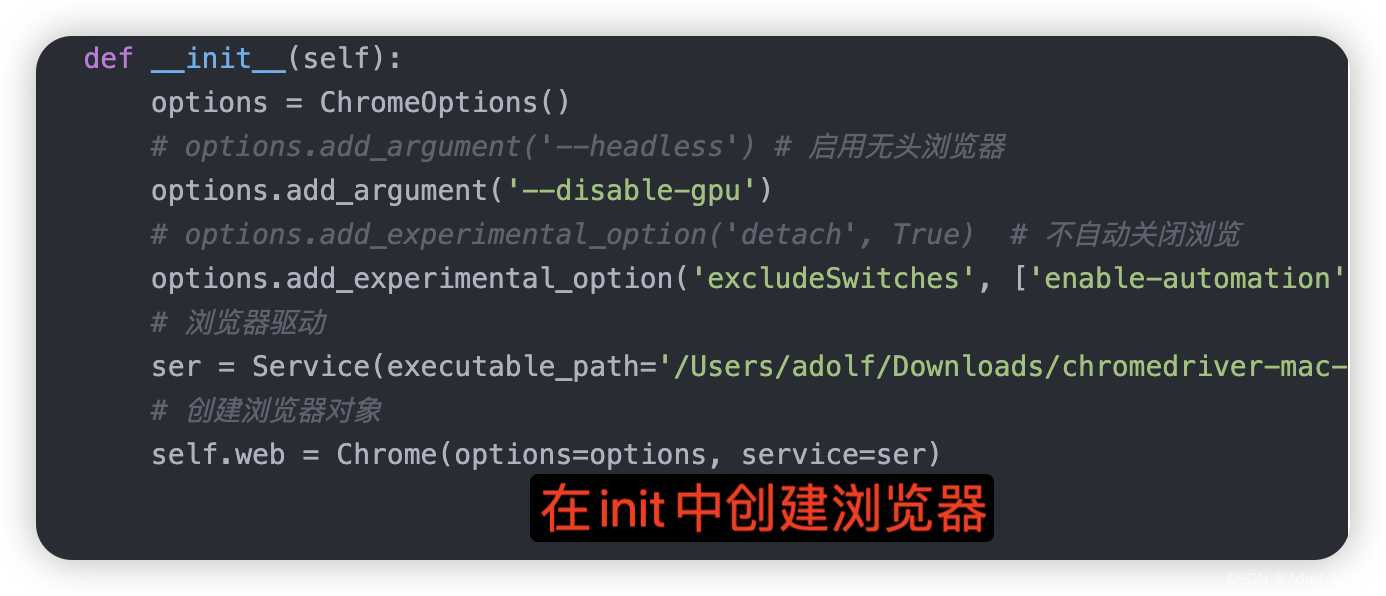
2. 在__init__ 方法中创建浏览器 在spider_closed方法中关闭浏览器
# middlewares.py
class BossproDownloaderMiddleware:
def __init__(self):
options = ChromeOptions()
# options.add_argument('--headless') # 启用无头浏览器
options.add_argument('--disable-gpu')
# options.add_experimental_option('detach', True) # 不自动关闭浏览
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 浏览器驱动
ser = Service(executable_path='/Users/adolf/Downloads/chromedriver-mac-x64/chromedriver')
# 创建浏览器对象
self.web = Chrome(options=options, service=ser)
# 也可以在__init__中执行这个方法
# self.spider_opened(None)
@classmethod
def from_crawler(cls, crawler):
""" 创建 """
# This method is used by Scrapy to create your spiders.
s = cls()
# 打开时执行
# crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
# 关闭时执行 创建 spider_closed 方法
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s
def process_request(self, request, spider):
""" 处理请求 """
if "zhipin" in request.url:
# 发起请求
self.web.get(request.url)
# 随机延迟时间
time.sleep(random.randint(1, 10))
# 获取源码
page_source = self.web.page_source
# 返回 HtmlResponse对象
return HtmlResponse( # 封装HtmlResponse对象
url=request.url,
body=page_source,
request=request,
encoding="utf-8"
)
else:
return None
def process_response(self, request, response, spider):
""" 处理返回 """
return response
def process_exception(self, request, exception, spider):
""" 处理异常 """
pass
def spider_opened(self, spider):
""" 爬虫打开 """
options = ChromeOptions()
# options.add_argument('--headless') # 启用无头浏览器
options.add_argument('--disable-gpu')
options.add_experimental_option('detach', True) # 不自动关闭浏览
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 浏览器驱动
ser = Service(executable_path='/Users/adolf/Downloads/chromedriver-mac-x64/chromedriver')
# 创建浏览器对象
self.web = Chrome(options=options, service=ser)
def spider_closed(self, spider):
""" 爬虫关闭 """
time.sleep(3)
self.web.quit()
# 在__del__中无法自动关闭浏览器 所以用closed方法
# def __del__(self):
# """ 爬虫关闭 """
# time.sleep(3)
# self.web.quit()

3. 启用中间件
settings.py
# 启用下载中间件
DOWNLOADER_MIDDLEWARES = {
"BossPro.middlewares.BossproDownloaderMiddleware": 543,
}
















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









