







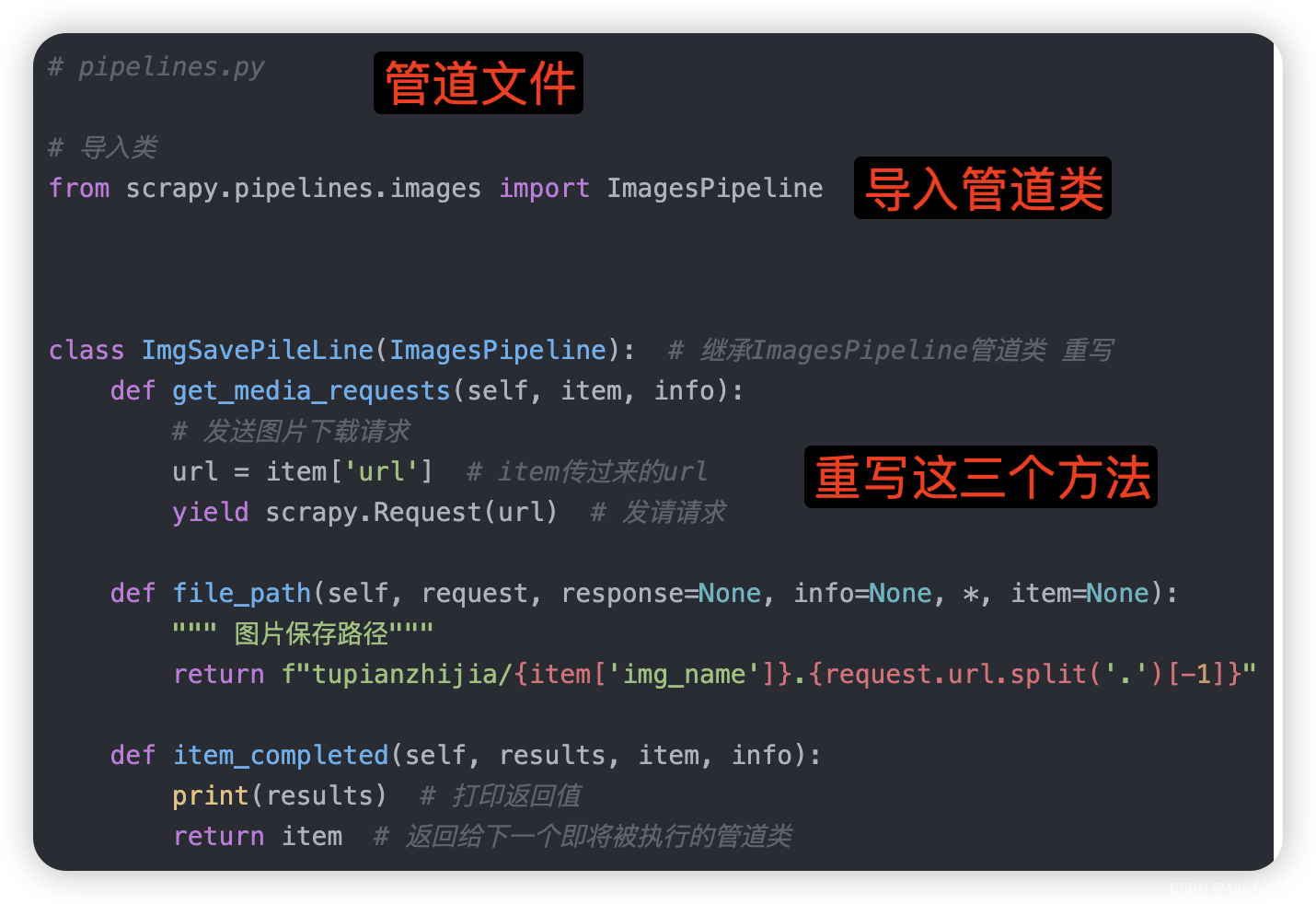
1.继承管道类
# pipelines.py
# 导入类
from scrapy.pipelines.images import ImagesPipeline
class ImgSavePileLine(ImagesPipeline): # 继承ImagesPipeline管道类 重写
def get_media_requests(self, item, info):
# 发送图片下载请求
url = item['url'] # item传过来的url
yield scrapy.Request(url) # 发请请求
def file_path(self, request, response=None, info=None, *, item=None):
""" 图片保存路径"""
return f"tupianzhijia/{item['img_name']}.{request.url.split('.')[-1]}"
def item_completed(self, results, item, info):
print(results) # 打印返回值
return item # 返回给下一个即将被执行的管道类
2.在settings.py设置下载文件目录
# settings.py
ITEM_PIPELINES = {
"tupianzhijaiPro.pipelines.TupianzhijaiproPipeline": 301,
"tupianzhijaiPro.pipelines.ImgSavePileLine": 200, # 开启管道
}
# 指定图片存储的目录
IMAGES_STORE = './tu_pian_zhi_jia_img' 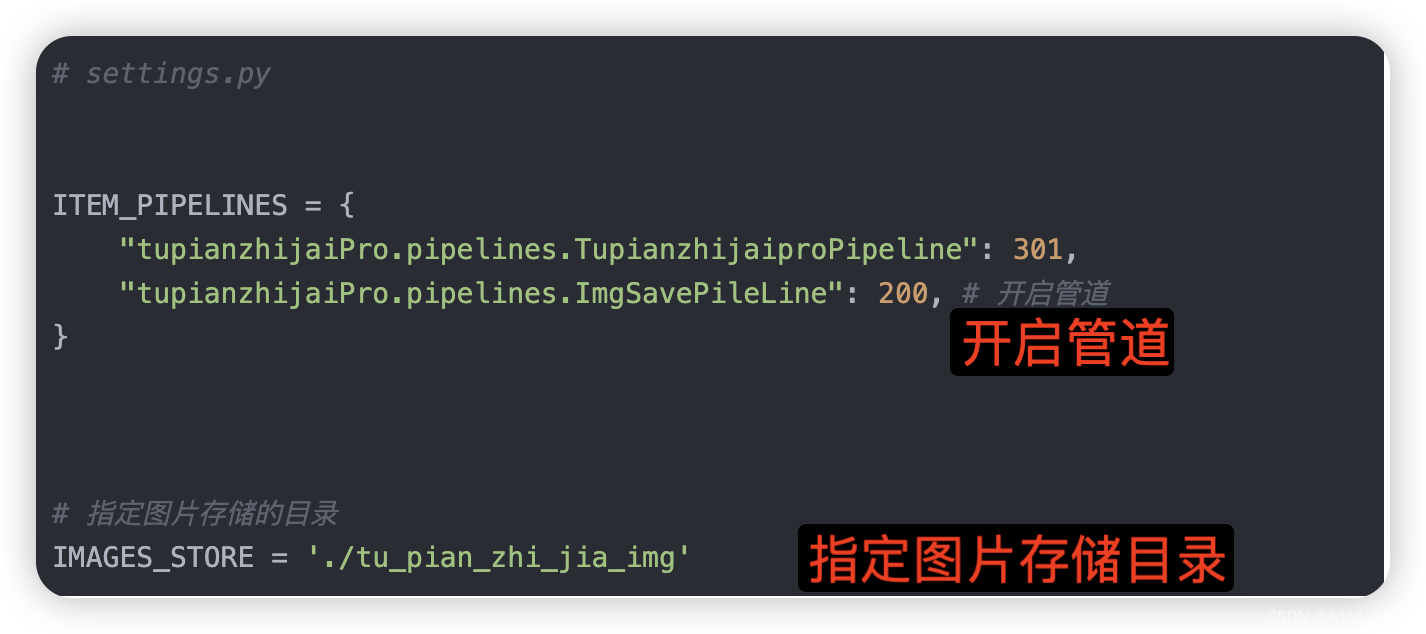















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









