









互联网动态网站当访问量达到一定数量之后对cache的使用几乎是不可避免.目前主流的换成软件应该是memached
那么在cache设计及程序实现上应该遵循哪些原则呢?
(注:这是我在工作中的体会,无理论支持)
1、首先要对cache所缓存的数据级别进行明确的定义。
L1:页面cache,缓存渲染后的页面
L2:数据cache:缓存页面数据
L3:数据结构cache:缓存应该数据实体
自上而下,缓存的数据单位越来越小,在某些网站可能同时存在这三种缓存.
2、保证数据的有限时间一致性及最终一致性。
有限时间一致性:就是说数据的更新应该是在可预知的时间内自动更新cache。
有时候保证cache的有限时间一致性并不是很容易的事情,如果你的设计不是很合理的话。假如你cache了一个较复杂的实体,有关实体的编辑更改会发生在很多地方,甚至以后还会有实体的新的活动出现。如果你把cache的失效放在每一个发生更改的地方,那么后继者们,很可能不知道这件事情,而导致cache没有更新,如果这件事情被发现的不及时,为了保证数据的一致性你可能需要把所有的cache更新一遍,来修复cache。合理的设计应该是把cache失效放在最底层并且是默认调用。
最终一致性:(特别重要)保证db中的数据是正确的,在cache出问题的时候可以通过一定的手段与db保持一致(为了保证数据最终一致性,需要注意的是,跟修改有关的操作,数据必须从db中取,防止因为cache与db不一致导致数据无法恢复)。
3、读写cache应该在同一个函数中进行
充cache的程序逻辑应该是这样的,读cache-->失败--> 充cache,而不是把充cache放在底层接口,读cache分散在各个上层接口,这种设计看似巧妙,却很容易出现数据不一致,及逻辑漏洞.
在实现上只需要3个函数,getfromcache,getfromdb,updatecache
4、应该设有全局的cache开关
每一级cache都应该设置有开关,这是可测性及追查问题简单性的需求,程序设计应该保证每一处逻辑都是可测试且尽可能易测试的,程序的设计应该在架构层面保证问题追查的简单性。
建议:对来自cache的数据做标记,这个建议对程序的执行与功能没有任何意义,但是当数据出现问题的时候,可以清楚知道数据的来源。
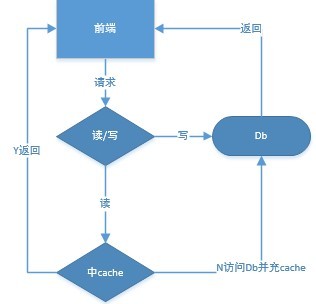
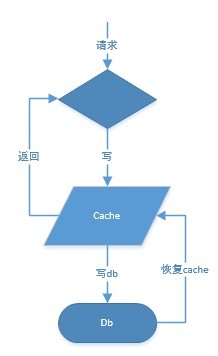
小知识:旁路cache与穿透型cache
旁路cache:程序可以在未中cache时,选择读db
穿透型cache:又叫全cache,db值是作为数据恢复的备份,所有读写操作都通过cache.额外的逻辑处理cache与db中间的事情.
旁路cache(左)与穿透型cache示意图(右)















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









