







引言
在服务端的业务开发中,我们经常会使用到各种各样的缓存,不管是localCahce还是memcache,其目的都是为了记录上一次的计算结果,用于优化性能的。服务端很多时候做的工作,其实就是花式的crud,而其中的花式,主要就提现在缓存的设计上,缓存设计的好,可以有效的提示集群的吞吐量,设计的不好,会极大的拉低系统的性能。
本文只是针对一些很简单的点进行的总结,方法和原理都很简单,但是落实到工作中,可能并不总能做得恰到好处。
高效使用的原则
先在这里抛出我个人在工作中总结的结论,缓存在代码中设计要遵守的原则
* 越少的缓存使用,越有价值
* 离最终的计算结果越近,越有价值
* 对于需要消耗I/O资源的缓存,要尽可能的减少调用的次数。
固化的数据的情况
我们以QQ浏览器的首页为例。我只是借用图片,方便说明,不代表他们是这么做的,当然我也不知道他们实际怎么做的。
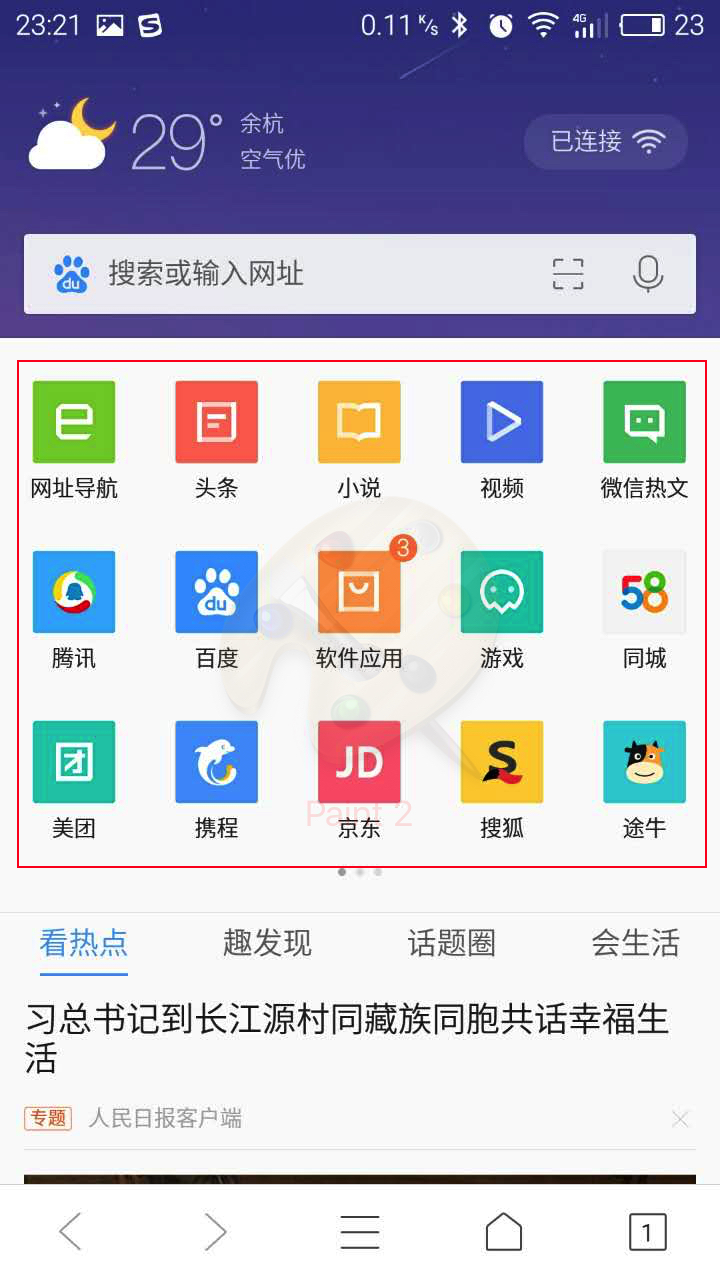
我们假设这里推荐的导航块,是由运营在后台配置,然后客户端在打开页面的时候向服务端请求首页需要显示的数据。如果这个显示的数据每个用户显示都一样,或者说大部分用户都显示一样的,运营也不是经常修改这些数据,加上这些配置本身数据量不大。这个时候我们设计缓存,可以很简单的将全部的数据缓存。伪代码如下
public List<RecommendUrl> getRecommendUrl(){
List<RecommendUrl> list = getRecommendUrlFromCache();
if(list == null){
list = getRecommendUrlReal();
putCache(list);
}
return list;
}具体的缓存,我们可以使用localCache,也可以使用memcache,都是适用的。
数据有变化的情况
上面的场景很简单,一般来说我们将缓存设计的越靠前,得到的性能更好。如果当请求到来的时候,我们直接返回缓存结果,这个时候我们接口的性能,可以无限的接近缓存的性能上限,因为我们只是单纯的转发了请求。上面的场景是我们遇见的大部分场景。但是同样我们经常会遇到动态变化数据的情况。如下图是QQ浏览器中的资讯。
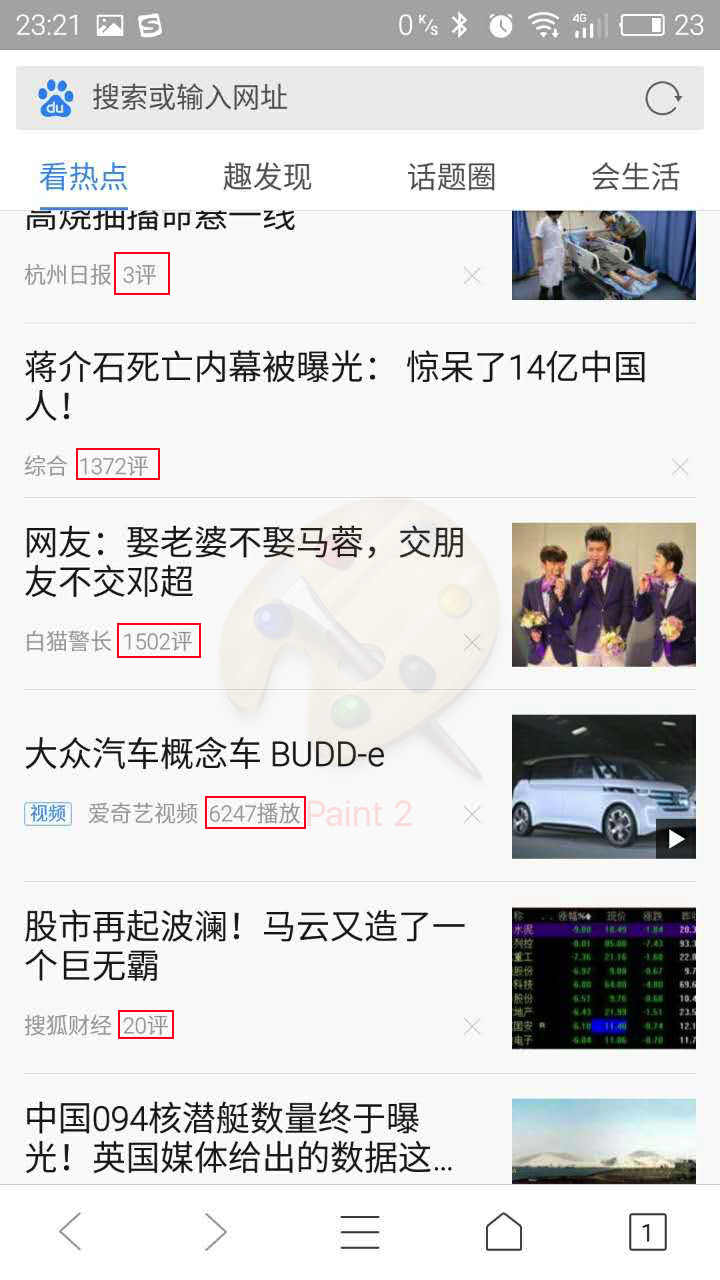
我们观察图中标红的部分,这些是用户的评论数据,一般来说用户评论是个写入过程。假设我们使用之前的策略使用memcache缓存所有的文章。
List<News> newsList = getNewsFromMemcache(); user.addComment(userComment).to(newsId);
cleanNewsMemcahce();这个时候,会有两个问题问题。
* 一旦有任意一篇资讯被评论或者被修改了,都需要通知缓存进行修改。而实际上当缓存的资讯比较多的时候,会发现实际上我们的缓存一直被击穿,缓存基本上起不到任何作用。
* 代码耦合,对于评论来说,评论不应该了解太多的业务细节。对于浏览器首页第一个tab,我们设计了一个缓存,当我们评论的时候,我们需要清理缓存,如果第二个tab也有这么一个缓存,那么还要通知另个tab的缓存也做清理,这样每次添加类似的缓存接口,都需要修改评论的代码,这样是显然违反开闭原则的。
缓存实体的唯一标识,而不是实体
在上面这个场景下,直接缓存资讯是不合适的。实际上资讯应该有一个自身的管理实例去做缓存管理的工作。而不是在上层业务层做缓存。所以这里合适的方案是,我们先设计一个资讯自身的缓存管理对象,然后在外部接口,只缓存需要实体的唯一标识。所以这个场景合适的设计方案应该是。
先有一个资讯管理的方案。因为我们希望同时查询多个id对应的数据,所以技术选型上,redis会比较合适。
public class NewsManager{
public List<News> getNewsFromRedisByIds(List<Long> ids){
//略
}
public boolean cleanCache(Long ... newsId){
//略
}
} public List<News> getRecommendNews(){
List<Long> ids = getRecommendNewsIdsFromMemcache();
if(ids == null){
ids = getRecommendNewIdsReal();
putCahce(ids);
}
return newManager.getNewsFromRedisByIds(ids);
}这个时候由于新闻资讯manager自身管理缓存和实际数据的获取策略,这个时候评论,只需要对这个manager操作就好了。
user.addComment(userComment).to(newsId);
newManager.cleanCache(newsId);通过上面的处理,我们减少了getRecommendNewIdsReal()的调用量,提升了性能,而且我们设计了一个新闻资讯自身的管理,这样在其他地方就可以方便的使用,沉淀了能力。
数据量很大,缓存需要缓存的部分
我们来看这么一个场景,在每篇新闻资讯的下面都会有个相关推荐。我们假设有如下背景
1. 每篇文章都有个热度值。
2. 每篇文章都会有至少一个标签,可能会有很多标签
3. 在数据库中,每篇文章资讯都有个字段记录文章被打上的标签,而没有数据库记录了每个标签有哪些资讯打了这个标。
4. 我们的文章资讯数量极大,大概数据量是百万级别。
5. 我们的标签数量很多,大概有上百个。
我们的需求是
1. 显示这篇文章对应的标签中,热度值最高的三篇。
2. 如果有多个标签,则显示多个标签下热度值最高的三篇。
一般来说实时数据的排序和计算的成本是比较大的,一般来说对于这样的业务,我们没有必要做的完全实时,伪实时就好,比如每隔1个小时更新一次就好了。
首先我们来分析,我们肯定需要先把各个标签对应的新闻资讯,收集起来。收集的方案,基本上就是分页page扫描新闻的全表,然后根据新闻资讯的标签来归类。基本的思路如下
while(hasNextPage()){
List<News> list = getCurrPageNews();
for(News news : list){
for(Integer tag : news.getTags()){
allNewsMap.get(tag).add(news);
}
}
}当我们能将数据归类好之后,如果将allNewsMap放入缓存,那么后续的工作我们只需要做一个简单的排序就好了。但是请记住我们的前提,我们有上百万的新闻资讯,实际上由于每篇新闻至少有一个标签,会导致我们这样计算的allNewMap在序列化后,会有远大于百万级的资讯数量,这样显然是不合理的,而且如此大的Map,内存也很难放的下。所以在当前业务场景下,如果上述的方案是不合理。
只缓存实际有可能触达用户的
在设计的时候,我们不要框于技术,要考虑产品的形态,在这个场景下,实际上我们每篇文章,我们只最多推荐3篇,热度最高的三篇,也就是说,对于每个标签,我们实际上只需要标签下热度最高的三篇就好。而且就像我们提过的,如果实体容易改变,而我们需要下发的实体不变,那么我们缓存实体的标识就好了。所以我们可以使用如下方案。
我们的数据设计如下
public NewsHot{
private Long newsId;
private Long hotValue;
//setter getter 略
}
Map<Integer,Priority<NewsHot>> allNewsMap = getPrototype();
while(hasNextPage()){
List<News> list = getCurrPageNews();
for(News news : list){
for(Integer tag : news.getTags()){
allNewsMap.get(tag).add(news);
if(allNewsMap.get(tag).size() >= THRESHOLD){
allNewsMap.put(tag,
TopN(allNewsMap.get(tag),3));
}
}
}
}
TopN(allNewMap,3);上述的方案用到了大堆,我们每次都把数据放入到一个大堆,然后当大堆增长到一定程度的时候,我们截断大堆,只留下TopN我们需要的数据。这样当整个算法结束的时候,我们会留下一个Map,这个map的key的数量小于等于我们所有标签的数量,每个key对应的value的长度小于等于3。这样我们一共只需要缓存几百条数据就好。这样我们就能很轻松的放入缓存中。当我们需要计算推荐的时候,我们可以通过这个缓存的值,快速的计算出,需要推荐的数据。
结论
深入业务,才能有好的设计。在设计缓存的时候,要根据我们的业务特点,明白什么是不容易变的,什么是相对容易变,什么是真正触达用户的,哪些数据是关键。这样才能发现真正应该cache的点。















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









