







阅读文献:“Pre-trained Models for Natural Language Processing: A Survey”
本文主要做了一下贡献:
- 总结了背景知识,模型架构,预训练任务,变体,适应方法,应用。
- 从四个不同的角度将预训练语言模型分类讨论:1)特征类型 2)模型架构 3)预训练任务类型 4)针对特定类型的场景的扩展。
- 收集了大量的开源的预训练语言模型。
- 讨论了已有预训练语言模型的不足,以及可能的未来研究方向。
Background
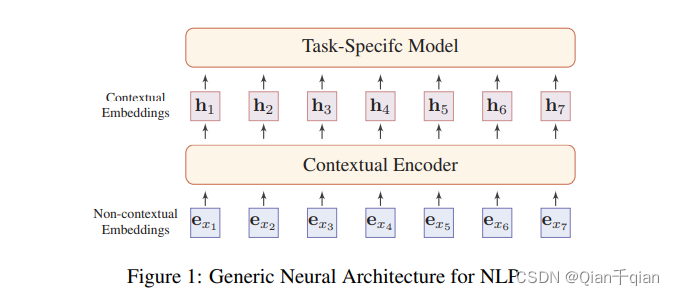
传统结构:不含有文本意思的词向量经过编码,成为含有文本意思的词向量。(个人理解是上游)接着应用于特殊任务(下游)
不含文本意思的词向量的缺陷:1)静态的,不随上下文的改变而改变。2)out-of-vocabulary problem,遇到词典之外的词语。
含文本意思的词向量的介绍:就是Encoder之后的词向量。每个词的词向量与整句话相关。
神经网络的文本的encoders能被分为两类:seq model和non-seq model
Seq model:
-
卷积模型
卷积神经网络
-
循环模型
LSTM、GRU
Non-Seqence Model:
- 单词间的树、图结构:Recursive NN(不知道是啥)、TreeLSTM(不知道是啥)、GCN
- 自注意力机制
PTMs for NLP:
无监督的预训练,有监督的fine-tuning
-
第一代PTMs:预训练词向量,是NNLM的先驱工作
Word2Vec:CBOW和Skip-Gram。与此同时,还出现了paragraph vector,Skip-thought vector,Context2Vec
-
第二代PTMs:预训练上下文的编码器
LSTM、seq2seq、ELMo(双向LSTM)、ULMFiT(Universal Language Model Fine-tuning)
-
近代:GPT、BERT
Overview of PTMS
Pretrained Task
有三种预训练任务:
- 有监督学习(SL):学习一个基于输入输出对组成的训练数据将输入映射到输出的函数
- 无监督学习(UL):无监督学习(UL)是从无标记数据中发现一些内在知识,如集群、密度联系、潜在表示。
- 自监督学习(SSL):和有监督学习一样,只不过数据的标签是自动产生的。核心观点是通过输入数据的一部分预测另一部分。例如Masked language model(MLM)
机器翻译任务是最有挑战性的任务之一,并且它的encoder的预训练对其他下游NLP任务也有很大推动作用。
自监督的预训练任务和使用的损失函数:

语言模型(LM):使用概率计算。缺点:只有上文信息,没有下文信息。
Masked Language Modeling(MLM)
Mask一些单词,通过剩下的单词来预测Mask掉的单词。
Seq2Seq MLM
将一个masked的句子输入编码器,解码器以自回归的方式按顺序产生掩码token。该模型被用于MASS和T5。可用于下游任务,例如问答,总结和机器翻译。
E-MLM(Enhanced Masked LM)
RoBERTa通过动态masking提升了BERT
Permuted Language Modeling(PLM)
有人指出,上游使用Mask,下游不使用Mask,将导致预训练和fine-tuning之间存在gap。
PLM会对输入句子进行随机排列。然后选择词语Mask,进行预测。但是效果不好。
Denoising Autoencoder(DAE)
该模型是拿一个被破坏了的输入,然后目的是恢复原来的输入。有几种方式去破坏文本:
-
Token Masking
-
Token Deletion:不同于第一种方法,这种方法还需要预测失去输入的位置。
-
Text Infilling:
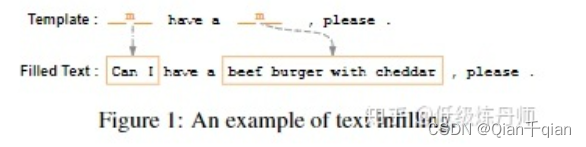
预测两个空白部分,空白处的位置和数量都是已知的,但是缺失词的数量不知道,自己觉得生成多少词。
-
Sentence Permutation:将文本分成句子,并打乱。预测句子顺序。
-
Document Rotation:随机一致地选择一个token,并旋转文档,使其从该token开始。模型需要确定文档的实际起始位置。
Contrastive Learning(CTL)
损失函数:
L
C
T
L
=
E
x
,
y
+
,
y
−
[
−
l
o
g
e
x
p
(
s
(
x
,
y
+
)
)
e
x
p
(
s
(
x
,
y
+
)
)
+
e
x
p
(
s
(
x
,
y
−
)
)
]
L_{CTL}=E_{x,y^+,y^-}[-log\frac{exp(s(x,y^+))}{exp(s(x,y^+))+exp(s(x,y^-))}]
LCTL=Ex,y+,y−[−logexp(s(x,y+))+exp(s(x,y−))exp(s(x,y+))]
s ( x , y ) = f e n c ( x ) T f e n c ( y ) s(x,y)=f^T_{enc(x)}f_{enc(y)} s(x,y)=fenc(x)Tfenc(y)
or
s
(
x
,
y
)
=
f
e
n
c
(
x
⊕
y
)
s(x,y)=f_{enc}(x\oplus y)
s(x,y)=fenc(x⊕y)
pairwise ranking task:替换中心词汇,让模型预测该句子是否合法。
Deep InfoMax(DIM)
Replaced Token Detection(RTD):根据上下文预测是否token被替换。ELECTRA提升了RTD的性能,通过设置一个产生器G和一个鉴别器D,一共有两个步骤:1)使用MML来训练G。2)使用G的权重初始化D,然后冻结G,微调D,使用的是鉴别任务(鉴别是否token被G替换)。预训练之后G被扔掉,只用D进行下游任务的微调。
Next Sentence Prediction(NSP):利用标点符号来构造预训练语言模型。预测两个句子是否相连。这样可以让模型理解输入句子的关系,进而有利于对信息敏感的任务,例如问答和推理。后来有人发现这个东西不可靠。
Sentence Order Prediction(SOP):ALBERT使用该方法代替了NSP,使用两个连贯的句子在同一个文本中作为正例,将这两个句子顺序交换作为反例。结果ALBERT胜过BERT在各种各样的下游任务中。StructBERT和BERTje也采取SOP作为他们的自监督学习任务。
Others
Cross-lingual task、multi-model applications
Taxonomy of PTMs
从四个方面对已经存在的PTMs进行分类:
- 特征种类:分为文本级模型和非文本级模型
- 架构:分为LSTM、Transformer Encoder(self attention)、Transformer Decoder(masked self-attention)、Transformer Encoder-Decoder
- 预训练任务种类:之前已经讨论过了。
- 扩展:根据不同的场景分类。 knowledge-enriched(知识扩展)、multilingual or language-specific(多种语言或者特殊语言)、 multi-model(多模态)、,domain-specific(特定域)、compressed(浓缩)(翻译可能不是很好)
分类图:
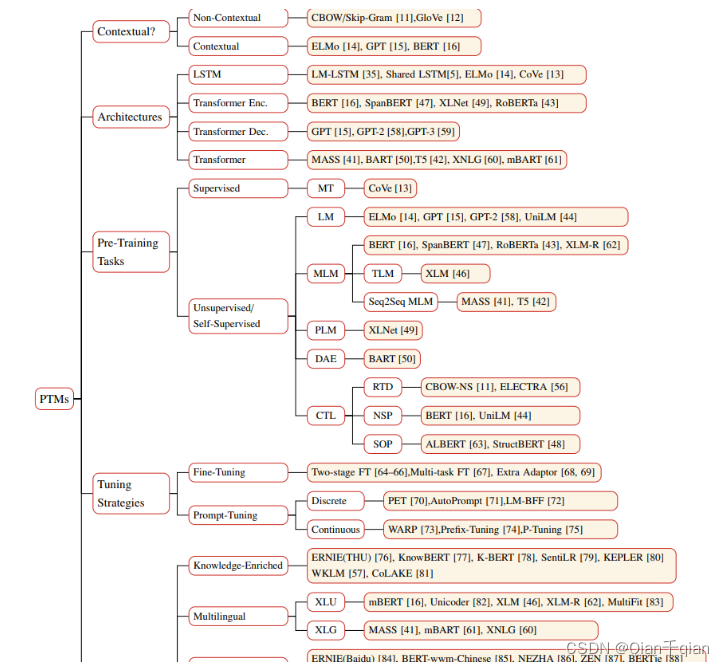
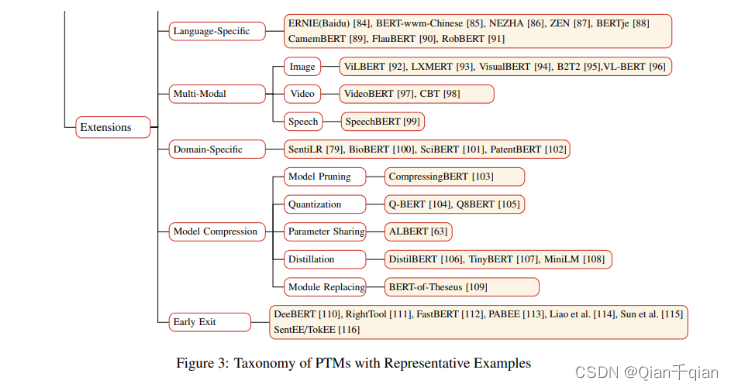
总结:
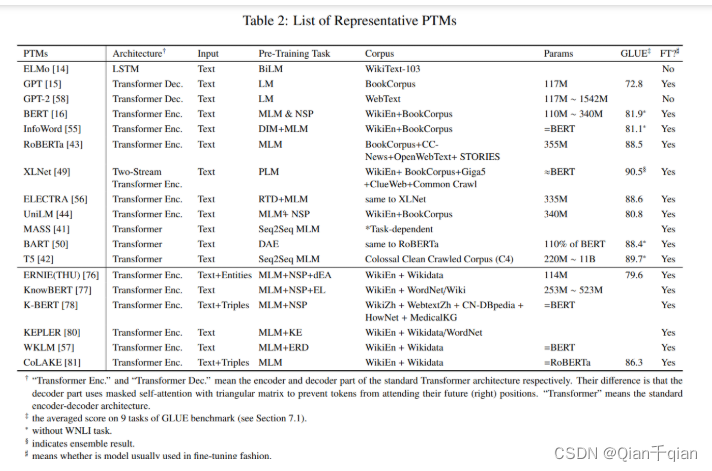
Model Analysis
主要讨论文本级的PTMs和非文本级的PTMs分别获得了什么知识。
Non-Contextual Embeddings:
有人证明skip-gram能获得句法和语义的词语的关系。例如:
vec(“China”) − vec(“Beijing”) ≈ vec(“Japan”) − vec(“Tokyo”)
还发现了语义合成的秘密:vec(“Germany”) + vec(“capital”) is close to vec(“Berlin”).
Contextual Embeddings:
大概有两种知识可以学习:( linguistic knowledge)语言知识和(world knowledge)全局知识
- 语言知识:有人证明了BERT有各种各样的能力,通过提取依赖树证明了其能够获取句法结构。
- 全局知识:“Dante was born in [MASK]”
Extensions of PTMs
Knowledge-Enriched PTMs(知识扩展)
PTMs一般会缺乏特殊领域的知识。引入额外的知识会使得模型更加有效。早期的研究集中于知识图谱嵌入和词嵌入想混合。自从BERT之后,通过设置一些辅助性质的预训练任务来融入额外的知识。并且融入额外知识的时候不需要重新训练他们,只需要微调即可。
knowledge graph language model(KGLM)和latent relation language model(LRLM),这两个模型支持基于知识图谱的预测。
Multilingual and Language-Specific PTMs(多种语言或者特殊语言)
-
Mulitilingual PTMs(多语言)
Cross-Lingual Language Understanding (XLU) :早期是研究多语言词向量,试图将多语言合并到一个语义空间中。mBERT展示了很强的能力。
XLM提升了mBERT通过加入了一些交叉语言的任务。
XLM-RoBERTa (XLM-R)的训练数据集比较庞大。
Cross-Lingual Language Generation (XLG):生成不同语言的文本。这种模型需要对编码器和解码器都进行训练。、
-
Language-Specific PTMs(特殊语言)
有人用迁移学习技术将一个多语言的PTM转化为了俄语模型。另外,一些单语言模型也被训练成专用语言的模型。
Multi-Modal PTMs(多模态)
将视觉和语言特征编码。这些模型再一些大型多模态语料库中进行训练,例如语音或者图像。VideoBERT、VisualBERT、ViLBERT
-
Video-Text PTMs
VideoBERT 和 CBT
-
Image-Text PTMs
-
Audio-Text PTMs:SpeechBERT
Domain-Specific and Task-Specific PTMs(特殊领域和特殊任务)
大多数语言模型都是使用普遍的语料库,例如维基百科,这限制了模型在特殊任务上的学习能力。但是最近已经有人提出了特殊领域的模型。
Model Compression(模型浓缩)
由于参数很多,因此难以在真实生活中为人民服务,模型浓缩是一个有潜力的方法去减小模型尺寸和提升计算效率。
有5种方法去压缩PTMs:
-
模型剪枝。移除不重要的参数
移除部分网络(权重、神经元、层、核、注意力头)。
-
权重量子化。使用更少的存储空间去存储参数。
将高准确度参数压缩到更低的准确度。这个方法需要可兼容的硬件。
-
参数共享相似的模型单元。
典型模型:ALBERT。虽然参数减少了,但是推理时间变得更长。
-
知识蒸馏。训练一个更小的模型从起初的模型当中学习中间的输出。
知识蒸馏(KD)[168]是一种压缩技术,其中一个叫做学生模型的小模型被训练来重新产生一个叫做教师模型的大模型的行为。该机制能被分为三种类型:
-
从软目标概率中提取
有人证明通过使得学生来模仿老师能使得知识从老师转移到学生。DistilBERT训练学生模型使用蒸馏损失函数:
L K D − C E = ∑ i t i ⋅ l o g ( s i ) L_{KD-CE}=\sum_i{t_i}\cdot log(s_i) LKD−CE=i∑ti⋅log(si)
t i t_i ti和 s i s_i si分别是老师和学生所预测的可能性。从软目标概率中提取也能被应用于特殊任务模型中。
这种模型实际上是将老师模型看作一个黑盒,并且只关注它的输出。
-
从其他知识中提取
TinyBERT、MobilBERT
-
蒸馏到其他结构中
将Transformer模型蒸馏到RNN或者CNN能减少计算复杂度。
-
-
模型替换。用更紧凑的替代品替换原来的模块。
BERT-of-Theseus
-
Early Exit(提前退出)
让模型提前退出来代替通过整个模型,执行的层数由输入决定。
Depth-adaptive transformer学会了预测有多少层encoding layer需要执行对于一个特别的序列。
DeeBERT、RightTool、Fast-BERT、ELBERT、PABEE均减少了encoder的计算,他们减少计算的方法通常包含两步:
- 训练被注射的信息离开匝道(买看懂)
- 设计一个提前退出策略。
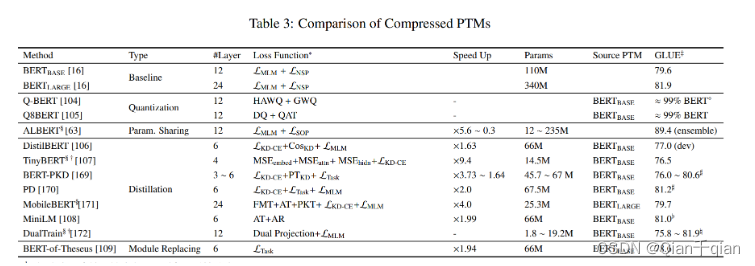
Adapting PTMs to Downstream Tasks
Transfer Learning(迁移学习)
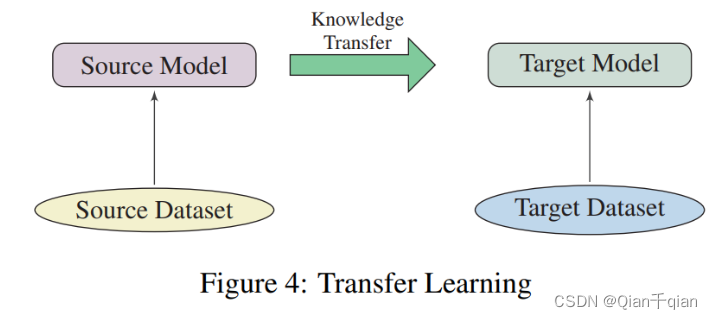
NLP领域中迁移学习的种类:domain adaptation(领域自适应)、 cross-lingual learning(跨语言学习)、 multi-task learning(多任务学习)。下游任务是有标签数据。
怎样迁移?
为了将PTM的知识迁移到下游任务中,我们需要考虑以下几个问题:
-
选择合适的预训练任务,模型架构和语料
-
选择合适的layers:不同层能捕获不同种类的信息
有三种layer可选:
- Embedding Only:一种静态的预训练嵌入,不能够捕获更高级别的有用的信息。词向量仅仅在捕获词的语义信息有用。
- Top Layer:最简单有效的方法。
- All Layers:一种更灵活的方式去自动选择最好的层。例如ELMo。
-
是否进行微调?
两种模型迁移的方法:特征提取(冻结预训练参数)、微调(更常用、更便利)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MnhdyMCL-1664289552043)(C:\Users\11878\AppData\Roaming\Typora\typora-user-images\image-20220731141219448.png)]
微调策略
-
Two-stage fine-tuning(两级微调):这是一种介于预训练和微调之间的策略。
-
Multi-task fine-tuning(多任务微调):有人证明了多任务学习和预训练是互补的技术
-
Fine-tuning with extra adaptation modules(使用额外适应模块微调):微调的主要不足在于参数的无效率,解决方法是注入一些微调适应模块,而起初的参数是固定的。
-
其他。















 2196
2196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









