







介绍
对C++选手烂大街的项目Webserver进行局部优化,将定时器模块(定期处理非活跃连接)由小根堆实现更改为用跳表实现,克服了用小根堆实现定时器的一些弊端。
定时器模块的功能主要包括:
- 每一个客户端与服务器建立好连接后,为该连接创建定时器,经过一段时间后,若客户端没有与服务器进行通信,服务器则认为其为非活跃连接,将这个连接删除,以便其他客户端接入。
- 定期检测(心跳)非活跃的连接,将这些非活跃的连接清除。
- 若用户在被清除前与服务端进行交互(读写),延长该节点的超时时间(因为是活跃用户)。
- 若因其他原因导致连接中断,立即清除该连接的定时器。
需求
wabserver项目利用定时器模块(以下称为timer),来定期清除不活跃的连接,对外需要提供接口实现清除和添加连接的功能,内部需要使用一定的存储结构来保存每个连接对应的定时器。
- timer模块需要向主线程提供四个api:
- 添加定时器,有客户端与服务器进行连接时,为该连接创建定时器,并添加到timer模块的存储结构中(该存储结构默认是小根堆,本文目的就是将其更改为跳表);
- 给指定的定时器延时,延长活跃用户的超时时间;
- 心跳,检查并清除所有超时的用户;
- 删除指定连接的定时器。
小根堆实现 timer
利用小根堆实现timer,可以利用哈希表建立定时器节点索引与事件文件描述符的映射关系,所以查找事件所对应的定时器所需要的时间复杂度为O(1)。
简要的逻辑结构和物理结构的对应图如下:

节点上数据为该定时器剩余超时时间,单位为毫秒(ms)。
复杂度分析
- 添加定时器:O(1),只要将节点插入小根堆末尾即可,因为新插入节点剩余的超时时间必然最大。
- 节点延时:
- 找到节点:O(1),利用文件描述符和节点下标的映射关系(哈希表),可以在O(1)时间复杂度下找到该节点;
- 给节点设置延时后向下修复小根堆性质:O(logn);
- 总的时间复杂度:O(logn);
- 心跳:
- 从前向后遍历节点,超时则删除连接,复杂度O(n);
- 每次删除都要将头节点和尾节点互换,删除尾节点,再修复小根堆性质,复杂度O(logn);
- 总的时间复杂度:O(nlogn);
- 删除指定节点的定时器:
- 找到节点,复杂度O(1),利用哈希表,同节点延时;
- 删除节点并修复小根堆性质,复杂度O(logn);
- 总的时间复杂度:O(logn)。
存在的问题
1、节点漏删
小根堆逻辑结构是一个完全二叉树,而物理结构是一个数组(数组中每个元素代表一个定时器节点),如果一次只删除一个节点(就像实现优先队列一样),那么不存在节点漏删的情况。可是在实现timer的过程中,小根堆需要提供节点延时和批量删除的功能,当一个节点延时之后,会破坏物理结构当中的递增顺序,如下图:
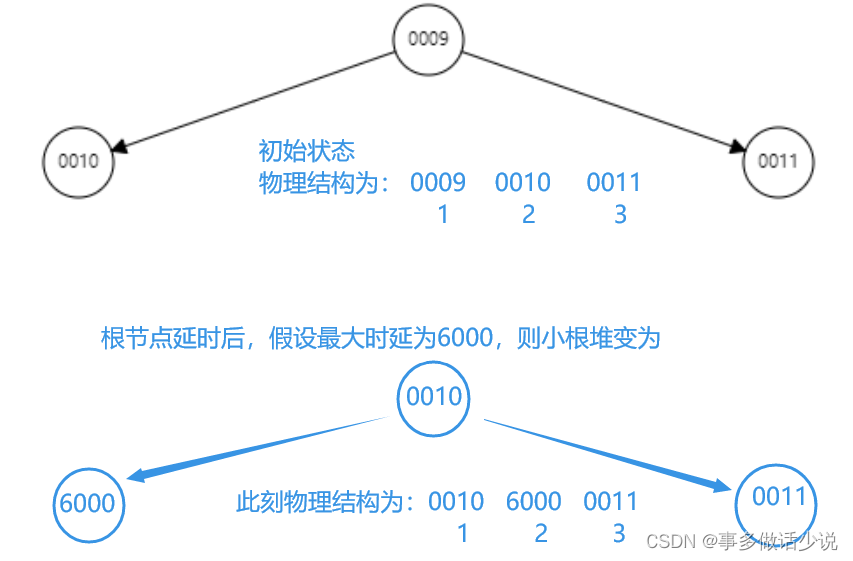
- 按照节点插入的先后顺序插入小根堆,所以初始状态下小根堆中节点是按从小到大顺序存放的。
- 假设根节点对应的连接此时和服务端进行交互,那么系统对根节点设置延时并向下修复小根堆性质,此时物理结构中节点已经不按顺序存放了。那么当11ms过后,下标为1和3的节点都已经过期,但下标为2的节点还剩很长的超时时间,这会导致下一次心跳操作的时候,遍历到节点2时,就结束心跳,后面的节点3也超时了,但是没被删除。
2、心跳复杂度太高
- 心跳操作需要将已超时的所有节点都删除,根据小根堆性质,需要从前往后遍历,才能找到所有超时节点(剩余超时时间最小);
- 而根据小根堆性质,每删除一个节点都需要将删除节点和小根堆最后一个元素交换,删除堆尾元素,最后再向下修复小根堆性质,需要的时间复杂度为O(logn);
- 那么总的时间复杂度就为O(nlogn),实际上这是可以利用其它结构进行优化的,比如跳表。
跳表实现timer
用跳表实现timer,相比小根堆的一个明显优势就是存储结构本身是有序的。所以心跳操作过程中,从前向后遍历的时候不存在漏删的情况,而且大部分接口的时间复杂度要低于小根堆,具体分析如下。
复杂度分析
- 添加定时器:O(1),只要将节点插入跳表末尾即可,因为新插入节点剩余的超时时间必然最大,需要设置哨兵指向定时器尾部,相比于小根堆还需要额外更新索引指针。
- 节点延时:
- 找到节点:O(1),利用文件描述符和节点下标的映射关系(哈希表),可以在O(1)时间复杂度下找到该节点;
- 删除该节点,需要从前往后找到该节点的所有前驱节点(因为跳表的索引有多个层次),时间复杂度为O(logn);
- 最后在跳表尾部重新添加延时后的节点O(1);
- 总的时间复杂度:O(logn);
- 心跳:
- 从前向后遍历节点,超时则删除连接,复杂度O(n);
- 每次删除只需要释放节点并修改索引指向,时间复杂度O(1);
- 总的时间复杂度:O(n);
- 删除指定节点的定时器:
- 找到节点,复杂度O(1),利用哈希表,同节点延时;
- 删除节点并修复索引指向,复杂度O(logn)(需要找到前驱节点);
- 总的时间复杂度:O(logn)。
所有功能的时间复杂度相较于小根堆都有很大提升,理论上效率应当比小根堆高很多,但实际测试下来QPS相比用小根堆实现的服务器只高了1000左右…
思考原因
1、每个接口修复索引都可以在O(1)时间复杂度内完成,但实际上从上至下修复每一层索引的指针还是花了不少时间;
2、索引的层级(我设置8或16)还是比较高的,而且并不能缩小,不然每一层索引的密度会非常高;
导致每次删除或更新节点时修复索引的开销很大;
3、定时器模块对webserver的QPS影响可能本身就不大,还有其他几个模块也都会造成影响,思维确实不应该局限在这了。
存在的问题
- 利用小根堆实现timer,可以使用哈希表建立文件描述符fd和节点的映射关系(这应该是效率最高的搜索方式,可以将查找某一结点的时间复杂度优化到O(1)),那么实际上就用不到跳表本身复杂度为O(logn)的查询优势了;
- 实现过程中,需要设置哨兵指向跳表尾部(这样在添加新节点时时间复杂度为O(1)),但在高并发情况下,每次修改哨兵指向有可能被其他线程干扰,可以考虑使用原子变量进行优化。
















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











