






用简单例子阐述更易理解枯燥无味的定义,本文由浅入深解析两者的工作机理,为设计程序奠定基础,主要分两部分内容:
(i)举例理解循环神经网络(RNN [1], Recurrent Neural Networks)
(ii)举例理解长短期记忆网络(LSTM [2] ,Long Short-Term Memory)
0 序:
RNN为LSTM之父,欲求LSTM,必先RNN。
(i)RNN.
(a) RNN定义:
输入数据为序列,如:“water is hot”, “i like chinese chess”, 通过前后输入互相关联的网络,预测或者分类.
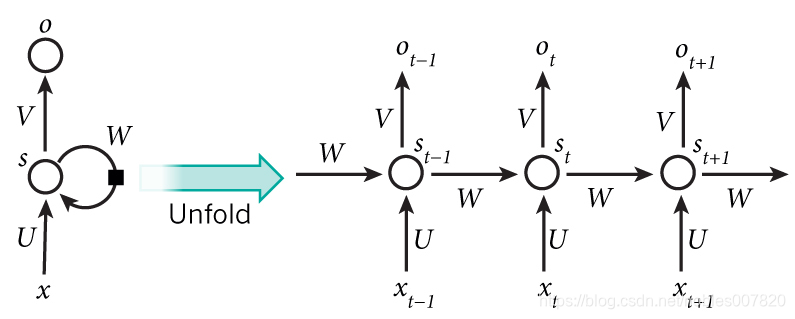
(b)举例理解RNN(batch size =1 )
如图一, 区别于深度神经网络(DNN),RNN多了一些隐层的输出。循环体现在前后节点的作用是统一的权重(W),神经网络的权重共享(U、V). 以water is hot为例阐述RNN工作原理,词性标注问题+语义识别 分别表示 序列输入-单输出(分类类别) 和 序列输入-序列输出(分类类别).
Example1 词性标注问题:看看一个句子每个单词是名词还是动词。
网络输入:
10000句类似标注好的句子。
如 Water(名) is(动) hot(形). I(名) am(动) a(形) man(名). 。。。
网络训练过程:
第一时刻,输入
x
1
x_1
x1= 00001001(water),标签
y
1
y_1
y1:01 (名), 通过网络得到隐层输出
s
1
=
f
(
U
x
1
+
W
∗
0
+
a
)
s_1 = f(Ux_1+ W*0 +a)
s1=f(Ux1+W∗0+a), 整个网络最后的预测输出
o
1
=
f
(
V
s
1
+
b
)
o_1 = f(Vs_1 + b)
o1=f(Vs1+b)。
第二时刻,输入x2 = 00101001(is), 通过网络得到隐层输出
s
2
=
f
(
U
x
2
+
W
s
1
+
a
)
s_2 = f(Ux_2+ Ws_1 +a)
s2=f(Ux2+Ws1+a), 整个网络最后的预测输出
o
2
=
f
(
V
s
2
+
b
)
o_2 = f(Vs_2 + b)
o2=f(Vs2+b)。
第三时刻…等等。 句子有多长, 就循环几次。
损失函数
o
1
,
o
2
,
o
3
.
.
.
o_1,o_2, o_3...
o1,o2,o3...与真实的标注的误差。
注: 前后两个时刻的输入向量维数相同。
Example2 语义识别:看看话是骂人还是夸人的
网络输入:
10000句类似标注完成的句子。
如 You are a really bad man(骂).
You are beautiful(夸)…
网络训练过程:
网络结构与词性标注问题相同,但是中间层的输出
s
1
s_1
s1 其实是不需要的,当然这个任务中也不会有对应的标签。我们其实仅仅需要最后的
o
n
o_n
on来达到看看这句话是骂我呢还是夸我。
损失函数就是
o
n
o_n
on…与真实的标注的误差。
当然还有 单输入但是输出为序列 同理可分析。
(ii) LSTM
(a) LSTM定义:
LSTM是RNN的son,长江后浪推前浪,LSTM看到RNN这个dad记住了太多有的没的,造成不好的影响(梯度消失or梯度爆炸),于是它向鱼取经-7秒记忆三开关大法,通过三个开关(又称作门)来把控要不要信息。三个开关:遗忘门,输入门,输出门。
LSTM就比RNN多个cell的机制,如下:
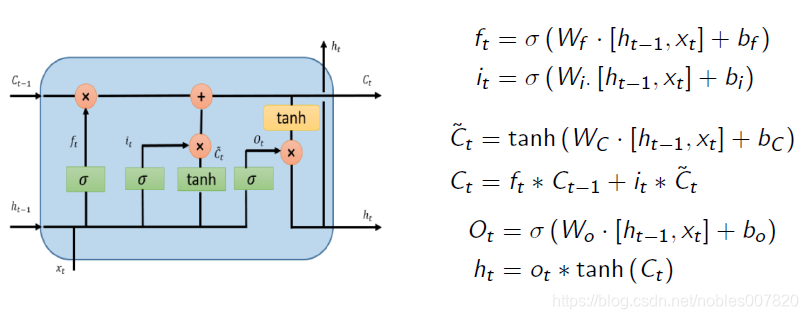
上图是经典之图,那一堆公式只要记着一个原则就行: 记忆或者遗忘的“权重”是0-1之间取值(最好是阶跃函数),“信息”是-1到1之间取值。用tanh做激活函数的式子都在计算“信息”,用
σ
\sigma
σ 函数的公式,都在计算权重.
f
f
f:遗忘门;
i
i
i:输入门;(这里为了理解就是0或者1)
o
o
o.:输出门(注意
O
t
=
o
t
O_t=o_t
Ot=ot,打印错误);
h
t
h_t
ht : 是隐层节点的值(相当于RNN图的s_t)。
C
t
C_t
Ct : 是cell的缩写,可以理解成现在的记忆, 脑子里的东西;
注:可以看出,此时
C
t
,
h
t
C_t, h_t
Ct,ht 共同影响后一个单词。
(b)举例理解LSTM
Example3 语义识别:看看话是骂人还是夸人的.
网络输入:
:10000句类似标注完成的句子。
如You are a really bad man(骂).
You are beautiful(夸)…
网络训练过程:
输入 x 特征, y 标签。
第一时刻,
输入 x_1= 00021000(You), 计算遗忘门 f_1 与输入门 i_1, 更新大脑知识 C_1,计算输出门, 通过输出门计算隐层神经元节点值h_1。
第二时刻,
输入 x_2= 00021020(are), 计算遗忘门 f_2 与输入门 i_2, 更新大脑知识 C_2, 计算输出门, 通过输出门和h_0计算隐层神经元节点值h_1。
第三时刻…等等。 句子有多长, 就循环几次。
最终网络的输出为
y
^
=
f
s
o
f
t
m
a
x
(
V
h
n
+
b
)
\hat{y} = f_{softmax}(Vh_n + b)
y^=fsoftmax(Vhn+b)
损失函数:
y
^
\hat{y}
y^与真实的标注
y
y
y 的误差(往往是交叉熵损失函数)。
[1]Goodfellow, I., Bengio, Y., Courville, A..Deep learning (Vol. 1):Cambridge:MIT Press,2016:367-415
[2]Schmidhuber, J., 2015. Deep learning in neural networks: An overview. Neural networks, 61, pp.85-117.
本文部分知识受以下文章启发,在此由衷感谢以下作者的分享!
https://blog.csdn.net/zhaojc1995(RNN简介)
https://zybuluo.com/hanbingtao/note/581764(LSTM简介)
https://zhuanlan.zhihu.com/p/27901936(RNN梯度具体求解)
















 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











