






基础模型:

引入辅助变量,给出增广拉格朗日函数:

分步求解:


考虑深度展开网络后重构模型:
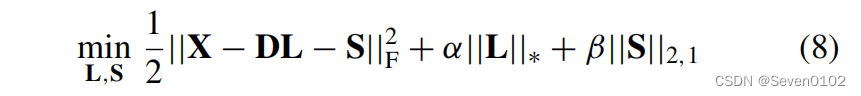
引入辅助变量,给出增广拉格朗日函数:

求解:

将传统的迭代过程与深度网络相结合;

由此,原始模型中的参数可以被深度网络中的可学习参数替代(没找到代码,不知道具体怎么设置替代的,深度网络可以指定学习的参数吗?)
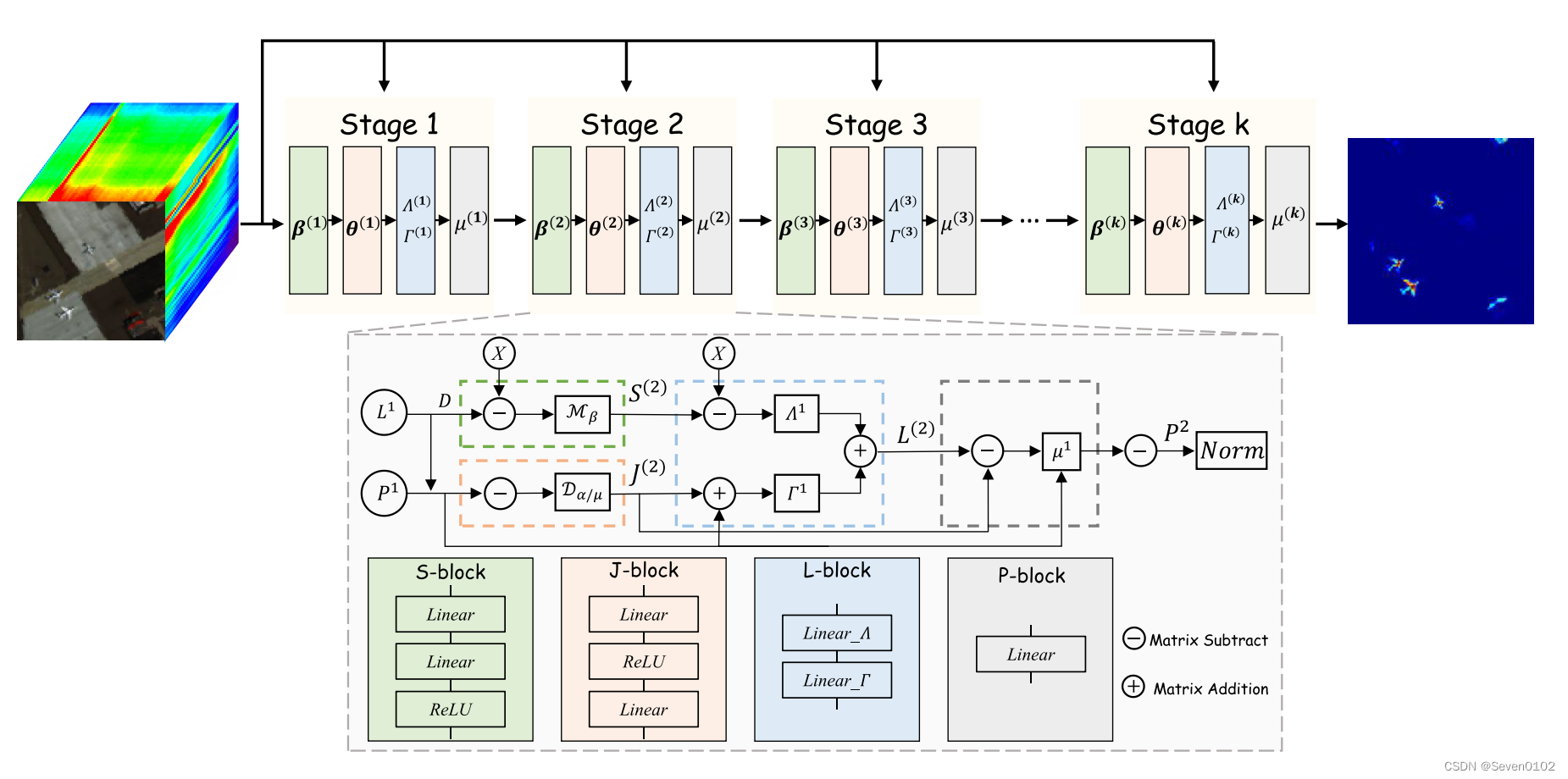
之后将所提出的模型求解过程转化为深度网络中不同的模块如下图所示:
分别对每一个块进行详细解释:


推测是作者笔误,应该是公式17可以写成:


 实际上,通过经验和实验发现,在相邻阶段之间进行的归一化操作在LRR-Net的优化和收敛中非常有用。好处是双重的。可以实现稳定的模型训练,从而避免展开网络训练过程中的梯度消失和爆炸。另一方面,加速了学习算法的收敛,倾向于找到更好的解决方案。
实际上,通过经验和实验发现,在相邻阶段之间进行的归一化操作在LRR-Net的优化和收敛中非常有用。好处是双重的。可以实现稳定的模型训练,从而避免展开网络训练过程中的梯度消失和爆炸。另一方面,加速了学习算法的收敛,倾向于找到更好的解决方案。
之后为什么这些参数就变成可学习的了?
















 5696
5696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









