




 该代码示例展示了如何使用Python的requests模块和正则表达式来抓取并解析豆瓣Top250电影列表的页面,包括电影名称、上映时间、评分和评价人数。通过设置伪装的User-Agent避免被网站屏蔽,并对响应文本设置UTF-8编码防止乱码。代码循环爬取1-10页的数据并打印出来。
该代码示例展示了如何使用Python的requests模块和正则表达式来抓取并解析豆瓣Top250电影列表的页面,包括电影名称、上映时间、评分和评价人数。通过设置伪装的User-Agent避免被网站屏蔽,并对响应文本设置UTF-8编码防止乱码。代码循环爬取1-10页的数据并打印出来。
1,拿到网页源代码
1.1 先看网址,和请求方式
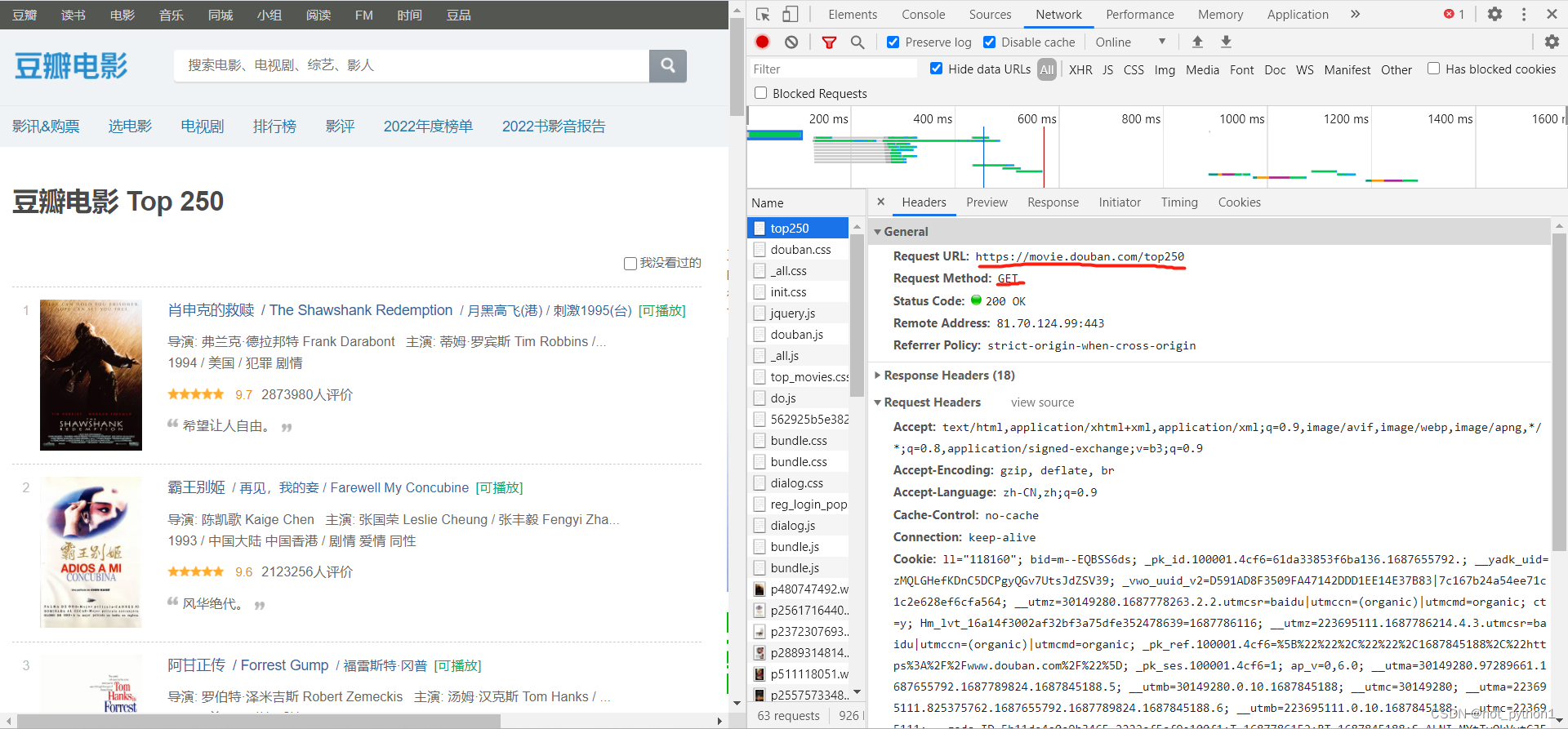
1.2导入requests模块
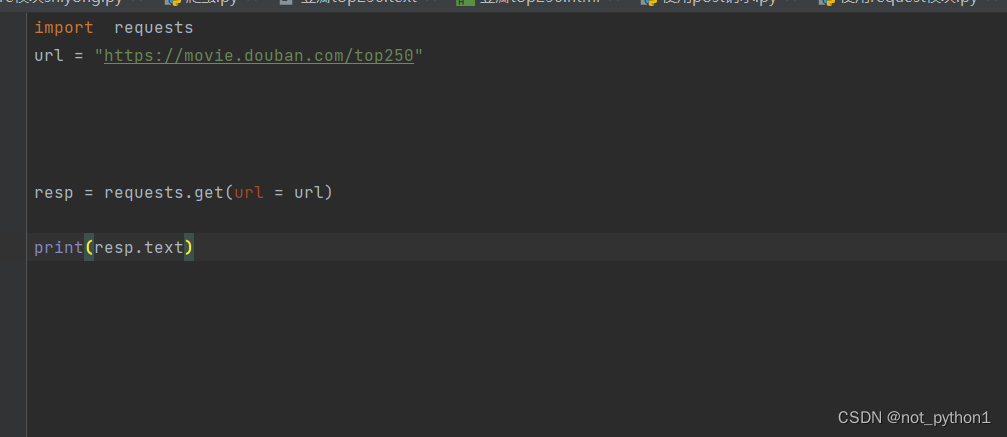
1.3 发现爬不出来,是因为豆瓣做了伪装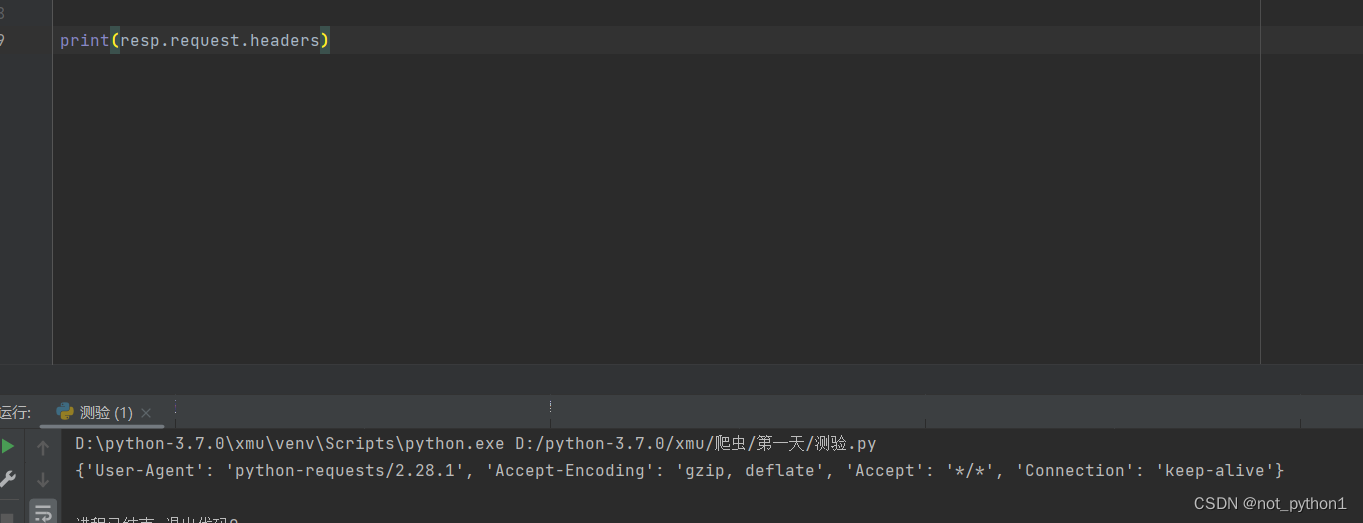
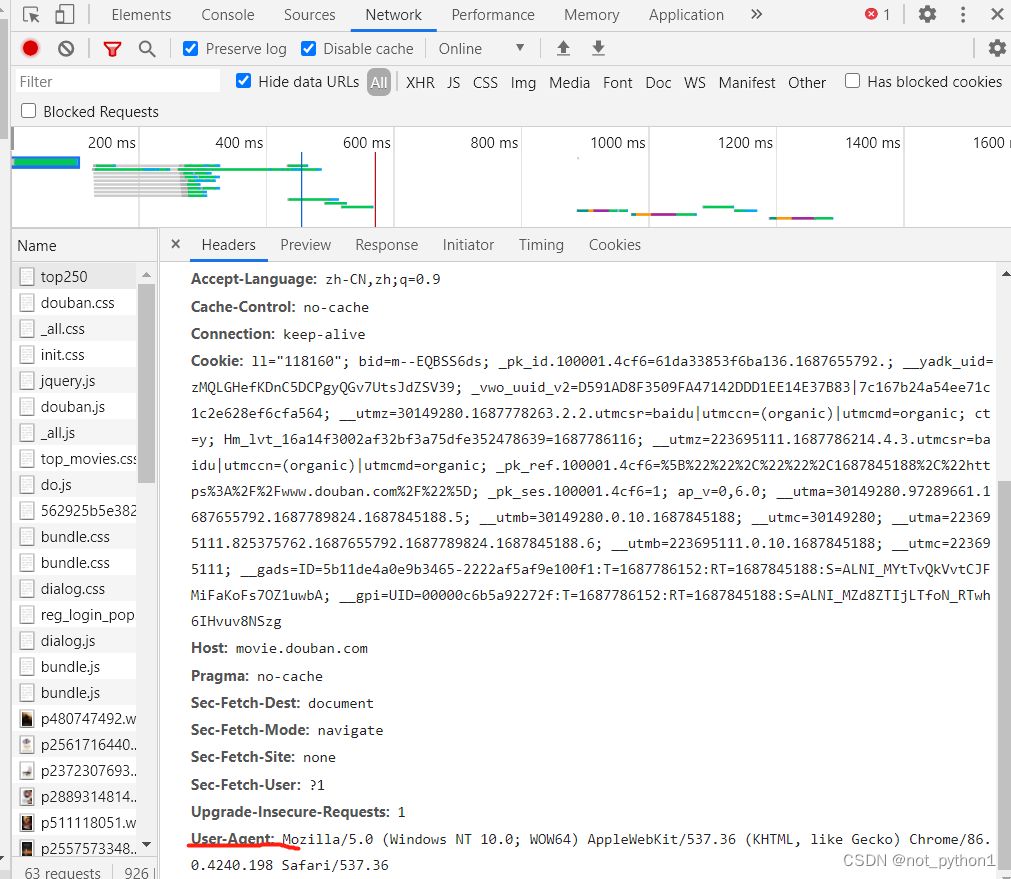
1.3需要更换头部

1.4需要设置utf-8,要不然会乱码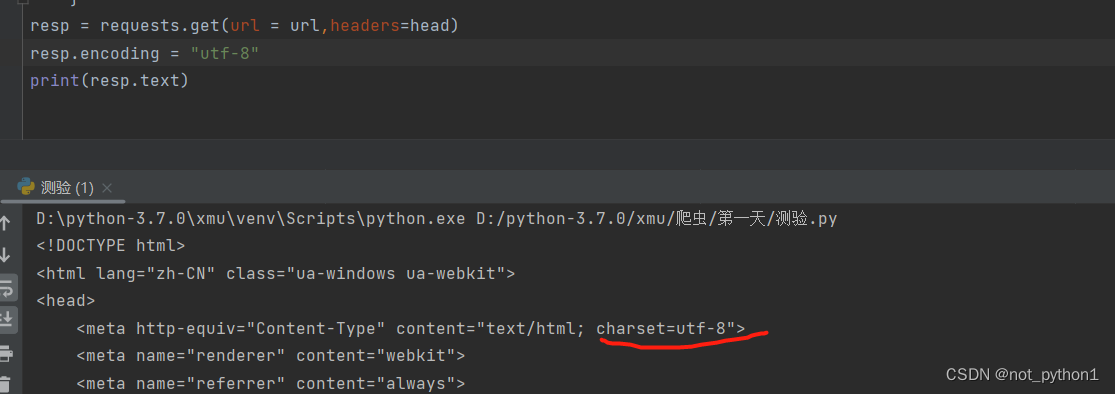 2,提取想要的数据
2,提取想要的数据
2.1,加载re模块,并且进行预加载

2.2,用正则法.*?

2.1,循环网页
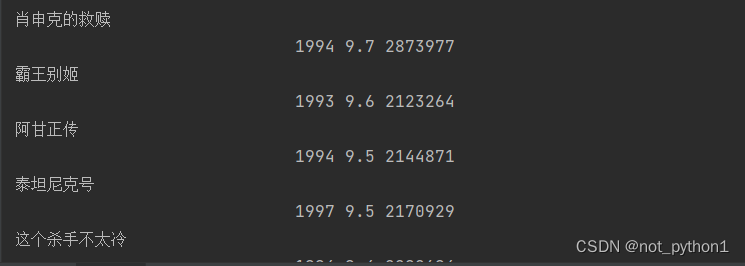
爬取1-10页面需要加循环
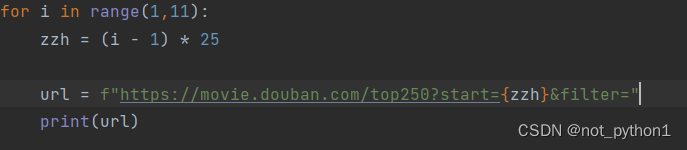

自己存储就行
下面是全部代码
import requests
import re
for i in range(1,11):
zzh = (i - 1) * 25
url = f"https://movie.douban.com/top250?start={zzh}&filter="
obj = re.compile(
r'<div class="item">.*?<span class="title">(?P<mz>.*?)</span>.*?<br>(?P<sj>.*?) .*?<span class="rating_num" property="v:average">(?P<pf>.*?)</span>.*?<span>(?P<pl>.*?)人评价</span>',
re.S)# re.S 让.跳过换行符
head = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
resp = requests.get(url, headers=head)
resp.encoding = "utf-8"
xx = obj.finditer(resp.text)
for itme in xx:
mz = itme.group("mz")
sj = itme.group("sj")
pf = itme.group("pf")
pl = itme.group("pl")
print(mz, sj, pf, pl)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









