







1. 使用 urllib.request 获取网页
urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 HTML 解析库, 可以编写出用于采集网络数据的大型爬虫;
注: 示例代码使用Python3编写; urllib 是 Python2 中 urllib 和 urllib2 两个库合并而来, Python2 中的 urllib2 对应 Python3中的 urllib.request
简单的示例:

2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝, 这时就需要将爬虫伪装成人类用户的浏览器, 这通常通过伪造请求头信息实现, 如:
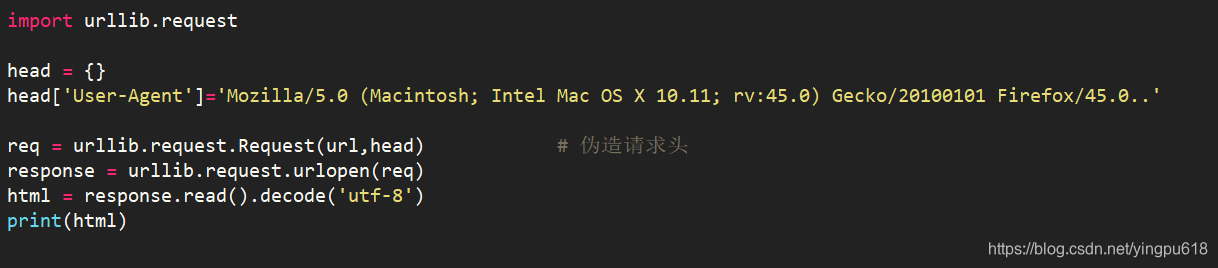
3. 伪造请求主体
在爬取某一些网站时, 需要向服务器 POST 数据, 这时就需要伪造请求主体;
为了实现有道词典在线翻译脚本, 在 Chrome 中打开开发工具, 在 Network 下找到方法为 POST 的请求, 观察数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5117
5117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









