






首先,submit一个job需要先创建一个执行程序和描述文件。
在ubuntu里,可以在自己的home文件夹下创建一个examples文件夹存放测试程序,然后sudo chmod -r 777 文件夹名,来给这个文件夹设置读写执行权限。
然后vi创建一个.sh文件作为执行程序。再vi创建一个.sub文件作为描述文件,sub文件里面需要定义.sh文件名,output文件名,log文件名,error文件名,这些文件都会自动生成在相同的文件夹里。sh文件用来描述sh程序
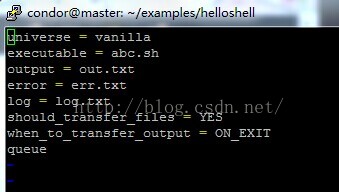
用condor_submit 程序名 来submit一个job,用condor_q和condor_status来查看任务状态。
可以用condor_prio 程序名来在队列中选择优先执行一个job
可以用condor_rm 程序名来在队列中选择删除一个job
管理员指南
一、一个machine可以扮演的角色
每个condor资源池里的机器可以扮演多种角色,某些角色只能由资源池里的一台机器来执行。
central manager:资源池里只能有一个中央manager。作为manager的机器是信息的collector,是资源与资源之间的negotiator(协商者)。这两个任务是由单独的daemon(守护进程)来完成的,所以可能有不同的机器来提供这些服务(意思是manager的机器不止一个?)。但通常情况下这两个任务存在在一个机器上(也就是说,一般manager只有一个)。一旦manager崩了,集群内便无法进一步匹配,但现存的机器还是能够正常运转,直到它们被参加匹配的其他机器所破坏。
execute:资源池里任何机器包括manager都可以被配置为是否执行condor job。成为一台执行机器并不需要太多资源,只需要必须的硬盘空间。
submit:资源池里任何机器包括manager都可以被配置为是否应该允许condor job的提交。用作提交的机器需要的资源比执行机器需要的多。
checkpoint server:检查点服务器机器的配置是可以选择的,并不是资源池里必须的部分。检查点服务器是用来储存job组的检查点文件的机器。
二、Daemons(守护进程)
condor_master:这个进程负责维持资源池中剩下的全部进程在每台机器上运作。它包含了其他的进程,并且会定期检查是否有新的二进制进程加入进来。如果有新的进程,那么condor_master会重启受影响的进程。如果有任何进程崩坏,那么condor_master会给管理者发送email并重启这个进程。condor-master也支持多种管理命令来让管理者远程开启、停止和重新配置进程。资源池中的每个机器都有condor_master运行,无论这个机器具有什么功能(也就是说,每个机器都要有master这个进程)。
condor_starter:这个进程用来在给定的机器上生成一个condor job。它设置了job的执行环境,并在job运行期间监视它。当job完成后,condor_starter会注意到,并向submit机器传回任何status信息,然后退出。
condor_schedd:这个进程用来表示资源池中资源的需求量。任何作为submit的机器都需要有一个运行的condor_schedd进程。(就是说,daemon中有submit就必须有schedd)。当用户submit了job,job会到condor_schedd里存在job队列里。condor_schedd管理这job队列。condor_schedd会广播队列中等待着的job数量,并负责声明满足这些请求的可用资源。一旦一个job和一个给定的资源相配对,condor-schedd就会生成一个condor_shadow进程来服务这个特定请求。
condor_shadow:这个进程会在机器上有请求被submit出的时候运行,并负责管理这些请求的资源。
condor_collector:这些资源负责收集资源池中的status信息。所有其他的进程都会定期向condor_collector发送ClassAd。这些ClassAd包含了所有进程的状态信息,以及它们表示的资源和资源请求。
condor_negotiator:这个进程负责condor系统内的所有任务匹配。condor_negotiator会定期开始一个协商周期,来向condor_status查询资源池中所有资源的目前状态。它会联系等待着的资源队列中排在前面的condor_schedd,并试着给这些请求匹配可用的资源。
其他还有一些daemon。。。。
三、安装condor
安装之前,要决定好资源池的基本布局。要回答9大问题:
1、哪个机器将作为central manager?
作为central manager的机器是condor资源池的集中式信息库,也用来在可用的机器和提交上的job间进行匹配。如果这台机器崩了,正在运行的其他机器还会运行,但不会有新的机器产生,另外,许多condor工具也会停止工作。
2、哪些机器能允许提交任务?
HTcondor会限制机器提交任务,但它能允许网络内任何允许的机器连接到submit的机器来提交任务。如果资源池在防火墙后面,而且所有防火墙内的的机器都是可信任的,那么ALLOW_WRITE配置条目可以设置为*/*。否则,这个条目应该被设置为资源池里能提交任务的机器。HTcondor的默认安全配置:ALLOW_WRITE条目是个无效的值,它不允许任何机器连接和提交任务。
3、condor是否要是用root权限运行?
用root用户开启condor进程。否则,condor做不了什么安全的抉择。你可以用任何用户安装condor,然而会有许多安全和性能的问题。强烈建议用root开启condor进程。不用root的话当安装的condor被许多用户在一个机器上共享时,或者机器被设置为只执行job时会出现问题。
4、谁来管理condor?
要么root直接管理condor,要么别的用户进行管理。当root把权限委派给用户时,要明白一旦用root启动condor后,有权编辑condor配置文档的人能够作为root用户来有效的运行任何程序。管理者要按照指示经常的更新condor,安装condor,为submit和execute节点定制策略。这个人也会在资源池出错时收到信息,当CONDOR_ADMIN的配置有效的时候。
5、你有以condor命名的用户,以及相应的home文件夹吗?
为了简化condor的安装,要在资源池中的所有机器中创建一个以condor命名的用户。condor进程会创建由这个用户拥有的一些文件(如log文件),home文件夹可以用来明确这些condor需要的文件和文件夹的位置。home文件夹既可以在所有机器中共享,也可以在每台机器上独享。要注意这个用户不能让人能够登录进去。如果有人登录了condor用户,它便会允许一个重大的安全漏洞,那就是condor用户能够提交和其他用户一样的任务,能够通过任务访问别的用户的数据。一个禁止登录此账户的标准做法是在密码文件中输入无效的shell命令。
如果你没有新建一个condor用户,那你必须通过CONDOR_IDS环境变量或CONDOR_IDS配置文件的设置来明确哪个uid.gid对可以用来拥有各种condor文件。
6、用于condor特定机器的文件目录应该放在哪?
condor需要资源池中每个机器有一些特定的文件目录。那就是spool,log和execute。这三个都是每个机器特定目录的子目录,称为本地目录(由配置文件中的LOCAL_DIR宏来指定)。每个目录都应该被condor使用者拥有。不要在这些目录有放别的文件,任何在这里面不是condor产生的文件都要被清除。如果你有一个condor命名的用户,那么LOCAL_DIR应该是condor的home目录(配置文件:LOCAL_DIR=$~)。如果用户的home目录被所有机器共享,那么你要给每个host创建一个local目录(如,LOCAL_DIR=$~/hosts/$(HOSTNAME))。
7、condor系统的部分应该安装在哪里?
condor系统部分:配置文件,发行目录:用户二进制文件、系统二进制文件、lib目录、etc目录,文档
配置文件:可能不止一个配置文件。它们在不同程度的控制资源池中的每个机器的配置。global配置文件由所有机器共享。为了便于管理,这个文件应该位于共享文件系统。本地配置文件重写了global文件的设置,它允许不同的进程运行,不同的策略来决定什么时候开始和停止condor任务等等。
发行目录:有五个子目录:bin,etc,lib,sbin,libexec。不管你把这五个目录装在哪我们都叫做发行目录(在配置文件中的宏RELEASE_DIR来指定)。为便于管理,建议把这些目录安装在共享文件系统。
user binnaries:一般放在/usr/local/condor/bin里,或者在/usr/local/bin里建一个超链接指向/usr/local/condor/bin。
system binaries:把这些sbin中的程序添加到condor管理者的路径中。
private HTcondor binaries:所有libexec目录中的文件是condor程序,不能被手动运行,只能在condor内部运行。
lib目录:lib目录中的文件是condor的二进制文件,它们应该放在全局可读的位置,但不需要放在任何用户的路径中。condor_compile程序检查lib目录位置的配置文件。
etc目录:etc目录包含了有着文件配置例子的examples子文件夹,以及其他用来安装condor的文件。应该把etc文件夹放在保存有配置文件主副本的位置(也就是说,配置时要先复制一份原始配置文件再更改)。
文档:它可以放在你习惯的任何位置。
7、我是否使用AFS(分布式文件系统)?
condor目前还不能自动认证为AFS。
8、我是否有足够的用于condor的硬盘空间?
ubuntu系统的安装步骤
perl脚本程序condor_configure用来安装condor。该脚本的命令行参数明确了所有需要的信息。这个脚本可以执行多次。
使用者指南
HTCondor是专门用来管理计算密集型任务的批处理系统。和大多数批处理系统相同,HTCondor提供了一个排队机制、调度策略、优先计划以及资源分类。使用者把他们的计算任务提交给HTCondor,HTCondor把任务放在一个队列里,运行它们,然后把结果报告给使用者。
用ClassAds进行匹配
在学习如何提交任务之前,理解HTCondor如何分配资源是十分重要的。全面理解HTCondor的调度算法的关键在于理解HTCondor用机器提交任务的独特结构。HTCondor通过ClassAds进行牵线搭桥从而简化任务提交过程。ClassAds类似于报纸上不同分类的广告。销售者广告说明他们具体卖什么,希望能吸引买家。购买者广告说明他们想要买什么。卖家和买家都要列出一些他们必须满足的约束条件。例如,买家有最大消费限额,卖家有最小购买价格。而且双方都希望能把他们的优势排在前面。在HTCondor中,使用者提交任务就像买家购买计算资源,而机器的所有者则是卖家。所有HTCondor池中的机器都能广播它们的属性,如可用存储、cpu类型和速度、虚拟内存大小、电流平均负载,以及其他静态和动态特性。这种机器的ClassAd也会广播在什么条件下它希望运行任务和运行哪种类型的任务。你可以广播你的机器只想在夜里运行任务,而且那时不会有键盘活动。你可以广播运行任务的排序。同样的,当你提交一个任务,你可以用ClassAd来明确你的需要和偏好。ClassAd包括你想使用的机器类型。比如,你可能会寻找可用的最快浮点性能机器。你想要HTCondor基于浮点性能排列出可用的机器。或者,可能你只在乎有128M最小RAM的机器。或者,你想要任何可用机器!这些任务属性和需求被捆绑成了一个job ClassAd。HTCondor扮演着月老的角色,它持续不断的读取所有任务的ClassAds和机器的ClassAds,并把它们进行匹配。HTCondor确保双方的ClassAds都能得到满足。
用condor_status来检查机器的ClassAds
一旦HTCondor被安装,你便能通过condor_status命令来体会一个机器的ClassAds在做什么。试着用condor_status来得到关于你的资源池中可用资源的ClassAds的信息总结。condor_status有一些用不同方法总结机器ads的option。如:
condor_status -avaiable 只显示现在希望执行任务的机器
condor_status -run 只显示现在正运行任务的机器
condor_status -long 列出资源池中所有机器的ads
执行一个任务要采取的步骤:
编写代码。在condor环境下运行任务必须能够在一个批处理作业的后台来运行。HTCondor是在无人监守和在后台执行程序的。一个在后台运行的程序,是无法进行交互的输入输出的。HTCondor可以通过程序文件重定向控制台输出(stdout和stderr)和键盘输入(stdin)。创建任何需要的包含了输入程序需要的正确按键的文件。确保程序能够根据文件来正确运行。
HTCondor环境。HTCondor有许多可选的运行期间的环境(称为universe),有两个是提交任务的可能选择:标准universe(standard)和普通universe(vanilla)。standard允许一个作业在condor环境下运行通过返回给提交作业的机器来处理系统。standard环境也提供了提取检查点以及应该在该机器上执行作业期间不可用时移除部分完成的作业的必要机制。要使用standard环境,必须用condor_compile命令重链接程序。vanilla环境提供了任务不能被重链接的方法。在vanilla环境下无法提取检查点和移除执行过的作业。为了读取输入和输出文件,作业必须要么用共享文件系统,要么用HTCondor的文件转换机制(File Tranfer mechanism)。
提交描述文件。提交的描述文件是用来控制作业提交的细节。文件包含了作业的信息诸如运行什么可执行程序、替代stdin和stdout的文件、需要运行程序的平台类型。可以包括运行程序的次数;用多数据集运行多次相同程序是很简单的。
提交作业。用condor_submit命令来提交程序。一旦提交,condor来做剩下的执行作业的工作。用condor_q和condor_status来监控作业的进程。你可以用condor_prio命令来修改执行作业的顺序。condor可以根据所需来在log文件里通知你每次作业被检查和被迁移到不同机器上的情况。当你的程序完成后,condor会告诉你的程序的退出状态以及它的执行情况的各种统计数据,包括使用的次数和I/O性能。你可以使用condor_rm命令从队列里提前移除作业。
选择condor环境
condor8.4.3支持许多不同的环境:standard,vanilla,grid,java,scheduler,local,parallel,vm,docker。universe是在描述文件里被明确的。如果没有指出universe,默认是vanilla。standard环境提供了迁移和可靠性,但有些运行程序的限制。vanilla提供更少的服务,但有更少的限制。grid允许使用者用condor接口来提交作业,这些作业是为了用网格资源来执行。java允许使用者运行用java虚拟机(JVM)编写的作业。scheduler允许使用者提交由submit节点自身进程产生的轻型作业。parallel是针对一个作业需要许多机器的情况。vm允许使用者在没有了简单的执行程序而是在一个硬盘映像下通过虚拟机执行作业。
standard universe
在standard环境中,condor提供检查点和远程系统调用。这些特征使作业更可靠并允许它统一访问池中的任何资源机器。要使用standard环境编写程序,必须用condor_compile来重链接。在你普通的链接命令前插入condor_compile。你不需要修改程序的源代码,但你必须进入未链接的目标文件。一个被打包为单一的可执行文件的商业项目不能被转换为一个standard环境作业。
例如,如果你已经这样链接了作业:
%cc main.o tools.o -o program
那么,用以下命令重链接作业:
%condor_compile cc main.o tools.o -o program
condor会定期检查作业。checkpoint image是一个作业的目前状况的必须的snapshot。如果一个作业从一个机器被迁移到另一个,condor会制作checkpoint image,复制这些image到新的机器,并重启作业来进行它剩下的部分。如果在运行期间作业崩溃或失败,condor会使用最近的checkpoint image来在新的机器上重启作业。用这种方法,作业可以运行数月或数年即使面临偶然的计算机崩溃情况。
远程系统调用使一个作业感觉是在它的主机器上执行,即使这个作业可能在许多不同的机器上执行过。当一个作业在远程机器上执行时,一个次级程序,称为condor_shadow,会在提交作业的机器上运行。当这个作业试图调用condor系统,condor_shadow会替代这个调用并把结果发送给远程机器。例如,如果一个作业试图打开提交机器上存储的文件,condor_shadow会找到这个文件并把数据发送给作业运行的机器。
在standard环境下执行作业有一些限制条件:
1.多进程作业不被允许。这包括调用如fork(),exec(),system()等系统。
2.进程间通信不被允许。这包括管道、信号灯和共享存储。
3.网络通信必须简洁。一个作业可以调用如socket()的系统进行网络连接,但网络连接持续太长时间会阻止检查点和迁移。
4.发送或接受SIGUSR2或SIGTSTP信号不被允许。condor只为自身的使用而存储这些信号。发送或接受其他所有的信号是可以的。
5.警报、计时器和睡眠是不被允许的。这包括调用alarm(),getitimer(),sleep()。
6.多内核级线程不被允许。然而,多用户级线程是可以的。
7.内存映射文件不被允许。这包括调用mmap(),munmap()。
8.可以使用文件锁,但检查点间不能使用。
9.所有文件必须以只读或只写方式打开。如果既读又写将出现问题如果一个作业必须被恢复到老的检查点映像。出于兼容性的问题,一个文件以同时读写的方式打开会产生警告而不是错误。
10.在提交作业的机器上必须有一定的硬盘空间,因为要存储检查点映像。一个检查点映像大约等同于一个作业运行期间消耗的虚拟内存。如果硬盘空间很小,一个特殊的检查点服务器会用来储存资源池中的左右检查点映像。
11、Linux系统下,作业必须是静态链接的。condor_compile会默认这样做。
12.读或写大于2G的文件只支持提交方的condor_shadow和standard环境使用者的作业请求自身都是64位执行程序的情况。
vanilla universe
vanilla环境用于不能成功重链接的程序。shell脚本是可用vanilla的另一种情况。然而,在vanilla环境中运行作业不能检查或使用远程调用。当远程机器执行作业期间必须被返回到它的所有者时,作业被部分完成,这时condor只有两个选择。它可以暂停该作业,希望之后再完成它,或者可以放弃并从头或从资源池中别的机器上重启该作业。因为condor的远程调用特征在vanilla环境下无法使用,读取作业的input和output文件便成了问题。一个选择是让condor使用共享文件系统,如NFS或AFS。或者,condor有一个代表使用者传输文件的机制。在这种情况下,condor将把任何作业需要的文件传输到执行机器,运行该作业,并把输出传输回提交机器。在Unix系统下,condor假定了vanilla作业有一个共享文件系统。然而,如果没有可用的共享文件系统,使用者可以启用condor的文件传输机制。Windows平台上,默认设置是使用文件传输机制。
提交一个作业
condor_submit把提交描述文件的文件名作为参数。这个文件包含了指挥作业队列的命令的关键字。在提交描述文件中,condor会寻找所有它需要知道的关于作业的信息。例如执行程序的名字,初始工作目录,程序的命令行参数都要放在提交描述文件中。condor_submit基于这些信息创建一个作业的ClassAd,然后condor根据这个来运行作业。提交描述文件的内容是为节省使用者的时间而设计的。通过单一的提交描述文件便能很容易的提交多次运行的程序。为在不同的输入数据集上执行多次相同程序,要相应的安排数据文件以使每次运行都读取自己的输入并写出自己的输出。每次独立的运行可能有自己的初始工作目录,stdin,stdout和stderr的文件映射,命令行参数,以及shell环境;这都在提交描述文件中确定。一个直接打开它的文件的程序将读取要么来自stdin要么自来命令行的文件名。一个打开由给出文件名的静态文件的程序,每次都需要使用单独的子目录作为每次运行的输出。
描述性文件的编写
默认的universe是vanilla。默认平台是和提交作业的机器的操作系统相同。Input = inputfile,Output = outputfile明确了输入输出文件。当作业被提交后,condor希望能再当前工作目录中找到这些文件。当不明确input,output,error文件时,默认为/dev/null里的stdin,stdout,stderr。
例子:在一个队列里执行run_1和run_2两个相同的作业。
executable = mathematica
universe = vanilla
input = test.data
output = loop.out
error = loop.error
log = loop.log
request_memory = 1 GB
initialdir = run_1
queue
initialdir = run_2
queue
例子:在带有32位英特尔处理器的Linux系统上运行150次foo程序。
####################
#
# Example 4: Show off some fancy features including
# the use of pre-defined macros.
#
####################
Executable = foo
Universe = standard
requirements = OpSys == "LINUX" && Arch =="INTEL"
rank = Memory >= 64
image_size = 28000
request_memory = 32
error = err.$(Process)
input = in.$(Process)
output = out.$(Process)
log = foo.log
queue 150
说明:rank命令表达了想在大于64M的机器上运行每次程序的偏好。image_size命令说明了standard环境下的作业在运行期间将使用高达28000KB的内存。这150次运行的程序每一次都有自己的程序编号,由number0开始。相应的,输入输出错误文件由in.0,out.0,err.0到in.1,out.1,err.1到以后。一个独立的log文件包含了这所有150个排好队的程序何时在哪个机器上运行,检查点,迁移过程的所有信息。
使用队列命令的功能和灵活性。
各式各样作业的提交可以通过一个额外的queue提交命令来明确。这种灵活性能够避免在提交许多作业时要使用工作包或者perl脚本。queue命令的形式定义了变量和扩展值,并确定一组作业。方括号用来识别option项。
例子:当输入和参数是(file1,-a -b 26)和(file2,-c -d 92)时进行排队
input = file1
arguments = -a -b 26
queue
input = file2
arguments = -c -d 92
queue
提交描述文件中的变量
提交描述文件中使用的自动变量有:
$(Cluster) or $(ClusterId) 每个提交自一个提交节点,来自特定用户的队列作业集,都共享一个有着相同的$(Cluster) or $(ClusterId) 值的可执行程序。作业集的第一个cluster是cluster0,每有一个新的作业cluster值便加一。$(Cluster) or $(ClusterId)和作业的ClassAd的ClusterId属性有着相同的值。
$(Process) or $(ProcId) 在一个作业的集群内,每个作业都有自己的$(Process) or $(ProcId)值。第一个作业的值是0.$(Process) or $(ProcId),和作业ClassAd的ProcId属性相同。
$(Item) 当queue命令中没有提供<varname>时的默认变量名
$(ItemIndex) 表示项目列表中的索引。
$(Step)
$(Row)
例子:执行6个作业的队列,3个执行A ,3个执行B
• $(Process) takes on the six values 0, 1, 2, 3, 4, and 5.
• Because there is no specification for the <varname> within this queue command, variable $(Item) is defined.
It has the value A for the first three jobs queued, and it has the value B for the second three jobs queued.
• $(Step) takes on the three values 0, 1, and 2 for the three jobs with $(Item)=A, and it takes on the same
three values 0, 1, and 2 for the three jobs with $(Item)=B.
• $(ItemIndex) is 0 for all three jobs with $(Item)=A, and it is 1 for all three jobs with $(Item)=B.
• $(Row) has the same value as $(ItemIndex) for this example.
include命令
外部定义的提交命令可以被合并到提交描述文件中,通过使用语法
include:<what-to-include>
<what-to-include>可以指定一个文件或一个执行程序。<what-to-include>的规范是执行程序名后要有字符 |
include关键字不区分大小写。在冒号后面不要求有空格字符。















 3405
3405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









