数据集
- scikit-learn内部集成的手写体数字图片数据集
代码
"""
手写数字分类
模型:
LinearSVC (线性支持向量机)
"""
from sklearn.datasets import load_digits
digits = load_digits()
print(digits.data.shape)
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.25, random_state=33)
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
lsvc = LinearSVC()
lsvc.fit(X_train, y_train)
y_predict = lsvc.predict(X_test)
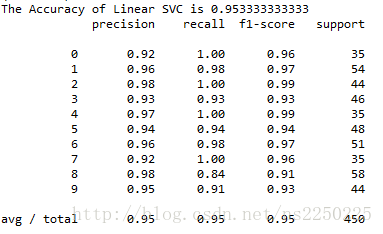
print('The Accuracy of Linear SVC is', lsvc.score(X_test, y_test))
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict, target_names=digits.target_names.astype(str)))
效果























 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









