






OpenAI-o1 的首次总结
在阅读了 OpenAI 的出版物后,我对其本质特点进行了总结,并得出了以下结论:
1. 复杂问题的推理能力显著提升:OpenAI-o1 在处理复杂问题时表现出色,尤其在逻辑任务方面。
2. 定期更新和改进:通过不断的训练,模型学会完善自己的思维过程,尝试不同的策略,并识别和纠正自己的错误。
3. 高水平的学术挑战能力:在物理、化学和生物学等方面,OpenAI-o1 能够应对具有挑战性的基准任务,表现类似于博士生。
4. 数学和编程能力强:在国际数学奥林匹克(IMO)中取得了83%的成绩,显示出卓越的数学和编码能力。
5. 重新命名与重置:OpenAI 将计数器重置为1,并将这一系列命名为 OpenAI-o1,不再使用 ChatGPT 这个名称,标志着模型的新开端。
6. 越狱防护能力强:模型在防止越狱方面开发得非常好。
7. 与当局密切合作:增强了安全工作、内部治理和与联邦政府的合作。
8. 思想链 (CoT) 的使用:通过更多的强化学习和思考时间,OpenAI-o1 的性能持续提高。

以下是OpenAI官方的重要信息
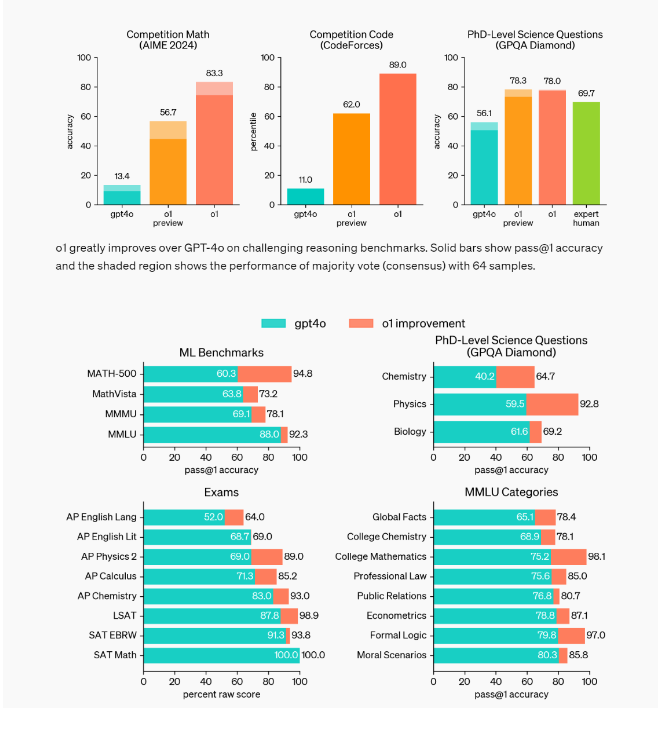
OpenAI 确实做到了。以下是基准测试结果的总结:
OpenAI-o1 表现出色,尤其是在逻辑任务和传统 LLM 达到极限的领域。通过使用思想链 (CoT) 和自学习,该模型能够通过不断的自我修正取得出色的结果。与 ChatGPT-4o 相比,基准测试显示出巨大的飞跃,这不仅是一个小进步,而是一个里程碑。
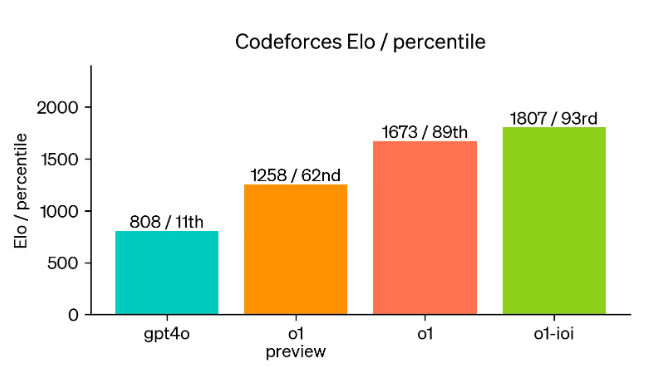
我们实际上有一个模型,已经达到了 STEM 学科博士专家的水平。在编程奥林匹克竞赛中,它达到了史无前例的 ELO 1807,并且也达到了 93 个百分点:
“我们模拟了 Codeforces 主办的编程竞赛,以展示该模型的编码技能。我们的评估与竞赛规则非常匹配,并允许提交 10 份作品。GPT-4o 的 Elo 评级为 808,位于人类竞争对手的第 11 个百分点,而 OpenAI-o1 获得了 1807 的 Elo 评级,表现优于 93% 的竞争对手。”
这些模型不断改进和发展。按照这个速度,我们可以假设到 2025 年可能会真正实现 AGI。虽然不是每个人都可以使用,但作为应用程序可能是可行的。对经济和工作领域的影响是不可预见的。
“OpenAI-o1 显著提升了人工智能推理的最先进水平。我们计划在继续迭代的过程中发布该模型的改进版本。我们预计这些新的推理能力将提高我们将模型与人类价值观和原则结合起来的能力。我们相信 OpenAI-o1 及其后继者将开启人工智能的许多新用例。在科学、编码、数学和相关领域,我们很高兴用户和 API 开发人员发现它如何改善他们的日常工作。”
我们还在 GPQA Diamond 上评估了 OpenAI-o1。为了将模型与人类进行比较,我们招募了具有博士学位的专家来回答 GPQA 钻石问题,发现 OpenAI-o1 的表现超过了这些人类专家,成为第一个在该基准上这样做的模型。这并不意味着 OpenAI-o1 在各方面都比博士更有能力,但它在一些预期博士学位可以解决的问题上表现更好。
在其他几个 ML 基准测试中,OpenAI-o1 比最先进的水平有所改进。启用视觉感知能力后,OpenAI-o1 在 MMMU 上得分为 78.2%,成为第一个与人类专家竞争的模型。它还在 57 个 MMLU 子类别中的 54 个上优于 GPT-4o。

同样重要的是,OpenAI 直接发布了 OpenAI-o1 的迷你版本,价格便宜约 80%,但仍然明显优于 GPT-4o,而且仅比普通的 OpenAI-o1 稍差一点。这不应该被低估,因为这意味着这个出色的模型可以以低成本在任何地方使用。
“OpenAI-o1-mini 是一种经济高效的推理模型,擅长 STEM,尤其是数学和编码,在 AIME 和 Codeforces 等评估基准上几乎与 OpenAI-o1 的性能相匹配。今天,我们向第 5 层 API 用户推出 OpenAI-o1-mini,价格比 OpenAI-o1-preview 便宜 80%。”

我认为 OpenAI-o1 的推出标志着一个全新时代的开始。数字不会说谎,OpenAI-o1 已经证明了它的卓越表现。它将改变世界。OpenAI 已经交付,我们值得庆祝这一历史性的时刻。















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









