









ES提供的各种搜索辅助功能。例如,为优化搜索性能,需要指定搜索结果返回一部分字段内容。为了更好地呈现结果,需要用到结果计数和分页功能;当遇到性能瓶颈时,需要剖析搜索各个环节的耗时;面对不符合预期的搜索结果时,需要分析各个文档的评分细节。
指定返回的字段
考虑到性能问题,需要对搜索结果进行“瘦身”——指定返回的字段。在ES中,通过_source子句可以设定返回结果的字段。_source指向一个JSON数组,数组中的元素是希望返回的字段名称。
PUT /hotel
{
"mappings": {
"properties": {
"title":{"type": "text"},
"city":{"type": "keyword"},
"price":{"type": "double"},
"create_time":{"type": "date","format": "yyyy-MM-dd HH:mm:ss"},
"attachment":{"type": "text"},
"full_room":{"type": "boolean"},
"location":{"type": "geo_point"},
"praise":{"type": "integer"}
}
}
}向hotel新增数据:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title":"java旅馆","city":"深圳","price":50.00,"create_time":"2022-08-05 00:00:00","location":{"lat":40.012312,"lon":116.497122},"praise":10}
{"index":{"_index":"hotel","_id":"002"}}
{"title":"python旅馆","city":"北京","price":50.00,"create_time":"2022-08-05 00:00:00","location":{"lat":40.012312,"lon":116.497122},"praise":10}
{"index":{"_index":"hotel","_id":"003"}}
{"title":"go旅馆","city":"上海","price":50.00,"create_time":"2022-08-05 00:00:00","location":{"lat":40.012312,"lon":116.497122},"praise":10}
{"index":{"_index":"hotel","_id":"004"}}
{"title":"C++旅馆","city":"广州","price":50.00,"create_time":"2022-08-05 00:00:00","location":{"lat":40.012312,"lon":116.497122},"praise":10}下面的DSL指定搜索结果只返回title和city字段:
POST /hotel/_search
{
"_source": ["title","city"],
"query": {
"term": {
"city": {
"value": "深圳"
}
}
}
}返回结果:
{
"took" : 361,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2039728,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.2039728,
"_source" : {
"city" : "深圳",
"title" : "java旅馆"
}
}
]
}
}在上述搜索结果中,每个命中文档的_source结构体中只包含指定的city和title两个字段的数据。
在Java客户端中,通过调用searchSourceBuilder.fetchSource()方法可以设定搜索返回的字段,该方法接收两个参数,即需要的字段数组和不需要的字段数组。以下代码片段将和上面的DSL呈现相同的效果:
@Test
public void testQueryNeedFields() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(Arrays.stream("127.0.0.1:9200".split(","))
.map(host->{
String[] split = host.split(":");
String hostName = split[0];
int port = Integer.parseInt(split[1]);
return new HttpHost(hostName,port,HttpHost.DEFAULT_SCHEME_NAME);
}).filter(Objects::nonNull).toArray(HttpHost[]::new)));
SearchRequest request = new SearchRequest("hotel");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new TermQueryBuilder("city","深圳"));
sourceBuilder.fetchSource(new String[]{"title","city"},null);
request.source(sourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
System.out.println(search.getHits());
}结果计数
为提升搜索体验,需要给前端传递搜索匹配结果的文档条数,即需要对搜索结果进行计数。针对这个要求,ES提供了_count API功能,在该API中,用户提供query子句用于结果匹配,ES会返回匹配的文档条数。下面的DSL将返回城市为“北京”的旅馆个数:
POST /hotel/_count
{
"query": {
"term": {
"city": {
"value": "北京"
}
}
}
}执行上述DSL后,返回信息如下:
{
"count" : 1,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}由结果可知,ES不仅返回了匹配的文档数量(值为1),并且还返回了和分片相关的元数据,如总共扫描的分片个数,以及成功、失败、跳过的分片个数等。
在Java客户端中,通过CountRequest执行_count API,然后调用CountRequest对象的source()方法设置查询逻辑。countRequest.source()方法返回CountResponse对象,通过countResponse.getCount()方法可以得到匹配的文档条数。以下代码将和上面的DSL呈现相同的效果:
@Test
public void testCount() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(Arrays.stream("127.0.0.1:9200".split(","))
.map(host->{
String[] split = host.split(":");
String hostName = split[0];
int port = Integer.parseInt(split[1]);
return new HttpHost(hostName,port,HttpHost.DEFAULT_SCHEME_NAME);
}).filter(Objects::nonNull).toArray(HttpHost[]::new)));
CountRequest countRequest = new CountRequest("hotel");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(new TermQueryBuilder("city","深圳"));
countRequest.source(sourceBuilder);
CountResponse response = client.count(countRequest,RequestOptions.DEFAULT);
System.out.println(response.getCount());
}结果分页
在实际的搜索应用中,分页是必不可少的功能。在默认情况下,ES返回前10个搜索匹配的文档。用户可以通过设置from和size来定义搜索位置和每页显示的文档数量,from表示查询结果的起始下标,默认值为0,size表示从起始下标开始返回的文档个数,默认值为10。下面的DSL将返回下标从0开始的20个结果。
GET /hotel/_search
{
"from":0, //设置搜索起始位置
"size": 2,//设置搜索返回的文档个数
"query": {
"term": {
"city": {
"value": "深圳"
}
}
}
}在默认情况下,用户最多可以取得10 000个文档,即from为0时,size参数最大为10 000,如果请求超过该值,ES返回如下报错信息:
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "hotel",
"node" : "tiANekxXS_GtirH4DamrFA",
"reason" : {
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
],
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
},
"status" : 400
}对于普通的搜索应用来说,size设为10 000已经足够用了。如果确实需要返回多于10 000条的数据,可以适当修改max_result_window的值。以下示例将hotel索引的最大窗口值修改为了20 000。
PUT /hotel/_settings
{
"index":{
"max_result_window":20000
}
}注意,如果将配置修改得很大,一定要有足够强大的硬件作为支撑。
作为一个分布式搜索引擎,一个ES索引的数据分布在多个分片中,而这些分片又分配在不同的节点上。一个带有分页的搜索请求往往会跨越多个分片,每个分片必须在内存中构建一个长度为from+size的、按照得分排序的有序队列,用以存储命中的文档。然后这些分片对应的队列数据都会传递给协调节点,协调节点将各个队列的数据进行汇总,需要提供一个长度为number_of_shards*(from+size)的队列用以进行全局排序,然后再按照用户的请求从from位置开始查找,找到size个文档后进行返回。
基于上述原理,ES不适合深翻页。什么是深翻页呢?简而言之就是请求的from值很大。假设在一个3个分片的索引中进行搜索请求,参数from和size的值分别为1000和10,其响应过程如下图所示。

当深翻页的请求过多时会增加各个分片所在节点的内存和CPU消耗。尤其是协调节点,随着页码的增加和并发请求的增多,该节点需要对这些请求涉及的分片数据进行汇总和排序,过多的数据会导致协调节点资源耗尽而停止服务。
作为搜索引擎,ES更适合的场景是对数据进行搜索,而不是进行大规模的数据遍历。一般情况下,只需要返回前1000条数据即可,没有必要取到10 000条数据。如果确实有大规模数据遍历的需求,可以参考使用scroll模式或者考虑使用其他的存储引擎。
在Java客户端中,可以调用SearchSourceBuilder的from()和size()方法来设定from和size参数。以下代码片段将from和size的值分别设置为20和10。
@Test
public void testQueryByPage() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(Arrays.stream("127.0.0.1:9200".split(","))
.map(host->{
String[] split = host.split(":");
String hostName = split[0];
int port = Integer.parseInt(split[1]);
return new HttpHost(hostName,port,HttpHost.DEFAULT_SCHEME_NAME);
}).filter(Objects::nonNull).toArray(HttpHost[]::new)));
SearchRequest request = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(new TermQueryBuilder("city","深圳"));
searchSourceBuilder.from(20);
searchSourceBuilder.size(10);
request.source(searchSourceBuilder);
client.search(request,RequestOptions.DEFAULT);
}性能分析
在使用ES的过程中,有的搜索请求的响应可能比较慢,其中大部分的原因是DSL的执行逻辑有问题。ES提供了profile功能,该功能详细地列出了搜索时每一个步骤的耗时,可以帮助用户对DSL的性能进行剖析。开启profile功能只需要在一个正常的搜索请求的DSL中添加"profile":"true"即可。以下查询将开启profile功能:
GET /hotel/_search
{
"profile": true,
"query": {
"match": {
"title": "北京"
}
}
}执行以上DSL后ES返回了一段比较冗长的信息:
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"profile" : {
"shards" : [
{
"id" : "[tiANekxXS_GtirH4DamrFA][hotel][0]",
"searches" : [
{
"query" : [
{
"type" : "BooleanQuery",
"description" : "title:北 title:京",
"time_in_nanos" : 1032417,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 0,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 0,
"advance_count" : 0,
"score" : 0,
"build_scorer_count" : 1,
"create_weight" : 1023459,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 8958
},
"children" : [
{
"type" : "TermQuery",
"description" : "title:北",
"time_in_nanos" : 182334,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 0,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 0,
"advance_count" : 0,
"score" : 0,
"build_scorer_count" : 1,
"create_weight" : 179167,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 3167
}
},
{
"type" : "TermQuery",
"description" : "title:京",
"time_in_nanos" : 15167,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 0,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 0,
"advance_count" : 0,
"score" : 0,
"build_scorer_count" : 1,
"create_weight" : 14792,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 375
}
}
]
}
],
"rewrite_time" : 183625,
"collector" : [
{
"name" : "SimpleTopScoreDocCollector",
"reason" : "search_top_hits",
"time_in_nanos" : 32000
}
]
}
],
"aggregations" : [ ]
}
]
}
}如上所示,在带有profile的返回信息中,除了包含搜索结果外,还包含profile子句,在该子句中展示了搜索过程中各个环节的名称及耗时情况。需要注意的是,使用profile功能是有资源损耗的,建议用户只在前期调试的时候使用该功能,在生产中不要开启profile功能。
因为一个搜索可能会跨越多个分片,所以使用shards数组放在profile子句中。每个shard子句中包含3个元素,分别是id、searches和aggregations。
- id表示分片的唯一标识,它的组成形式为[nodeID][indexName][shardID]。
- searches以数组的形式存在,因为有的搜索请求会跨多个索引进行搜索。每一个search子元素即为在同一个索引中的子查询,此处不仅返回了该search子元素耗时的信息,而且还返回了搜索“北京”的详细策略,即被拆分成“title:北”和“title:京”两个子查询。同理,children子元素给出了“title:北”“title:京”的耗时和详细搜索步骤的耗时,此处不再赘述。
- aggregations只有在进行聚合运算时才有内容
上面只是一个很简单的例子,如果查询比较复杂或者命中的分片比较多,profile返回的信息将特别冗长。在这种情况下,用户进行性能剖析的效率将非常低。为此,Kibana提供了可视化的profile功能,该功能建立在ES的profile功能基础上。在Kibana的Dev Tools界面中单击Search Profiler链接,就可以使用可视化的profile了,其区域布局如下图所示:
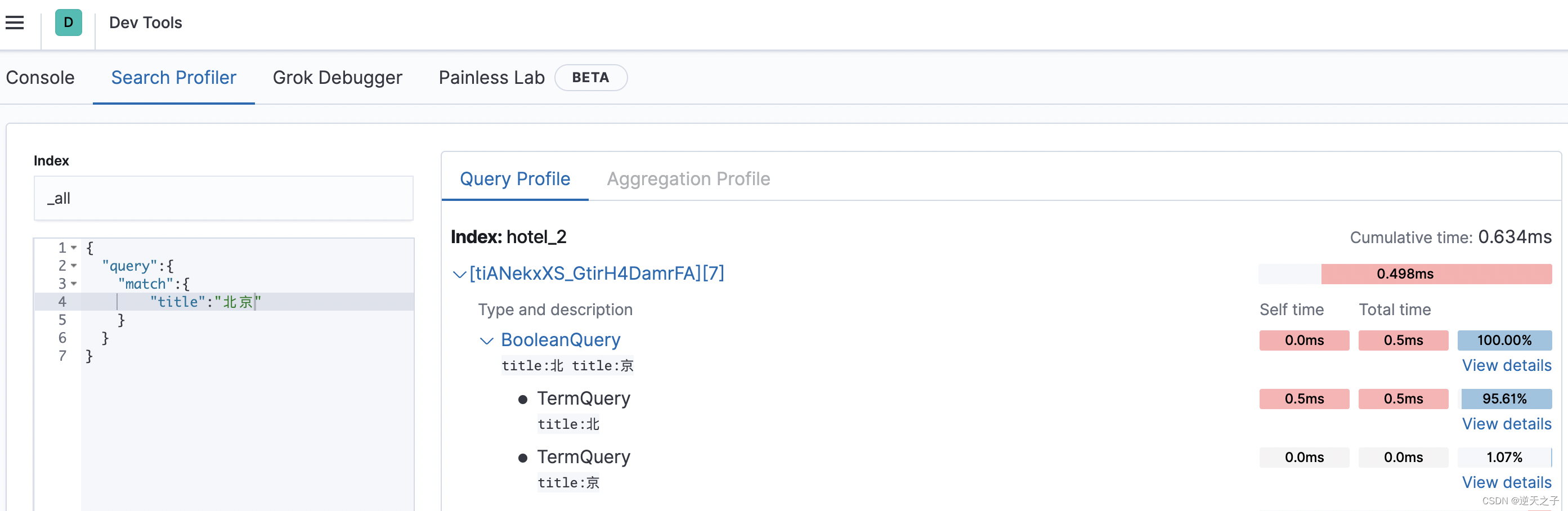
评分分析
在使用搜索引擎时,一般都会涉及排序功能。如果用户不指定按照某个字段进行升序或者降序排列,那么ES会使用自己的打分算法对文档进行排序。有时我们需要知道某个文档具体的打分详情,以便于对搜索DSL问题展开排查。ES提供了explain功能来帮助使用者查看搜索时的匹配详情。explain的使用形式如下:
GET /${index_name}/_explain/${doc_id}
{
"query":{
...
}
}以下示例为按照标题进行搜索的explain查询请求:
GET /hotel/_explain/002
{
"query":{
"match": {
"title": "python"
}
}
}执行上述explain查询请求后,ES返回的信息如下:
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"matched" : true,
"explanation" : {
"value" : 1.2039728,
"description" : "weight(title:python in 1) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 1.2039728,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 1.2039728,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.45454544,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 3.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 3.0,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
}可以看到,explain返回的信息比较全面。
另外,如果一个文档和查询不匹配,explain也会直接返回信息告知用户,具体如下:
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"matched" : false,
"explanation" : {
"value" : 0.0,
"description" : "no matching term",
"details" : [ ]
}
}














 2379
2379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











