









目录
PDF文件常用于存储和共享各种类型的文档,这些文档可能包括大量的数据表格。通过提取这些PDF表格数据,我们可以将其导入到Excel、数据库或统计软件等数据分析工具中,从而开展深入的数据分析并生成报告。与手动输入大量数据相比,采用编程方式提取表格数据能够帮助我们避免出错并节省大量时间。这篇文章将介绍如何使用Python提取PDF表格的数据,主要包括以下内容:
- Python提取PDF表格数据并保存到TXT文本文档
- Python提取PDF表格数据并保存到Excel文档
安装Python库
要提取PDF表格数据并保存到文本文档和Excel文档,可以使用Spire.PDF for Python和Spire.XLS for Python库。Spire.PDF for Python主要用于提取PDF表格数据,Spire.XLS for Python主要用于将提取的表格数据写入Excel文档。
你可以通过以下pip命令来安装它们:
pip install Spire.Xls
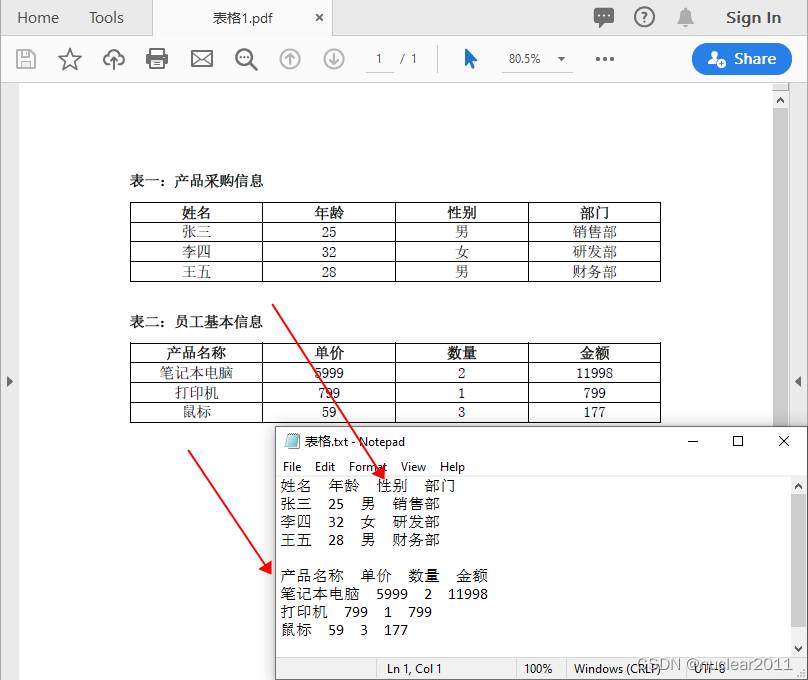
pip install Spire.PdfPython提取PDF表格数据并保存到文本文档
提取PDF文档中的表格数据主要包括以下三个关键步骤:
- 检索表格
使用PdfTableExtractor.ExtractTable(pageIndex)方法从PDF页面中提取表格。这一步能够快速定位和获取PDF文档中的表格。需要注意的是,Spire.PDF for Python通过表格的边框来识别表格,因此要确保你的PDF文档中的表格是有边框的。
- 读取数据
对于获取的每个表格,使用PdfTable.GetText(rowIndex, columnIndex)方法来读取表格单元格中的文本数据。这样可以将表格中的内容逐一提取出来。
- 保存数据
将提取的表格数据写入到文本文件中。
代码如下:
from spire.pdf.common import *
from spire.pdf import *
# 创建PdfDocument对象
doc = PdfDocument()
# 加载PDF文件
doc.LoadFromFile("表格1.pdf")
# 创建一个用于存储表格数据的列表
builder = []
# 创建一个PdfTableExtractor对象
extractor = PdfTableExtractor(doc)
# 循环遍历页面
for pageIndex in range(doc.Pages.Count):
# 从当前页面中提取表格
tableList = extractor.ExtractTable(pageIndex)
# 判断表格列表是否为空
if tableList is not None and len(tableList) > 0:
# 循环遍历表格
for table in tableList:
# 获取当前表格的行数和列数
row = table.GetRowCount()
column = table.GetColumnCount()
# 循环遍历行和列
for i in range(row):
for j in range(column):
# 获取当前单元格中的文本
text = table.GetText(i, j)
# 将文本添加到列表中
builder.append(text + " ")
builder.append("\n")
builder.append("\n")
# 将列表中的内容写入到文本文件中
with open("表格.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
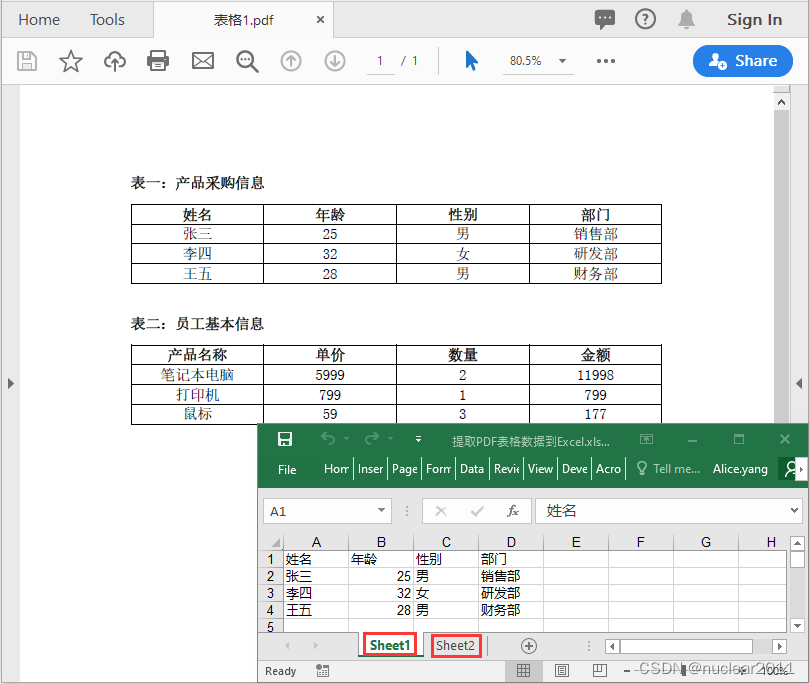
Python提取PDF表格数据并保存到Excel文档
除了将提取的数据保存到文本文件外,你还可以通过Spire.XLS for Python提供的Worksheet.Range[rowIndex, columnIndex].Value属性将它们写入到Excel文档。关键步骤如下:
- 检索表格
使用PdfTableExtractor.ExtractTable(pageIndex)方法从PDF页面中提取表格。这一步能够快速定位和获取PDF文档中的表格。需要注意的是,Spire.PDF for Python通过表格的边框来识别表格,因此要确保你的PDF文档中的表格是有边框的。
- 读取数据
对于获取的每个表格,使用PdfTable.GetText(rowIndex, columnIndex)方法来读取表格单元格中的文本数据。这样可以将表格中的内容逐一提取出来。
- 写入数据到Excel工作表
使用Worksheet.Range[rowIndex, columnIndex].Value属性将将提取的表格数据写入到Excel工作表中。
具体代码如下:
from spire.pdf import *
from spire.xls import *
# 创建PdfDocument对象
doc = PdfDocument()
# 加载PDF文件
doc.LoadFromFile("表格1.pdf")
# 创建Workbook对象
workbook = Workbook()
# 清除默认工作表
workbook.Worksheets.Clear()
# 创建PdfTableExtractor对象
extractor = PdfTableExtractor(doc)
sheetNumber = 1
# 循环遍历页面
for pageIndex in range(doc.Pages.Count):
# 从当前页面提取表格
tableList = extractor.ExtractTable(pageIndex)
# 判断表格列表是否为空
if tableList is not None and len(tableList) > 0:
# 循环遍历表格
for table in tableList:
# 为当前表格添加一个工作表
sheet = workbook.Worksheets.Add(f"Sheet{sheetNumber}")
# 获取表格的行数和列数
row = table.GetRowCount()
column = table.GetColumnCount()
# 循环遍历行和列
for i in range(row):
for j in range(column):
# 获取当前单元格中的文本
text = table.GetText(i, j)
# 将文本写入工作表的指定单元格
sheet.Range[i + 1, j + 1].Value = text
sheetNumber += 1
# 保存到文件
workbook.SaveToFile("提取PDF表格数据到Excel.xlsx", ExcelVersion.Version2013)
本文介绍了如何使用Python读取PDF表格数据,并将读取的数据保存到TXT文本文件和Excel表格。除了TXT文本和Excel格式以外,你可以自行将获取的数据写入到其他格式,如CSV、Word表格等。如需了解Spire.PDF for Python和Spire.XLS for Python的更多功能,请自行查看Spire.PDF for Python文档和Spire.XLS for Python文档。














 1669
1669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









