







前言
近年来,基于Transformer架构的多模态大语言模型(MLLM)在视觉理解和多模态推理任务中展现了出色的潜力。但这些模型通常需要大量的训练资源,限制了它们在更广泛研究和应用领域的普及。一种直接的解决方案是使用更小规模的预训练视觉和语言模型,但这往往会导致性能大幅下降。
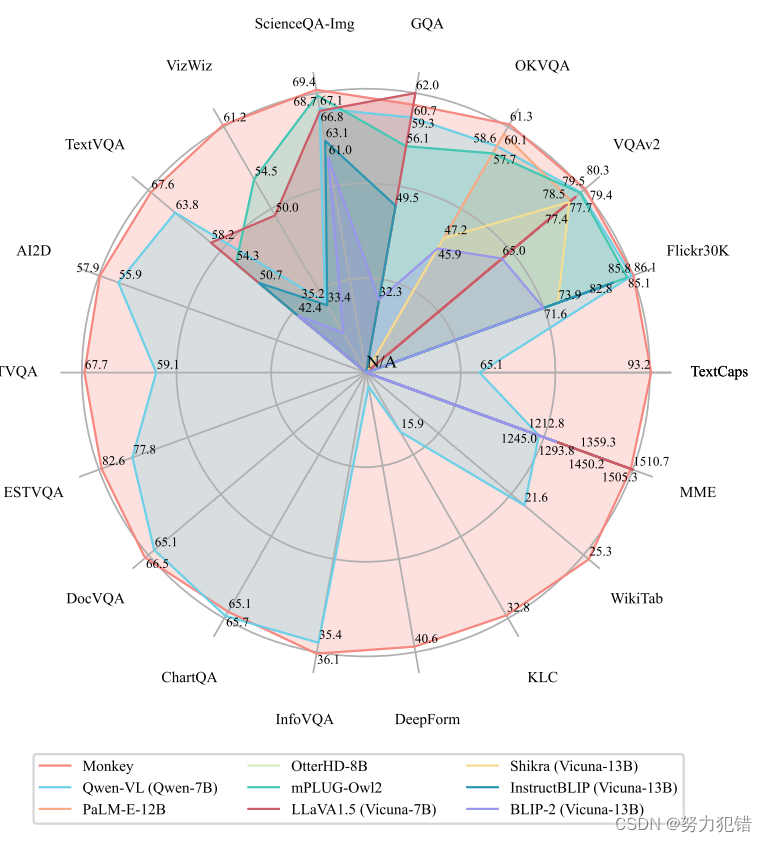
为了突破这一瓶颈,华中科技大学的研究团队提出了Monkey,这是一种创新的轻量级多模态大模型。Monkey不仅能够低成本地扩大输入分辨率,从而捕捉更细致的视觉细节,而且通过生成多层次的图像描述数据,进一步增强了模型在理解图像-文本关系方面的能力。值得一提的是,Monkey在多项基准测试上的表现不仅优于同等规模的其他MLLM,甚至在某些指标上还超越了规模更大的GPT-4V。
-
Huggingface模型下载:https://huggingface.co/echo840/Monkey
-
AI快站模型免费加速下载:https://aifasthub.com/models/echo840
Monkey的创新设计
Monkey的核心创新在于两个方面:
-
扩大输入分辨率的高效方法:Monkey将输入图像划分为多个固定大小的局部patch,并为每个patch配备独立的视觉编码器,以解决大分辨率输入带来的计算负担。同时,Monkey还采用可训练的视觉重采样器,有效整合了局部和全局的视觉信息。这种设计不
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









