







引言
智源研究院发布了一款开源的中英文语义向量模型BGE(BAAI General Embedding),在中英文语义检索精度与整体语义表征能力方面全面超越了OpenAI、Meta等同类模型。BGE模型的发布,标志着语义向量模型(Embedding Model)在搜索、推荐、数据挖掘等领域的应用迈入了一个新的阶段。
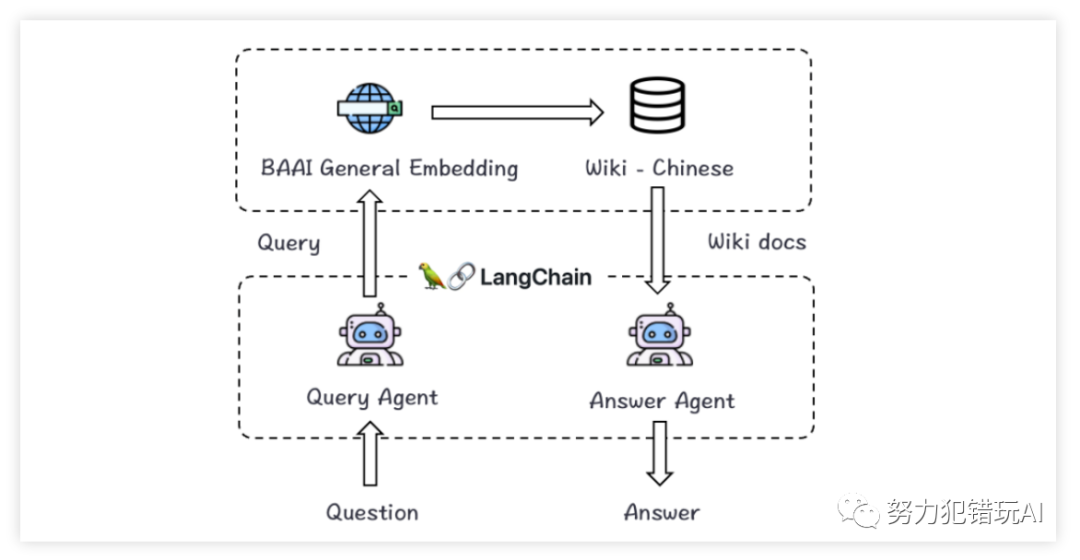
模型性能
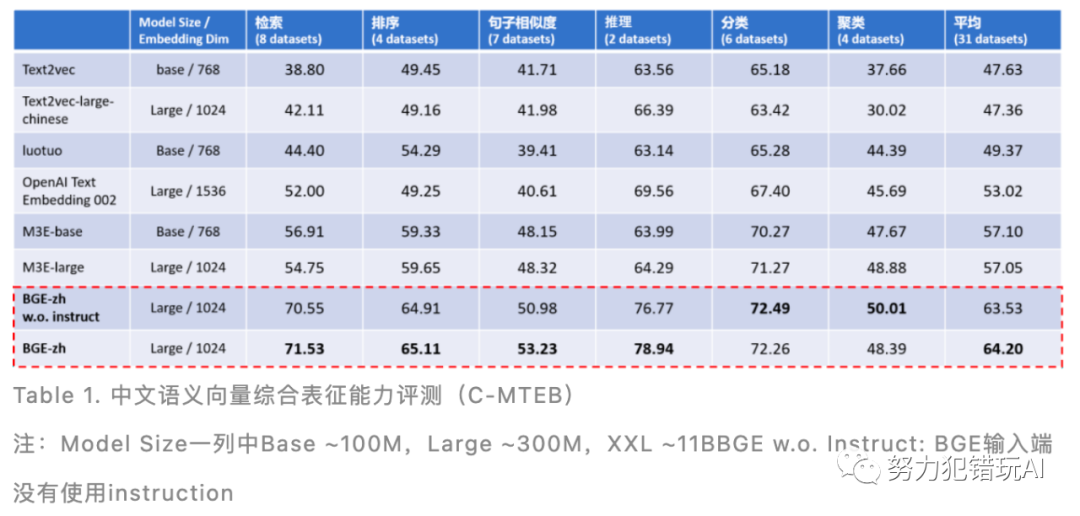
BGE模型在中文语义向量综合表征能力评测C-MTEB中表现卓越。在检索精度方面,BGE中文模型(BGE-zh)约为OpenAI Text Embedding 002的1.4倍。
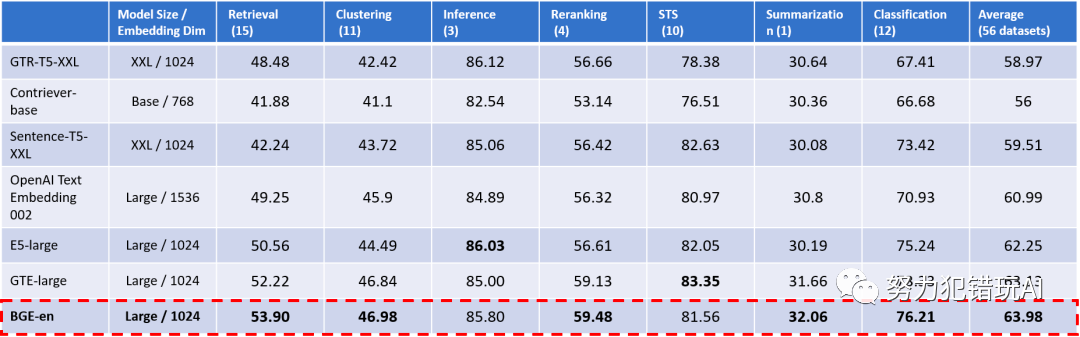
此外,BGE英文模型(BGE-en)在英文评测基准MTEB中同样展现了出色的语义表征能力,总体指标与检索能力两个核心维度均超越了此前开源的所有同类模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









