






前言
近年来,大型语言模型(LLM)在自然语言处理领域取得了突破性进展。然而,随着模型参数量的不断增加,训练和部署成本也随之大幅提升,阻碍了LLM的广泛应用。为了克服这一挑战,混合专家模型(MoE)应运而生,它通过将模型拆分成多个专家并根据输入选择激活不同的专家来降低计算成本。DeepSeek-V2-Lite模型作为DeepSeek-AI团队最新发布的MoE模型,凭借其轻量级设计和高效的性能,为MoE模型研究和应用开辟了新的方向。
-
Huggingface模型下载:https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite
-
AI快站模型免费加速下载:https://aifasthub.com/models/deepseek-ai

技术特点
DeepSeek-V2-Lite模型采用了一系列创新技术,使其成为一个高效且易于部署的轻量级MoE模型:
-
多头潜在注意力(MLA)
DeepSeek-V2-Lite模型采用了多头潜在注意力(MLA)机制。与传统的注意力机制不同,MLA通过将键值(KV)缓存压缩成潜在向量来大幅减少内存占用,从而提高推理效率。同时,为了进一步提升性能,DeepSeek-V2-Lite对查询和键进行解耦,并为每个注意力头设置了独立的维度,以提高模型的表达能力。
-
DeepSeekMoE架构
DeepSeek-V2-Lite模型采用了DeepSeekMoE架构,该架构通过细粒度的专家分割和共享专家隔离来提高专家特化能力,并有效降低模型训练成本。在DeepSeekMoE中,每个MoE层包含共享专家和路由专家,每个token激活多个路由专家,从而实现模型的稀疏计算。
-
轻量级设计
DeepSeek-V2-Lite模型参数量为16B,但每个token仅激活2.4B个参数,这使得它成为一个轻量级的MoE模型。与DeepSeek-V2相比,DeepSeek-V2-Lite的参数量减少了近10倍,但性能却毫不逊色。
-
高效部署
DeepSeek-V2-Lite模型可以在单卡40G GPU上进行部署,这使得它更容易被应用于各种实际场景中。与需要更大内存的模型相比,DeepSeek-V2-Lite的部署成本更低,也更加灵活。

性能表现
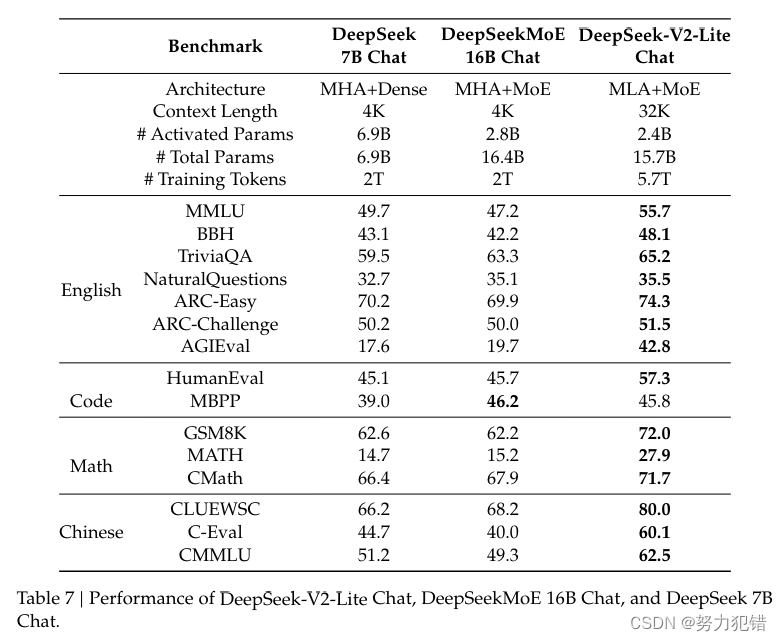
DeepSeek-V2-Lite模型在多个英语和中文基准测试中都取得了优异的性能:
-
在多个基准测试中,DeepSeek-V2-Lite的性能超过了7B密集模型和16B MoE模型,展现出了其轻量化设计带来的性能优势。
-
DeepSeek-V2-Lite模型在许多语言理解和推理任务中表现出色,例如问答、阅读理解、代码生成等,证明了其强大的多任务能力。
应用场景
DeepSeek-V2-Lite模型的轻量级设计和高效性能使其在众多应用场景中具有广阔的应用前景:
-
低资源场景: DeepSeek-V2-Lite模型可以用于训练和部署在资源受限的设备上的语言模型,例如移动设备、嵌入式系统等。
-
高效推理: DeepSeek-V2-Lite模型可以用于各种需要快速推理的场景,例如在线问答、机器翻译、文本生成等。
-
多任务学习: DeepSeek-V2-Lite模型可以用于多任务学习,例如同时进行问答、翻译和摘要等任务。
总结
DeepSeek-V2-Lite模型的推出,标志着MoE模型研究的重大进展。它证明了通过巧妙的设计和优化,可以构建出既高效又轻量级的MoE模型,并将其应用于各种实际场景中。相信DeepSeek-V2-Lite模型将为MoE模型的研究和应用开辟新的方向,为人工智能领域带来更多可能性。
模型下载
Huggingface模型下载
https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite
AI快站模型免费加速下载
https://aifasthub.com/models/deepseek-ai

















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









