






SQL示例
一、前言
1.开发环境安装
-
安装MySQL
-
启动MySQL
MySQL is configured to only allow connections from localhost by default
To connect run:
mysql -u root
To start mysql now and restart at login:
brew services start mysql
-
下载客户端工具Sequel Ace并登录
-
或者使用Docker安装MySQL
-
或者使用阿里云MaxComputer服务
二、总结思维导图
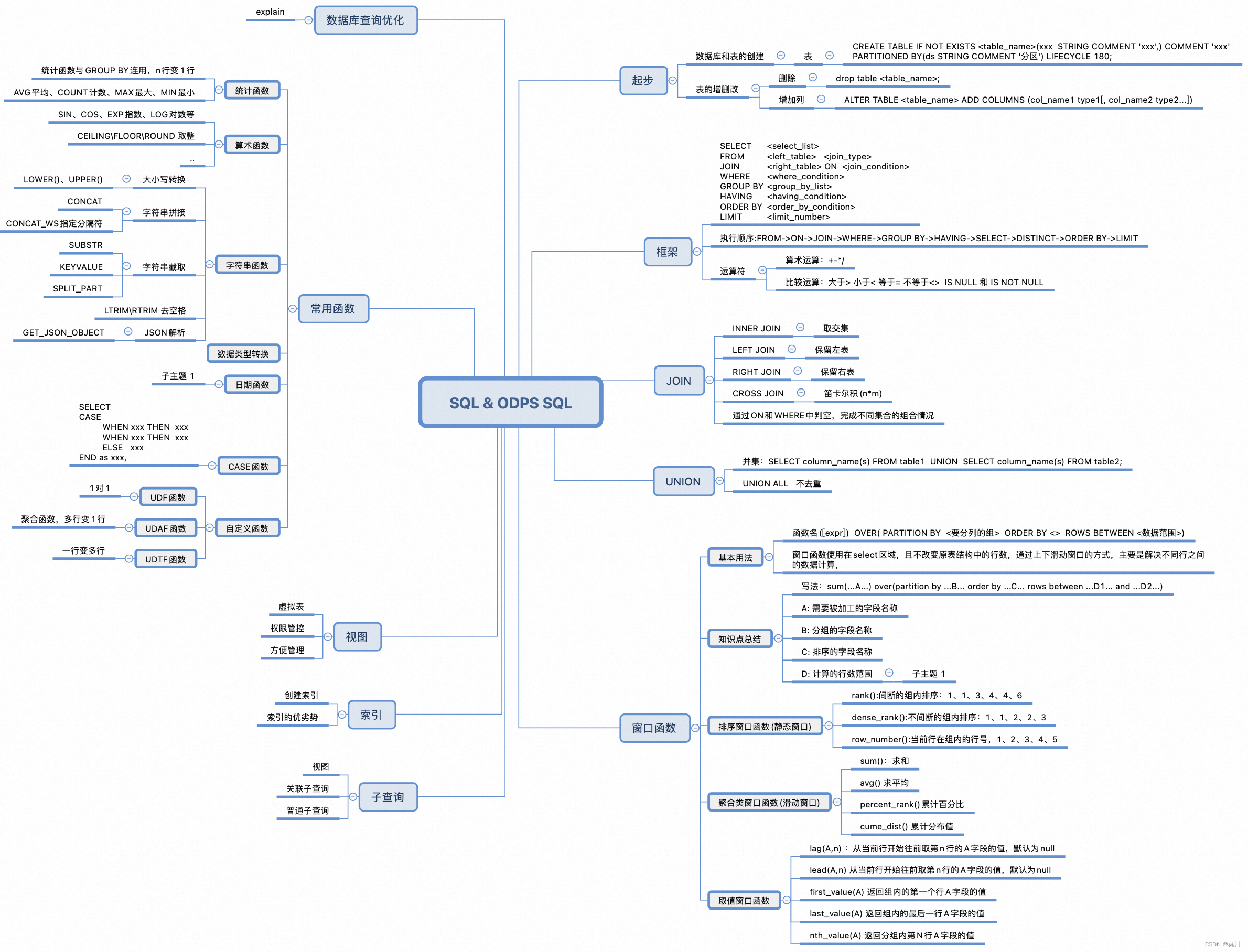
三、示例SQL
- select过滤和新增字段
-- 为customer_list表新增字段
SELECT customer_list.*,
LAG(`sid`) over(PARTITION BY `sid`
ORDER BY `sid` DESC)
FROM customer_list;
- select过滤字段(ODPS支持)
SELECT `a.*` -- 过滤表中所有以a开头的列
FROM customer_list
WHERE 1 = 1
AND ds = '20230801'
;
- 取整和四舍五入
SELECT round(3.141592653) AS 四舍五入 -- 3
,round(3.141592653,0) -- 3
,round(3.141592653,3) -- 3.142
,floor(3.141592653) AS 向下取整 -- 3
,CEIL(3.141592653) AS 向上取整 -- 4
,abs(-1.2) AS 绝对值 -- 1.2
,abs(-2) -- 2
;
- 字符串函数(ODPS SQL)
-- 大小写转换
SELECT TOLOWER("aBcd") = "abcd" -- true
,TOUPPER("aBcd") = "ABCD" -- true
;
-- 字符串拼接 同mysql
SELECT CONCAT('ab','c') -- abc
,CONCAT('a',NULL,'b') -- NULL
,CONCAT('a','c','b')-- acb
;
-- JSON解析
SELECT GET_JSON_OBJECT('{"store":{"fruit":[{"weight":8,"type":"apple"}]}}','$.store.fruit[0].weight') -- 8
,GET_JSON_OBJECT('{"email":"amy@123.com","owner":"amy"}','$.email') -- amy@123.com
,GET_JSON_OBJECT('[1,2,3]','$.[0]'); -- 1
-- 字符串按长度截取
SELECT SUBSTR("abc",2) = "bc"
,SUBSTR("abc",2,1) = "b"
,SUBSTR("abc",-2,2) = "bc"
,SUBSTR("abc",-3) = "abc"
;
-- KEYVALUE字符串解析
SELECT KEYVALUE('tracking_id=1,name=lilei',',','=','tracking_id') = 1
,KEYVALUE('tracking_id=1,name=lilei',',','=','name') = 'lilei'
;
- where过滤数据
使用where过滤数据
SELECT
*
FROM
actor
WHERE
last_name = 'ALLEN' OR last_name = 'DAVIS'
ORDER BY
`actor_id`;
where可以和and或者or联合使用,来圈定条件;常见的比较符:
=、<>、!=、>、<、>=、<=、IN、NOT IN、BETWEEN、LIKE、IS NULL、IS NOT NULL
- case when示例
统计address表格中,postal_code在区间的分布
SELECT SUM(CASE WHEN `postal_code` < 1000 THEN 1 ELSE 0 END) AS c1
,SUM(CASE WHEN (`postal_code` < 5000 AND `postal_code` >= 1000) THEN 1 ELSE 0 END) AS c2
,SUM(CASE WHEN (`postal_code` < 10000 AND `postal_code` >= 5000) THEN 1 ELSE 0 END) AS c3
,SUM(CASE WHEN (`postal_code` >= 10000) THEN 1 ELSE 0 END) AS c4
FROM address
;
- 派生表的子查询
通过派生表temp1,统计符合条件的数量
SELECT COUNT(*) AS cnt
FROM (
SELECT *
FROM actor
WHERE last_name = 'ALLEN'
OR last_name = 'DAVIS'
ORDER BY `actor_id`
) temp1
;
- 常见通用格式(统计数字)
SELECT t1.a1 -- 所有要展示的字段,都写在这里,可能不止来源一个表
,t1.a2
,COUNT(DISTINCT t1.a1) AS cnt
,t2.a3
,t2.a4
FROM t1 -- 来源于第一个表
LEFT JOIN (
SELECT a3
,a4
FROM xxx
WHERE ds = 'xxx'
) t2 -- 第二个表
ON t1.id = t2.id -- JOIN的关联条件
WHERE t1.a1 = 'xx' -- 过滤条件
AND t1.ds = '20230711'
AND t1.a1 IS NOT NULL
GROUP BY t1.a1 -- 分组:注意,所有select中出现的字段(除聚合函数外),都需要出现在GROUP BY中
,t1.a2
,t2.a3
,t2.a4
HAVING cnt > 0 -- 对分组统计之后的最终数据做一个过滤,这里可以直接使用聚合函数as之后的别名
ORDER BY cnt DESC -- 排序
LIMIT 30
;
1.执行顺序:->from (去加载t1 和 t2这2个表 ) -> join -> on -> where -> group by->select 后面的聚合函数count,sum -> having -> distinct -> order by -> limit
2.FROM 子句执行顺序为从后往前、从右到左
- 查询最近几天某城市的xx
SELECT ds
,SUM(CASE WHEN cnt >= 1 THEN 1 ELSE 0 END) AS fake_cnt_android
,COUNT(*) AS all_cnt_android
FROM (
SELECT user_id AS id
,SUM(CASE WHEN (location_type = '21' OR location_type = '25') THEN 1 ELSE 0 END) AS cnt
,ds
FROM xxxxxxxx
WHERE ds IN ('20230623','20230624','20230625','20230626','20230627')
AND city_name = 'xx市'
AND location_type IS NOT NULL -- 过滤掉无效数据
AND location_type != -1 -- 过滤掉xxx
GROUP BY ds
,id
) id_cnt
GROUP BY ds
;
- 一个数据开发的ODPS SQL示例
CREATE TABLE IF NOT EXISTS temp_xxx
(
city STRING COMMENT '城市'
,line_name STRING COMMENT 'xxx'
,fake_cnt BIGINT COMMENT 'xx数量'
,all_cnt BIGINT COMMENT '总数量'
,ratio STRING COMMENT '百分比'
)
COMMENT 'xxx情况表'
PARTITIONED BY
(
ds STRING COMMENT 'day 分区字段'
)
LIFECYCLE 30
;
INSERT OVERWRITE TABLE temp_xxx PARTITION (ds='${bizdate}')
SELECT city
,line_name
,fake_cnt
,all_cnt
,CONCAT(CAST(ROUND(100 * fake_cnt / all_cnt,2) AS STRING),'%') AS ratio
FROM (
SELECT CASE mode
WHEN 'xx' THEN 'xxxxx'
WHEN 'xx' THEN 'xxxxx'
ELSE 'xxxxxx'
END AS line_name
,city
,SUM(CASE WHEN cnt >= 1 THEN 1 ELSE 0 END) AS fake_cnt
,COUNT(*) AS all_cnt
FROM (
SELECT rider_._id
,SUM(CASE WHEN location_type = '21' THEN 1 ELSE 0 END) AS cnt
,ds
,rider_.city_name AS city
,id_mode.tms_line_name AS mode
FROM xxxxxxxxxx AS rider_
LEFT JOIN (
SELECT _id AS id
,tms_line_name
FROM xxxxxxxx.xxxdi
WHERE ds = '${bizdate}'
AND tms_line_name IS NOT NULL
) id_mode
ON id_mode.id = rider_._id
WHERE ds = '${bizdate}'
AND _id IS NOT NULL
AND city_id IN ('91','66')
AND location_type IS NOT NULL -- 过滤掉无效数据
GROUP BY ds
,rider_._id
,mode
,rider_.city_name
) id_cnt
GROUP BY city
,line_name --GROUP BY ROLLUP(city,mode)
) mod_cnt
;
其中bizdate可以在调度配置中设置
- 窗口函数示例
SELECT t2.city_name
,CASE WHEN t2.location_type < 0 THEN 'iOS'
ELSE 'Android'
END AS os_name
,SUM(CASE WHEN t2.speed > 35 THEN 1 ELSE 0 END) AS cnt_35
,SUM(CASE WHEN t2.speed > 25 THEN 1 ELSE 0 END) AS cnt_25
,COUNT(*) AS all_cnt
,100.0 * SUM(CASE WHEN t2.speed > 35 THEN 1 ELSE 0 END) / COUNT(*) AS ratio_35
,100.0 * SUM(CASE WHEN t2.speed > 25 THEN 1 ELSE 0 END) / COUNT(*) AS ratio_25
FROM (
SELECT t1x.target_id
,t1x.latitude
,t1x.longitude
,t1x.tracked_at
,t1x.city_name
,t1x.location_type
,CALDISTANCE(CAST(t1x.latitude AS DOUBLE),CAST(t1x.longitude AS DOUBLE),CAST(t1x.per_lat AS DOUBLE),CAST(t1x.per_lng AS DOUBLE)) / (
1.0 + (
t1x.tracked_at - t1x.per_tktime
)
) AS speed
FROM (
SELECT t1s.target_id
,t1s.latitude
,t1s.longitude
,t1s.tracked_at
,t1s.city_name
,t1s.location_type
,t1s.is_diff
,t1s.per_lat
,t1s.per_lng
,LAG(t1s.tracked_at,1) OVER (PARTITION BY t1s.target_id ORDER BY t1s.tracked_at ) AS per_tktime
FROM (
SELECT t1dot.target_id
,t1dot.latitude
,t1dot.longitude
,t1dot.tracked_at
,t1dot.city_name
,t1dot.location_type
,t1dot.is_diff
,t1dot.per_lat
,t1dot.per_lng
FROM (
-- 按照经纬度进行去重和打标
SELECT t1.target_id
,t1.latitude
,t1.longitude
,t1.tracked_at
,t1.city_name
,t1.location_type
,t1.per_lat
,t1.per_lng
,CASE WHEN (
t1.latitude = t1.per_lat
AND t1.longitude = t1.per_lng
AND t1.location_type = t1.per_type
) THEN 0
ELSE 1
END AS is_diff
FROM (
-- 使用窗口函数抽取上一行的经纬度
SELECT target_id
,latitude
,longitude
,city_name
,location_type
,tracked_at -- 使用窗口函数获取上一行的数据
,LAG(latitude,1) OVER (PARTITION BY target_id ORDER BY tracked_at ) AS per_lat
,LAG(longitude,1) OVER (PARTITION BY target_id ORDER BY tracked_at ) AS per_lng
,LAG(location_type,1) OVER (PARTITION BY target_id ORDER BY tracked_at ) AS per_type
FROM dwd_test_person_location_table
WHERE 1 = 1 -- AND target_id IN ('216792939','231669315')
--AND ds = '20230724'
--AND tracked_at BETWEEN UNIX_TIMESTAMP('2023-07-24 14:00:00') AND UNIX_TIMESTAMP('2023-07-24 15:00:00')
AND ds = '${bizdate}'
AND location_type IS NOT NULL
) t1
WHERE t1.per_lat IS NOT NULL
AND t1.per_lat IS NOT NULL
) t1dot
WHERE 1 = 1
AND t1dot.is_diff = 1
) t1s
) t1x
WHERE t1x.per_tktime IS NOT NULL
) t2
GROUP BY t2.city_name
,os_name
HAVING cnt_35 > 0
OR cnt_25 > 0
ORDER BY cnt_35 DESC,cnt_25 DESC
;
其中dwd_test_person_location_table表,保存了很多人的经纬度列表和轨迹;第一个子查询临时表t1,是按照id维度进行PARTITION,然后按照时间戳进行升序排序,之后通过LAG函数,将上一行的数据补充到本行,方便后续计算距离;
附
参考资料:https://help.aliyun.com/zh/maxcompute/
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









