







原题
给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
例如,如果 words = ["ab","cd","ef"], 那么 "abcdef", "abefcd","cdabef", "cdefab","efabcd", 和 "efcdab" 都是串联子串。 "acdbef" 不是串联子串,因为他不是任何 words 排列的连接。 返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
解题思路:
用滑动窗口思路。words 数组中字串都是固定长度,所以串联字串长度(即滑动窗口大小)为:单个字串长度singleStringSize乘以 words的size,即:slideWindowSize = singleStringSize* words.size
解题逻辑很清晰,循环从字符串s中取出subString,判断subString中所有singleStringSize长的子串smallString来自words,关键在于如何确认后者。
串联子串 是一个包含 words 中所有字符串以任意顺序排列连接起来的子串,
很容易想到从subString循环截取singleStringSize长的子串判断是否来自words并计数count,当count == words.size时,记录初始的position。但是words存在相同的子串的时候,用例就会失败,因为此时count并不能保证smallString来自words的同时也和words中的子串一一对应,例如:
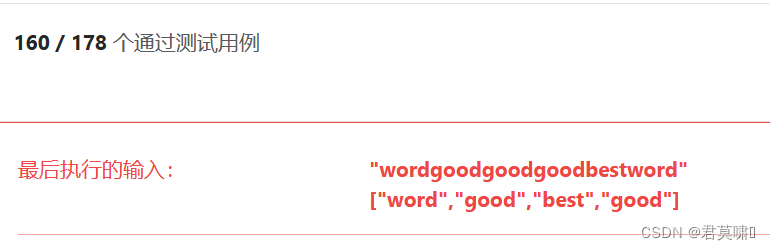
这时候再优化下就有如下算法,改进的思路为创建一个temp临时List,将words的子串全部读入,若smallString属于temp列表,直接去掉、再count++,就能保证smallString和words中的子串一一对应,此时count计数是准确的
代码:
public fun findSubstring(s: String, words: Array<String>): List<Int> {
var list = mutableListOf<Int>()
val singleStringSize:Int = words.get(0).length
val slideWindowSize:Int = singleStringSize * words.size
var position = 0 //记录串联子串开始索引
while (position + slideWindowSize <= s.length) {
var subString = s.substring(position, position + slideWindowSize)
var i = 0
var count = 0
var temp = words.toMutableList()
while (i + singleStringSize <= subString.length) {
val smallString = subString.substring(i, i + singleStringSize)
if (temp.contains(smallString)) {
// 确保smallString全部来自words,且一一对应
temp.removeAt(temp.indexOfFirst { it.equals(smallString) })
count++
} else {
break
}
if (count == words.size) {
list.add(position)
}
i = i + singleStringSize
}
position++
}
return list
}遗憾的是,这个算法在算法复杂度和空间复杂度表现上都极差,但好歹通过了实现从无到有
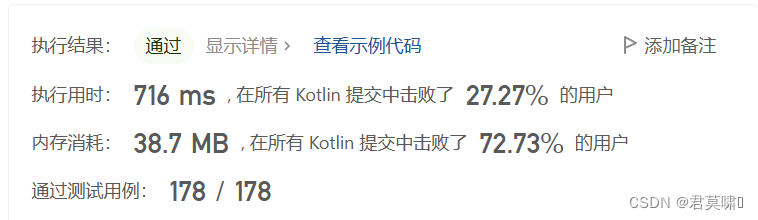
小优化
716ms仅仅击败27.27%(kotlin大神多)
下面是对照力扣上题解的修改思路,现将words的子串都读入wordsMap hashMap中,存在相同字串value值就+1(wordsMap.getOrDefault(w, 0) + 1,很重要的技巧)
分解subString的时候也是同样的思路,将截取的smallString读入temp hashMap,最后比较temp和wordsMap是否相等决定是否将position保留(记得每次内循环前temp.clear,这是个坑)
public fun findSubstring(s: String, words: Array<String>): List<Int> {
var list = mutableListOf<Int>()
var wordsMap = HashMap<String, Int>();
val singleStringSize:Int = words.get(0).length
val slideWindowSize:Int = singleStringSize * words.size
for (w in words) {
wordsMap.put(w, wordsMap.getOrDefault(w, 0) + 1)
}
var temp = HashMap<String, Int>()
var position = 0
while (position + slideWindowSize <= s.length) {
var subString = s.substring(position, position + slideWindowSize)
var left = 0
temp.clear()
while (left + singleStringSize <= subString.length) {
val smallString = subString.substring(left, left + singleStringSize)
if (wordsMap.contains(smallString)) {
temp.put(smallString, temp.getOrDefault(smallString, 0) + 1)
} else {
break
}
if (temp.equals(wordsMap)) {
list.add(position)
}
left = left + singleStringSize
}
position++
}
return list
}经过优化耗时降低了两百多ms,但是同时内存也多了差不多4M,唉,提高不大
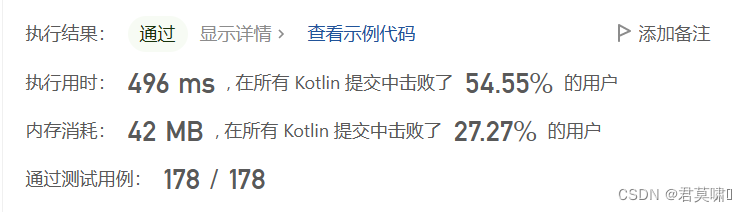
思考
除了上面分解subString的方法,还有一种思路是将words中的所有字串拼接来,保存到一个hashMap中,这样直接比较subString是否contains来记录position索引,但貌似拼接的算法和空间复杂度会更高。
水平有限,欢迎大佬评论区分享














 1475
1475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









