






手机号被标记成骚扰电话,这是一个典型的名单识别的场景,大量手机号,说明存储量大。所以,需要考虑的就是数据量大而带来的查询效率低下的问题。
数据库
这个方案的设计,首先需要有数据库,因为最终数据库的持久化肯定是要存在基于磁盘的关系型数据库的,这里的数据库可以是MySQL等其他数据库都可以。
只需要按照如下方式建一张表,标记上手机号和标记时间即可。为了方便查询,提升效率,针对手机号增加一个唯一索引:
CREATE TABLE spam_numbers (
id BIGINT AUTO_INCREMENT PRIMARY KEY, phone_number VARCHAR (15) UNIQUE NOT NULL, marked_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);有了数据库之后,按照如上方式,存储3000万左右的手机号,因为建了索引、都可以在1s以内查询出结果。
分布式缓存
但是因为骚扰电话号其实是相对不变的,那么这里为了进一步提升性能,是非常适合使用缓存的。所以,可以在数据库之上加一层分布式缓存,如Redis,把黑手机号保存在 Redis 中。
但是这里需要注意一个存储量的问题,大量的手机号保存在 Redis 中,会占用内存,浪费资源,所以可以考虑以下两个优化方案:
1、只保存一部分热点手机号
即只针对比较热的手机号做缓存,比如只缓存出现频率比较高的前20%目
的手机号,放到缓存中,并定期的更新缓存,或者用LRU、LFU 等算法来做缓存的淘汰和更新。这里建议用 LFU。
2、使用 bloomFilter 来保存
通过使用 BloomFilter 来保存数据,利用 bitmap 来减少内存的占用。
本地缓存
除了分布式缓存以外,因为骚扰手机号确实是变化不频繁,而且基本上只增不减,所以我们其实在可以使用本地缓存的,把一些热门的号码缓存在本地的 Caffeine 或者是 GuavaCache 中。进一步的提升性能。
不一致问题
当然,有了缓存之后,需要考虑不一致的问题,数据库、Redis、和本地缓存之间的一致性需要保证。
还是那句话,结合场景,黑手机号这种场景,基本上是"增多减少的,所以,我们只需要尽可能的保证新增的手机号不会被误判为不存在就行了。
那么,我们只需要保证在本地缓存查不到的,再去查分布式缓存,分布式缓存查不到的,再去查数据库即可。
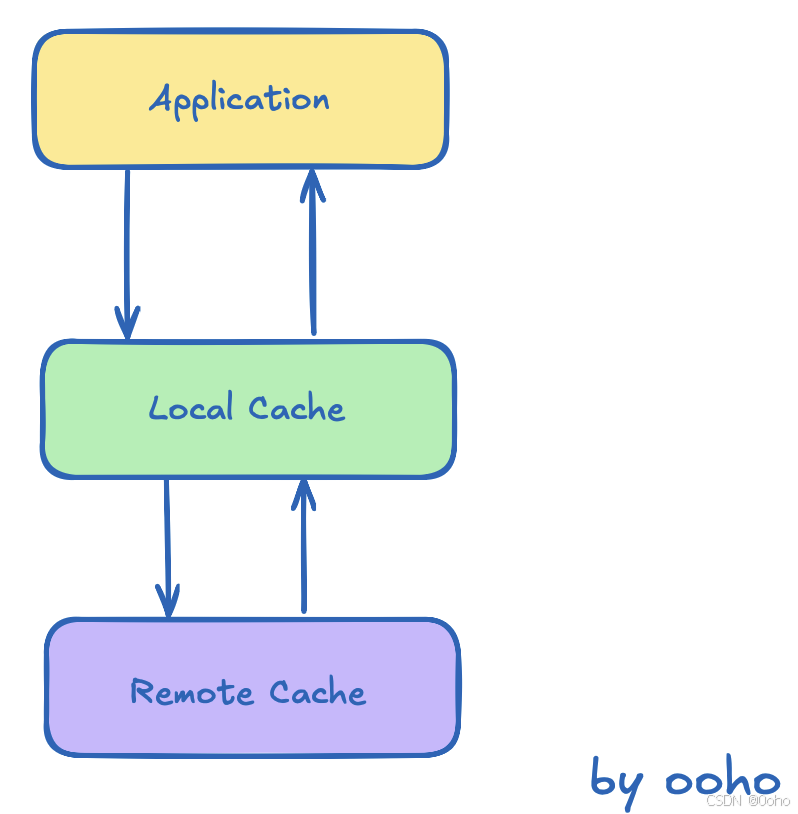
至于本地缓存之间不一致的问题,其实同样的方法就能解决,只需要保证:查不到就往上查,一直查到数据库即可

















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









