







http://blog.csdn.net/yangbutao/article/details/44977565
MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。Spark的设计初衷就是为了支持一些迭代的Job, 这正好符合很多机器学习算法的特点。在Spark官方首页中展示了Logistic Regression算法在Spark和Hadoop中运行的性能比较,如图下图所示。
 \
\
可以看出在Logistic Regression的运算场景下,Spark比Hadoop快了100倍以上!
MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤,
之前Mahout或者自己写的MR来解决复杂的机器学习,导致效率低,spark特别适合迭代式的计算,这正是机器学习算法训练所需要的,MLlib是基于spark之上算法组件,基于spark平台来实现。
主要的机器学习的算法目前在MLlib中都已经提供了,分类回归、聚类、关联规则、推荐、降维、优化、特征抽取筛选、用于特征预处理的数理统计方法、以及算法的评测。
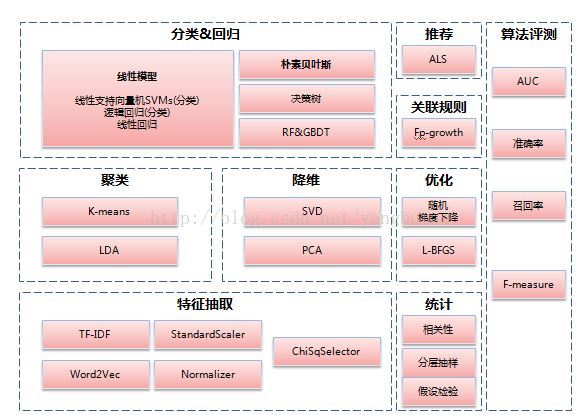
以上是目前spark1.3支持的算法包,相比较之前的版本增加了新的算法,主题模型LDA,高斯混合模型GMM,FP-Growth关联规则等,当然还有其他一些算法性能方面的提升等等。















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









