







 本文介绍了使用Zookeeper进行服务注册与发现的改造方案,包括服务提供者向Zookeeper注册、消费者获取服务列表并缓存,以及服务异常时的重试机制。同时,文章探讨了Zookeeper存在的风险,如服务发现延迟、CP特性可能导致的服务可用性问题,以及选举速度和性能限制。提出了回滚方案和应对Zookeeper完全失效的容错策略。
本文介绍了使用Zookeeper进行服务注册与发现的改造方案,包括服务提供者向Zookeeper注册、消费者获取服务列表并缓存,以及服务异常时的重试机制。同时,文章探讨了Zookeeper存在的风险,如服务发现延迟、CP特性可能导致的服务可用性问题,以及选举速度和性能限制。提出了回滚方案和应对Zookeeper完全失效的容错策略。
1.前言
上一章描述了现有系统架构的模式和改造方向,本章节主要描述改造的基本方案和相关问题描述。
2.改造方案
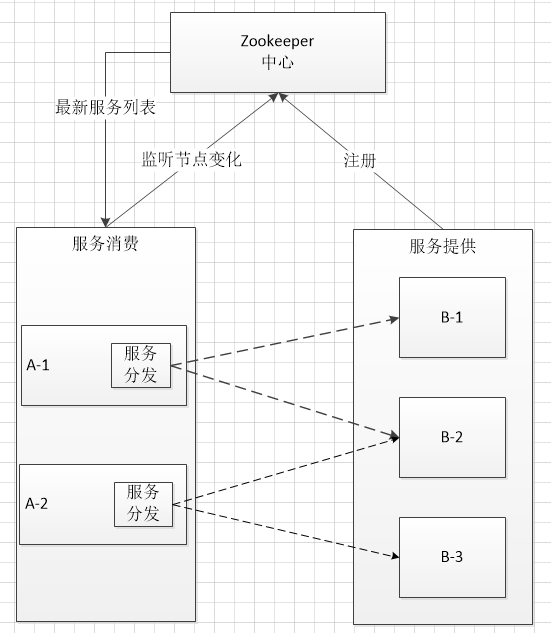
基本流程:
1) 服务提供者B启动到Zookeeper服务器处进行注册;
2) 服务消费者A启动时,请求Zookeeper服务器获取最新的B服务存活列表,并保存到本地缓存中;
3)A请求B服务器时,根据缓存中的B服务器列表,随机选取一个进行请求。
服务变动:
1) 当B出现异常或人工关闭不能提供服务时,Zookeeper服务器某个节点会探测到B节点的变化,更新本节点B服务器列表;
2) Zookeeper内部节点进行数据同步;
3) 服务消费者A监听到B服务列表的变化,更新本地缓存。
自动重发机制:
B服务挂掉到A缓存更新大约需要3-5s的时间(根据网络环境不同还需仔细测试)。为了保证服务的实时可用,A请求B发生异常时,需要根据服务消费报错信息,处理特定异常进行自动重发。
3. 存在风险和问题
1) 服务发现速度慢的问题,上述描述服务延迟问题。
2) Zookeeper 作为服务发现存在的问题
在分布式系统领域有个著名的CAP定理(C-数据一致性;A-服务可用性;P-服务对网络分区故障的容错性,这三个特性在任何分布式系统中不能同时满足,最多同时满足两个)。
ZooKeeper是个CP的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。但是别忘了,ZooKeeper是分布式协调服务,它的职责是保证数据(注:配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致;所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了,如果是AP的,那么将会带来恐怖的后果(注:ZooKeeper就像交叉路口的信号灯一样,你能想象在交通要道突然信号灯失灵的情况吗?)。而且,作为ZooKeeper的核心实现算法Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。
参考:
为什么不应该使用Zookeeper做服务发现 http://dockone.io/article/78
Ribbon和Eureka的集成使用 http://blog.csdn.net/defonds/article/details/38016301
3) Zookeeper不是为高可用性设计的
4) Zookeeper的选举过程速度很慢
5) Zookeeper的性能是有限的
4 制定回滚方案
初步使用Zookeeper时,要考虑Zookeeper使用和现在架构的切换。实现更改程序配置进行 使用Zookeeper和F5之间的切换。
Q&A
1) 中心化B-Proxy存在的意义
中心化的B-Proxy使用代理模式实现,B模块的改变对于上层服务是不可见的,降低了系统的耦合度。
模块的增加、删除无需修改上层服务请求者。但交易量过大时需要考虑B-Proxy的负载问题。
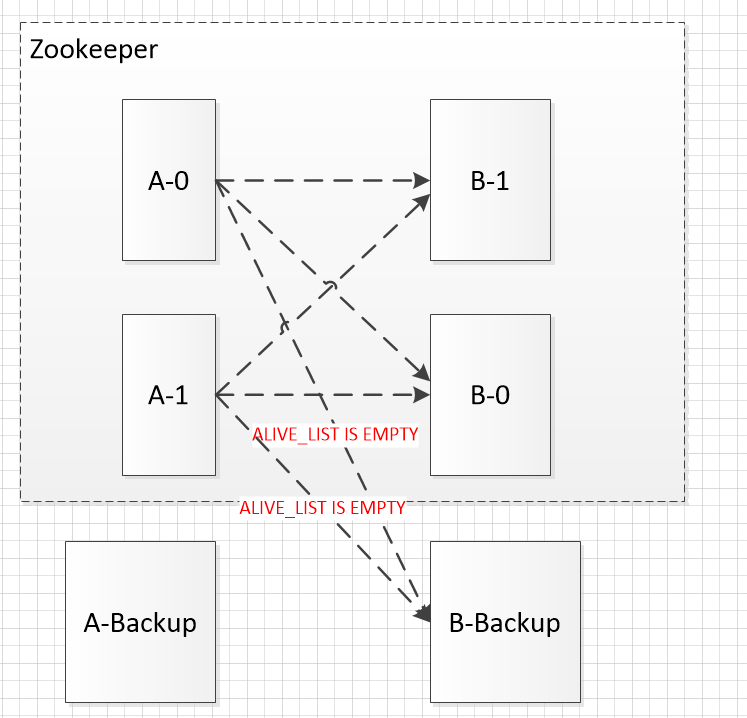
2) 当Zookeeper服务和B之间通讯全部异常,Zookeeper监听到的可用服务为零的时候,服务请求端如何容错。
服务请求者需要配置除Zookeeper之外特定的一个服务提供者地址,该服务不受Zookeeper监控。
当Zookeeper监控的服务列表由于某种情况全部挂掉之后,服务请求者判断可用列表为空时自动请求该固定的服务提供者(backup)。
要求服务提供者需要配置开关,开关开启请求Zookeeper,开关关闭不请求Zookeeper。

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









