







信息发现
推荐系统,与搜索引擎对应,又称为推荐引擎。随着推荐引擎的出现,用户获取信息的方式从简单的目标明确的数据的搜索转换到更高级更符合人们使用习惯的信息发现。
推荐引擎
推荐引擎利用特殊的信息过滤技术,将不同的物品或内容推荐给可能对它们感兴趣的用户。
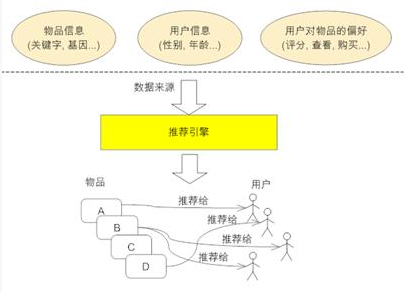
元数据:例如关键字,基因描述等; 系统用户的基本信息,例如性别,年龄等 用户对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。
用户偏好信息:1.显式的用户反馈:例如用户对物品的评分,或者对物品的评论。2.隐式的用户反馈:例如用户购买了某物品,用户查看了某物品的信息等等。
推荐引擎的分类
根据推荐引擎是不是为不同的用户推荐不同的数据,推荐引擎可以分为基于大众行为的推荐引擎(对每个用户都给出同样的推荐)和个性化推荐引擎(对不同的用户,根据他们的口味和喜好给出更加精确的推荐)。从根本上说,只有个性化的推荐引擎才是更加智能的信息发现过程。
(1) 根据系统用户的基本信息发现用户的相关程度,这种被称为基于人口统计学的推荐(Demographic-based Recommendation)。
(2) 根据推荐物品或内容的元数据,发现物品或者内容的相关性,这种被称为基于内容的推荐(Content-based Recommendation)。
(3) 根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,这种被称为基于协同过滤的推荐(Collaborative Filtering-based Recommendation)。
基于人口统计学的推荐
一种最易于实现的推荐方法,简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
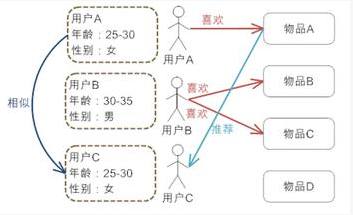
首先,系统对每个用户都有一个用户 Profile 的建模,其中包括用户的基本信息,例如用户的年龄,性别等等,然后,系统会根据用户的 Profile 计算用户的相似度进行推荐。
基于内容的推荐
根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。
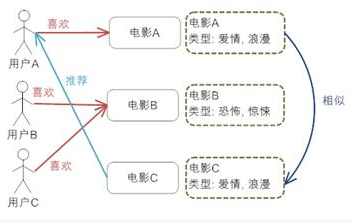
首先我们需要对电影的元数据有一个建模,然后通过电影的元数据发现电影间的相似度,最后实现推荐。需要对物品进行分析和建模,推荐的质量依赖于对物品模型的完整和全面程度。
基于协同过滤的推荐
随着 Web2.0 的发展,Web 站点更加提倡用户参与和用户贡献,因此基于协同过滤的推荐机制因运而生。它的原理很简单,就是根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐。
(1) 基于用户的协同过滤推荐
根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K- 邻居”的算法;然后,基于这 K 个邻居的历史偏好信息,为当前用户进行推荐。
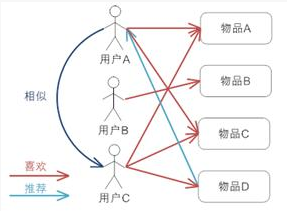
在用户的历史偏好的数据上计算用户的相似度,基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。
算法流程:

(2) 基于项目的协同过滤推荐
使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。
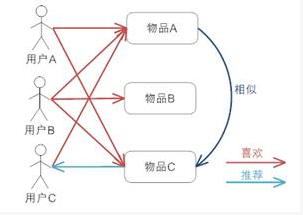
喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
(3) 基于模型的协同过滤推荐
基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
混合的推荐机制
(1) 加权的混合(Weighted Hybridization):用线性公式(linear formula)将几种不同的推荐按照一定权重组合起来,具体权重的值需要在测试数据集上反复实验,从而达到最好的推荐效果。
(2) 切换的混合(Switching Hybridization):允许在不同的情况下(数据量,系统运行状况,用户和物品的数目等),选择最为合适的推荐机制计算推荐。
(3) 分区的混合(Mixed Hybridization):采用多种推荐机制,并将不同的推荐结果分不同的区显示给用户。
(4) 分层的混合(Meta-Level Hybridization):采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更加准确的推荐。
总结
推荐引擎只是默默的记录和观察你的一举一动,然后再借由所有用户产生的海量数据分析和发现其中的规律,进而慢慢的了解你,你的需求,你的习惯,并默默的无声息的帮助你快速的解决你的问题,找到你想要的东西。
链接:http://www.edu.xxt.cn/articleFront/articleDetailed.action?article.id=2963















 3210
3210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









