










1、Motivation
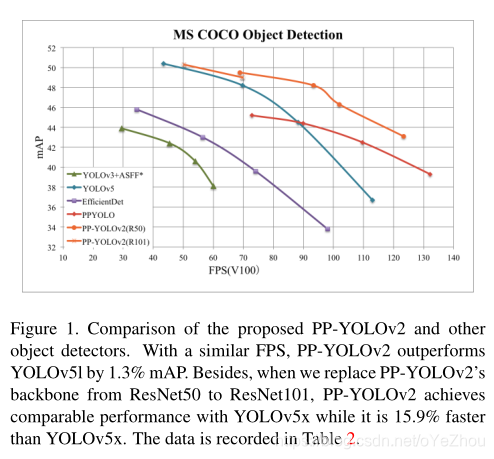
之前提出的PP-YOLO碾压了YOLOv4,而YOLOv5出来后,这种碾压消失了。于是,作者表示不服,继续对PP-YOLO进行改进,最终得到了PP-YOLOv2,再次形成碾压之势,见上图1。在PP-YOLOv2中,综合评估了一系列改进tricks,并通过增量消融实验验证了其对模型最终性能的影响,同时也讨论了一些不work的tricks。
2、Baseline
首先,数据预处理有:MixUp、RandCrop、RandomFlip、RGB每个通道归一化。然后,采用的baseline模型为PP-YOLO,其backbone为ResNet50-vd,并采用了十数个tricks才提升性能,详见:PP-YOLO: 基于YOLOv3改进,超过YOLOv4,速度与精度齐飞的目标检测器_pp-yolo和yolov4-CSDN博客。最后,训练策略方面,8GPUs+96batchsize+SGD+LR warmup+momentum+weight decay+gradient clipping。
3、Refinements
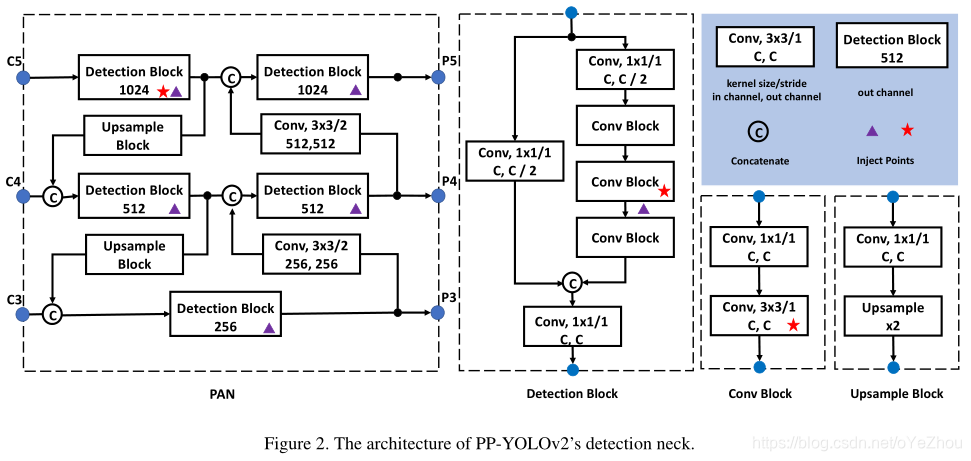
(1)Path Aggregation Network
在目标检测中,neck的作用通常是构造高级语义的feature maps。PP-YOLO使用的FPN,而这里则使用的FPN的一个变种——PAN来作为neck,PAN的结构如图2:
(2)Mish Activation Function
YOLOv4/5中均在backbone中使用了Mish激活函数,而PP-YOLOv2则没有在backbone中使用,因为其所用backbone的性能已经很高了。因此,只在neck中使用了Mish。
(3)Larger Input Size
增大输入的尺寸能够使模型对小目标检测更友好,从而提升性能。不过这也会增大内存占用率,因此这里减小了batchsize:24/GPU-->12/GPU。图像尺寸:608-->768,变化范围为: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768]。
(4)IoU Aware Branch
在PP-YOLO中也用到了IOU Aware loss,不过它是以soft weight的格式来用的。在PP-YOLOv2中,则是以soft label的格式来使用:
(1)
其中,t为anchor和GT直接的IoU,p是原始的Iou aware branch的输出,σ(·) 是sigmoid函数。需要注意的是,该loss只计算正样本。
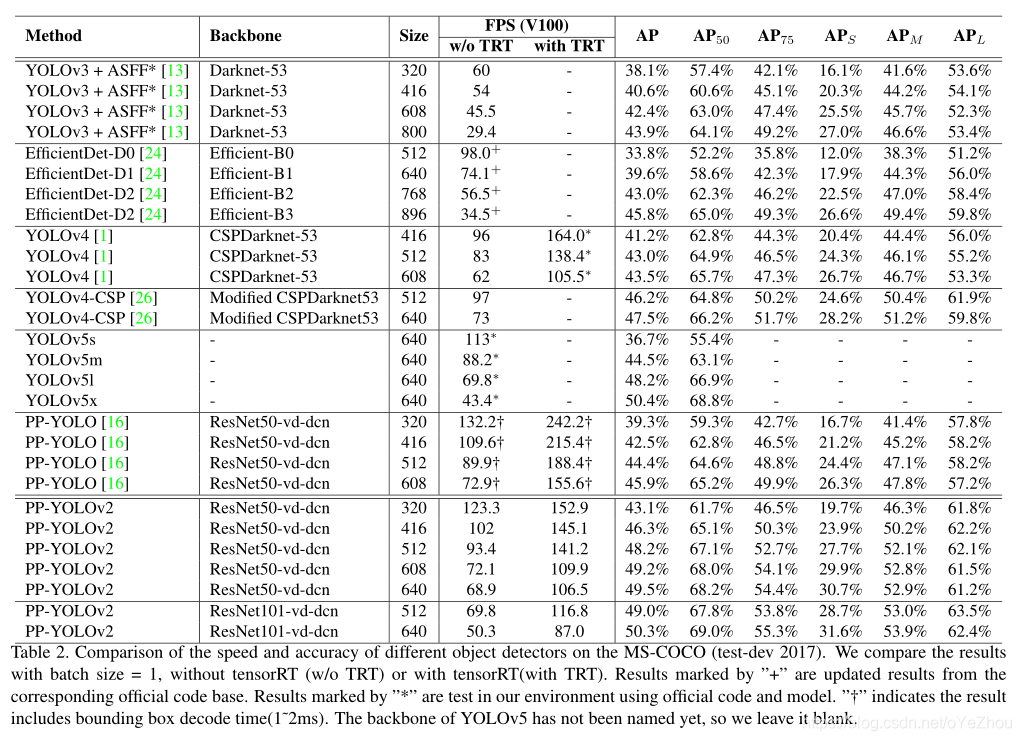
3、实验结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











