







系列文章目录
文章目录
前言
在学习pandas的过程中,通过w3school的pandas入门资料,在这里记录一下学过的函数笔记。原网站:Pandas Tutorial

在学习前,默认:
import pandas as pd
一、Pandas作用
给一些数据,可以实现以下的功能:
1、计算两列或者很多列之间是否存在相关性
2、平均值是多少?最大值,最小值是多少?
3、清理数据:删除不相关的行,删除NULL或空值
二、数据结构
2.1 Series
1、定义:一个一维的数据结构,可以包含不同类型的数据。【类似table中的一列】
2、创建Series:
myvar = pd.Series([1, 7, 2])
3、获取Series的标签:在默认情况下,Series的每一行会存在一个索引,从0开始。通过索引可以获取Series中相应位置的内容。
myvar[2]
4、创建标签:在pd.Series中存在一个参数index,传递一个列表,可以将列表中的内容和Series中的数据匹配,从而列表作为Series作为索引查询数据。
a=[1,2,3]
pd.Series(a, index = ["x", "y", "z"])
#可以通过新建的索引搜索Series
a["y"]
2.2 DataFrame
1、定义:DataFrame是一个二维的数据结构,类似于一个二维数组,或者一个包括了很多行和很多列的表。
2、创建一个DataFrame:将一个字典数据结构转化为DataFrame
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data)
3、给索引赋值:通过索引可以获取某一行的内容;这里通过pd.DataFrame中的index参数为索引赋值。
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
4、获取具体某(些)行和某(些)列:loc函数
#获取第一行数据:【pandas从第0行开始】
df.loc[1]#返回一个Series对象
#获取第0行和第1行数据
df.loc[[0, 1]]#通过[]实现的获取数据,返回对象为DataFrame
#可以通过索引名称获取某一行的值
df.loc["day2"]
df.loc[["day2","day3"]]
5、从文件中获取DataFrame
#从csv文件中获取数据
df = pd.read_csv('data.csv')
三、读取数据
3.1 读取CSV文件数据
1、CSV文件:CSV文件可以存储大量数据,通过逗号分割数据。
2、读取文件数据:
df = pd.read_csv('data.csv')
【Note:print(df.to_string())可以获取df的全部行和列;如果print(df)那么,当df的数据量很大时,指挥获取到前五行和最后五行】
通过pd.options.display.max_rows可以获取系统最大显示DataFrame的行数。
例如:

说明:在本机系统,通过print(df)最大显示的数据为60行;若df的行数在60行以内,则全部显示,若df的行数超过60行,只显示前5行和后5行。
3.2 读取JSON文件数据
读取JSON文件
df = pd.read_json('data.json')
四、分析数据
1、数据概览data view:通过head()获取DataFrame的头部数据,可以看到DataFrame中的前几行数据,从而对数据表有一个了解;通过tail()获取表的后几行的数据,对表有一个了解。
#获取前十行数据
df.head(10)
df.head()#默认获取前五行
#获取后五行数据
df.tail()
2、info()函数:提供数据集的更多信息
df.info()
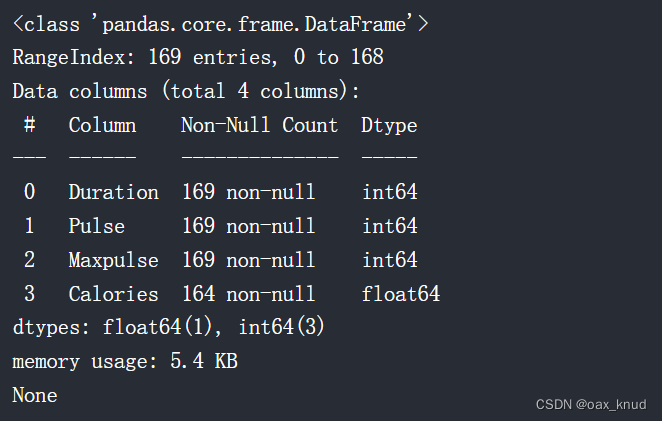
通过上方info显示,可以看出df数据表共有169行,4列。并且获取了每列的数据类型。
其中在Calories列中存在5个空值。
五、清洗数据
清洗数据意味着将脏数据从数据集中消除。
脏数据:空值;错误格式的数据;错误的数据;重复数据。
样例数据表如下:

The data set contains some empty cells (“Date” in row 22, and “Calories” in row 18 and 28).
The data set contains wrong format (“Date” in row 26).
The data set contains wrong data (“Duration” in row 7).
The data set contains duplicates (row 11 and 12).
5.1 空值
空值可能会在数据分析时提供一个错误的结果
5.1.1 删除包含空值的行
一种方法是删除包含空值的行,适用场景是在数据量非常大的时候,空值数目较少的时候。这时候删除空值所在的行不会对结果早场特别大。通过dropna实现
newdf=df.dropna()#dropna()不会修改原始的df
df.dropna(inplace = True)#增加inplace参数,可以修改原始df
5.1.2 填充空值
另一种方法是在空值种插入一个新的值。这种放啊不需要删除包含空缺值的行。通过fillna实现。
df.fillna(130, inplace = True)#将所有空缺值填充为130
df["Calories"].fillna(130, inplace = True)#将Calories列种的空缺值填充为130
常见的填充空缺值的方法是:计算平均数mean,中位数median,众数mode 填充
Pandas uses the mean() median() and mode() methods to calculate the respective values for a specified column
x = df["Calories"].mean()
df["Calories"].fillna(x, inplace = True)
x = df["Calories"].mode()
df["Calories"].fillna(x, inplace = True)
x = df["Calories"].median()
df["Calories"].fillna(x, inplace = True)
5.2 错误格式的数据
通常错误格式的数据有两种方法修改:删除错误数据的那一行;修改错误格式的数据为正确格式。
在上述样例中,存在日期格式错误;可以通过to_datetime()修正日期格式。
df['Date'] = pd.to_datetime(df['Date'])
5.3 错误的数据
错误的数据不是空值也不是格式错误,他就是一个错误的数据。【例如:199写成了1.99】
上述的样例中:duration列的数据在30-60之间,但是在row 7出现了450,虽然他可能不是错误,但是结合语境分析,一个人在450分钟内没有解决出来问题,是不正常的。
修改方法:
5.3.1修改为可能正确的数据
一种方法是通过某些数据对错误的数据进行修改。在样例中,450是错误的,但是猜测可能为45,因此将45替代450.
df.loc[7, 'Duration'] = 45
这种方法适用的场合在小数据集中。在小数据集中可以一个一个去修改替换错误的值。但是如果大一点的数据集,是不适用的。
5.3.2 设置正确的数据上下界
替换错误的值,在大数据集中通常采用一定的规则进行实现。例如可以设置一些合法数据的范围,超出范围的数据被替换为边界值。
for x in df.index:
if df.loc[x, "Duration"] > 120:
df.loc[x, "Duration"] = 120
5.3.3 删除错误数据所在的行
另一种方法是删除错误数据所在的行。
这种方法不需要寻找正确的值去替换错误的值,适用于不需要适用错误的数据进行分析。
for x in df.index:
if df.loc[x, "Duration"] > 120:
df.drop(x, inplace = True)
5.4 重复的数据
对于重复的数据,我们需要对其进行删除。
5.4.1 查找重复数据
duplicated函数返回一个和df相同行数的True和False Series序列表示是否为重复数据
#结果返回一个和df相同行数的True和False Series序列
df.duplicated()
5.4.2 删除重复数据
drop_duplicates():删除重复数据
df.drop_duplicates(inplace = True)
六、数据相关性
通过corr()方法计算数据集中每一列的相关性。【corr方法会自动忽略非数值的列】
df.corr()
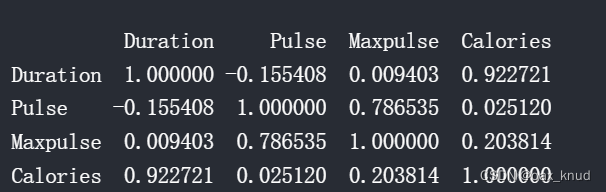
【结果分析】
corr方法的返回值是一个表,包含了一些数据来表示每两列之间的相关性。
数据的范围咋子-1到1之间。
- 相关性为1:表示这两列具有很强的正相关性。一列数据增加,另一列也会增加
- 相关性为0.9:表示这两列具有较强的正相关性,一列数据增加,另一列可能会增加
- 相关性为-0.9:表示这两列具有较强的负相关性,一列数据增加,另一列可能会减小
- 相关性为0.2:0白哦是这两列相关性很弱,一列增加可能不会影响到另外一列。
什么是具有良好的相关性?取决于使用场合。但是w3school教程认为,0.6就是一个很安全的表示良好相关性的值。
- 很好的相关性: "Duration"和 "Duration"之间的相关性为1,因此,这两列之间相关性特别强。
- 较好的相关性:"Duration"和"Calories"相关性为0.922721,具有较好的相关性。可以认为,工作时间越长,消耗的卡路里越多;如果消耗的卡路里多,那么你可能工作时间很长。
- 没有相关性:“Duration” and “Maxpulse” 的相关性为0.009403,这意味着我们不能仅通过观察输出的持续时间来预测最大脉冲,反之亦然
七、数据可视化
数据可视化部分和matplotlib相似,可以参考matplotlib可视化:基础绘图函数使用【函数功能+案例代码】
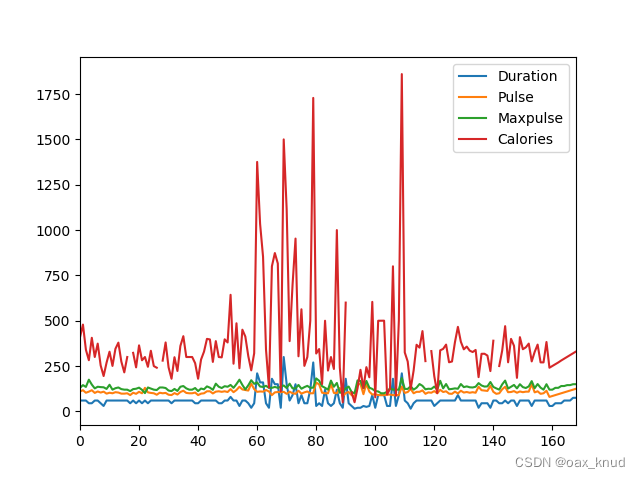
df = pd.read_csv('data.csv')
df.plot()
plt.show()
df = pd.read_csv('data.csv')
df.plot(kind = 'scatter', x = 'Duration', y = 'Calories')
plt.show()
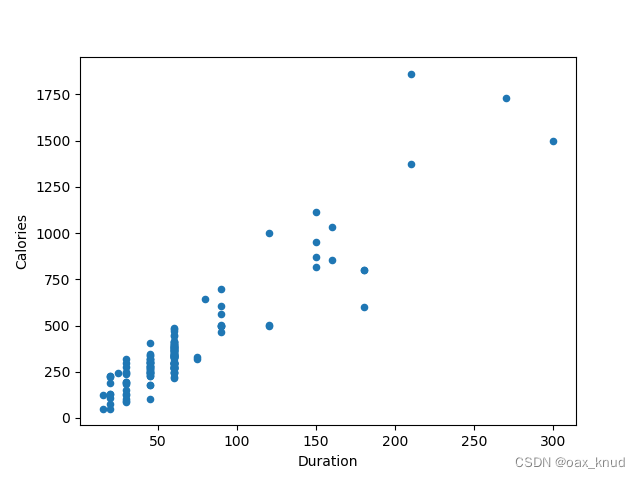
In the previous example, we learned that the correlation between “Duration” and “Calories” was 0.922721, and we conluded with the fact that higher duration means more calories burned.By looking at the scatterplot, I will agree.
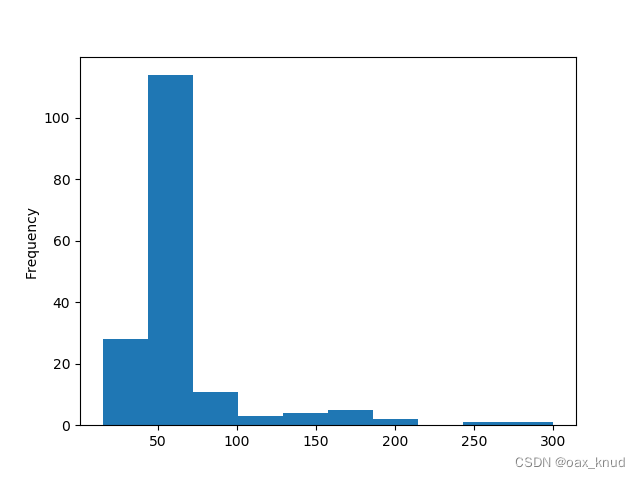
直方图只是用一列数据进行绘制,通常是拥挤每一个区间内数据的频率。
e.g. how many workouts lasted between 50 and 60 minutes?
df["Duration"].plot(kind = 'hist')

















 1016
1016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











